 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoseStreamer: A Multi-modal Framework for 3D Tracking of Unseen Moving Objects
Jan 02, 2026Six degree of freedom (6DoF) pose estimation for novel objects is a critical task in computer vision, yet it faces significant challenges in high-speed and low-light scenarios where standard RGB cameras suffer from motion blur. While event cameras offer a promising solution due to their high temporal resolution, current 6DoF pose estimation methods typically yield suboