 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSyNeT: Synthetic Negatives for Traversability Learning
Feb 03, 2026Reliable traversability estimation is crucial for autonomous robots to navigate complex outdoor environments safely. Existing self-supervised learning frameworks primarily rely on positive and unlabeled data; however, the lack of explicit negative data remains a critical limitation, hindering the model's ability to accurately identify diverse non-traversable regions. To address this issue, we introduce a method to explicitly construct synthetic negatives, representing plausible but non-traversable, and integrate them into vision-based traversability learning. Our approach is formulated as a training strategy that can be seamlessly integrated into both Positive-Unlabeled (PU) and Positive-Negative (PN) frameworks without modifying inference architectures. Complementing standard pixel-wise metrics, we introduce an object-centric FPR evaluation approach that analyzes predictions in regions where synthetic negatives are inserted. This evaluation provides an indirect measure of the model's ability to consistently identify non-traversable regions without additional manual labeling. Extensive experiments on both public and self-collected datasets demonstrate that our approach significantly enhances robustness and generalization across diverse environments. The source code and demonstration videos will be publicly available.
Unifying Deep Predicate Invention with Pre-trained Foundation Models
Dec 19, 2025Long-horizon robotic tasks are hard due to continuous state-action spaces and sparse feedback. Symbolic world models help by decomposing tasks into discrete predicates that capture object properties and relations. Existing methods learn predicates either top-down, by prompting foundation models without data grounding, or bottom-up, from demonstrations without high-level priors. We introduce UniPred, a bilevel learning framework that unifies both. UniPred uses large language models (LLMs) to propose predicate effect distributions that supervise neural predicate learning from low-level data, while learned feedback iteratively refines the LLM hypotheses. Leveraging strong visual foundation model features, UniPred learns robust predicate classifiers in cluttered scenes. We further propose a predicate evaluation method that supports symbolic models beyond STRIPS assumptions. Across five simulated and one real-robot domains, UniPred achieves 2-4 times higher success rates than top-down methods and 3-4 times faster learning than bottom-up approaches, advancing scalable and flexible symbolic world modeling for robotics.
Any4D: Unified Feed-Forward Metric 4D Reconstruction
Dec 11, 2025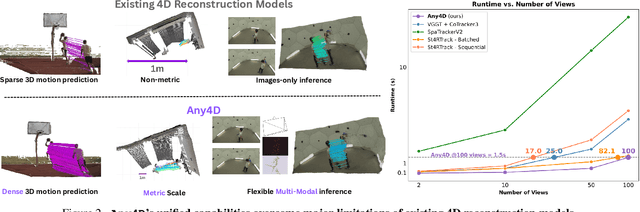
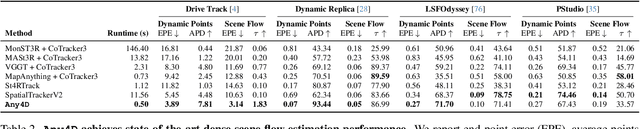
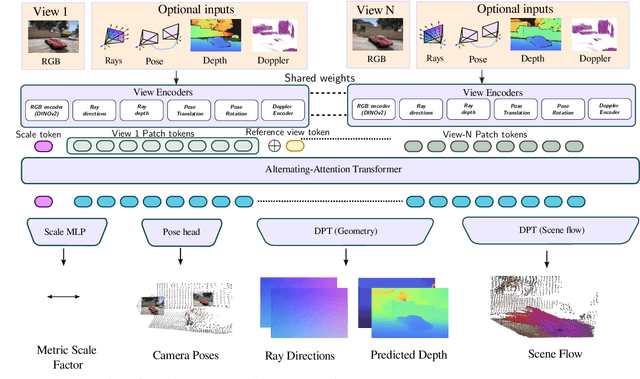
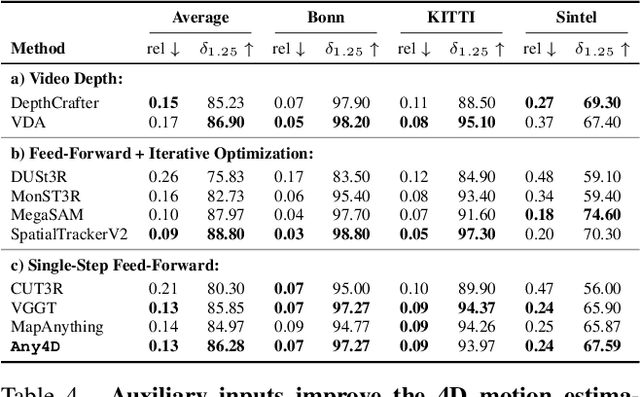
We present Any4D, a scalable multi-view transformer for metric-scale, dense feed-forward 4D reconstruction. Any4D directly generates per-pixel motion and geometry predictions for N frames, in contrast to prior work that typically focuses on either 2-view dense scene flow or sparse 3D point tracking. Moreover, unlike other recent methods for 4D reconstruction from monocular RGB videos, Any4D can process additional modalities and sensors such as RGB-D frames, IMU-based egomotion, and Radar Doppler measurements, when available. One of the key innovations that allows for such a flexible framework is a modular representation of a 4D scene; specifically, per-view 4D predictions are encoded using a variety of egocentric factors (depthmaps and camera intrinsics) represented in local camera coordinates, and allocentric factors (camera extrinsics and scene flow) represented in global world coordinates. We achieve superior performance across diverse setups - both in terms of accuracy (2-3X lower error) and compute efficiency (15X faster), opening avenues for multiple downstream applications.
Co-Me: Confidence-Guided Token Merging for Visual Geometric Transformers
Nov 18, 2025We propose Confidence-Guided Token Merging (Co-Me), an acceleration mechanism for visual geometric transformers without retraining or finetuning the base model. Co-Me distilled a light-weight confidence predictor to rank tokens by uncertainty and selectively merge low-confidence ones, effectively reducing computation while maintaining spatial coverage. Compared to similarity-based merging or pruning, the confidence signal in Co-Me reliably indicates regions emphasized by the transformer, enabling substantial acceleration without degrading performance. Co-Me applies seamlessly to various multi-view and streaming visual geometric transformers, achieving speedups that scale with sequence length. When applied to VGGT and MapAnything, Co-Me achieves up to $11.3\times$ and $7.2\times$ speedup, making visual geometric transformers practical for real-time 3D perception and reconstruction.
AutoODD: Agentic Audits via Bayesian Red Teaming in Black-Box Models
Sep 10, 2025Specialized machine learning models, regardless of architecture and training, are susceptible to failures in deployment. With their increasing use in high risk situations, the ability to audit these models by determining their operational design domain (ODD) is crucial in ensuring safety and compliance. However, given the high-dimensional input spaces, this process often requires significant human resources and domain expertise. To alleviate this, we introduce \coolname, an LLM-Agent centric framework for automated generation of semantically relevant test cases to search for failure modes in specialized black-box models. By leveraging LLM-Agents as tool orchestrators, we aim to fit a uncertainty-aware failure distribution model on a learned text-embedding manifold by projecting the high-dimension input space to low-dimension text-embedding latent space. The LLM-Agent is tasked with iteratively building the failure landscape by leveraging tools for generating test-cases to probe the model-under-test (MUT) and recording the response. The agent also guides the search using tools to probe uncertainty estimate on the low dimensional manifold. We demonstrate this process in a simple case using models trained with missing digits on the MNIST dataset and in the real world setting of vision-based intruder detection for aerial vehicles.
UFM: A Simple Path towards Unified Dense Correspondence with Flow
Jun 10, 2025Dense image correspondence is central to many applications, such as visual odometry, 3D reconstruction, object association, and re-identification. Historically, dense correspondence has been tackled separately for wide-baseline scenarios and optical flow estimation, despite the common goal of matching content between two images. In this paper, we develop a Unified Flow & Matching model (UFM), which is trained on unified data for pixels that are co-visible in both source and target images. UFM uses a simple, generic transformer architecture that directly regresses the (u,v) flow. It is easier to train and more accurate for large flows compared to the typical coarse-to-fine cost volumes in prior work. UFM is 28% more accurate than state-of-the-art flow methods (Unimatch), while also having 62% less error and 6.7x faster than dense wide-baseline matchers (RoMa). UFM is the first to demonstrate that unified training can outperform specialized approaches across both domains. This result enables fast, general-purpose correspondence and opens new directions for multi-modal, long-range, and real-time correspondence tasks.
TartanGround: A Large-Scale Dataset for Ground Robot Perception and Navigation
May 15, 2025We present TartanGround, a large-scale, multi-modal dataset to advance the perception and autonomy of ground robots operating in diverse environments. This dataset, collected in various photorealistic simulation environments includes multiple RGB stereo cameras for 360-degree coverage, along with depth, optical flow, stereo disparity, LiDAR point clouds, ground truth poses, semantic segmented images, and occupancy maps with semantic labels. Data is collected using an integrated automatic pipeline, which generates trajectories mimicking the motion patterns of various ground robot platforms, including wheeled and legged robots. We collect 910 trajectories across 70 environments, resulting in 1.5 million samples. Evaluations on occupancy prediction and SLAM tasks reveal that state-of-the-art methods trained on existing datasets struggle to generalize across diverse scenes. TartanGround can serve as a testbed for training and evaluation of a broad range of learning-based tasks, including occupancy prediction, SLAM, neural scene representation, perception-based navigation, and more, enabling advancements in robotic perception and autonomy towards achieving robust models generalizable to more diverse scenarios. The dataset and codebase for data collection will be made publicly available upon acceptance. Webpage: https://tartanair.org/tartanground
BETTY Dataset: A Multi-modal Dataset for Full-Stack Autonomy
May 12, 2025We present the BETTY dataset, a large-scale, multi-modal dataset collected on several autonomous racing vehicles, targeting supervised and self-supervised state estimation, dynamics modeling, motion forecasting, perception, and more. Existing large-scale datasets, especially autonomous vehicle datasets, focus primarily on supervised perception, planning, and motion forecasting tasks. Our work enables multi-modal, data-driven methods by including all sensor inputs and the outputs from the software stack, along with semantic metadata and ground truth information. The dataset encompasses 4 years of data, currently comprising over 13 hours and 32TB, collected on autonomous racing vehicle platforms. This data spans 6 diverse racing environments, including high-speed oval courses, for single and multi-agent algorithm evaluation in feature-sparse scenarios, as well as high-speed road courses with high longitudinal and lateral accelerations and tight, GPS-denied environments. It captures highly dynamic states, such as 63 m/s crashes, loss of tire traction, and operation at the limit of stability. By offering a large breadth of cross-modal and dynamic data, the BETTY dataset enables the training and testing of full autonomy stack pipelines, pushing the performance of all algorithms to the limits. The current dataset is available at https://pitt-mit-iac.github.io/betty-dataset/.
Demonstrating ViSafe: Vision-enabled Safety for High-speed Detect and Avoid
May 08, 2025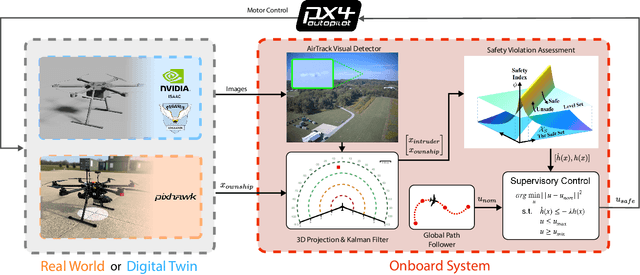
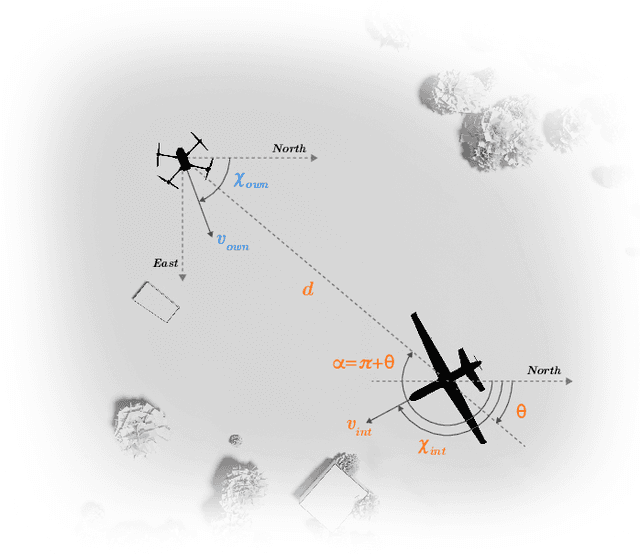

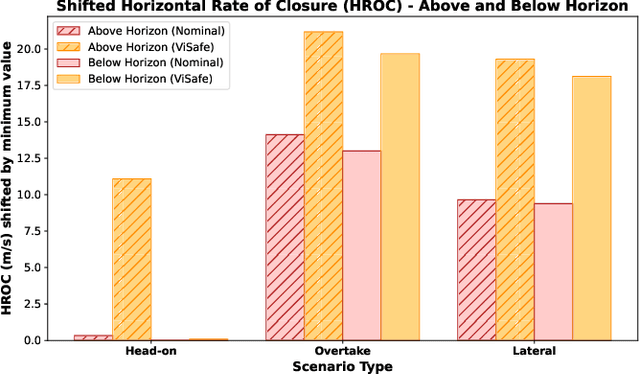
Assured safe-separation is essential for achieving seamless high-density operation of airborne vehicles in a shared airspace. To equip resource-constrained aerial systems with this safety-critical capability, we present ViSafe, a high-speed vision-only airborne collision avoidance system. ViSafe offers a full-stack solution to the Detect and Avoid (DAA) problem by tightly integrating a learning-based edge-AI framework with a custom multi-camera hardware prototype designed under SWaP-C constraints. By leveraging perceptual input-focused control barrier functions (CBF) to design, encode, and enforce safety thresholds, ViSafe can provide provably safe runtime guarantees for self-separation in high-speed aerial operations. We evaluate ViSafe's performance through an extensive test campaign involving both simulated digital twins and real-world flight scenarios. By independently varying agent types, closure rates, interaction geometries, and environmental conditions (e.g., weather and lighting), we demonstrate that ViSafe consistently ensures self-separation across diverse scenarios. In first-of-its-kind real-world high-speed collision avoidance tests with closure rates reaching 144 km/h, ViSafe sets a new benchmark for vision-only autonomous collision avoidance, establishing a new standard for safety in high-speed aerial navigation.
Flying Hand: End-Effector-Centric Framework for Versatile Aerial Manipulation Teleoperation and Policy Learning
Apr 14, 2025Aerial manipulation has recently attracted increasing interest from both industry and academia. Previous approaches have demonstrated success in various specific tasks. However, their hardware design and control frameworks are often tightly coupled with task specifications, limiting the development of cross-task and cross-platform algorithms. Inspired by the success of robot learning in tabletop manipulation, we propose a unified aerial manipulation framework with an end-effector-centric interface that decouples high-level platform-agnostic decision-making from task-agnostic low-level control. Our framework consists of a fully-actuated hexarotor with a 4-DoF robotic arm, an end-effector-centric whole-body model predictive controller, and a high-level policy. The high-precision end-effector controller enables efficient and intuitive aerial teleoperation for versatile tasks and facilitates the development of imitation learning policies. Real-world experiments show that the proposed framework significantly improves end-effector tracking accuracy, and can handle multiple aerial teleoperation and imitation learning tasks, including writing, peg-in-hole, pick and place, changing light bulbs, etc. We believe the proposed framework provides one way to standardize and unify aerial manipulation into the general manipulation community and to advance the field. Project website: https://lecar-lab.github.io/flying_hand/.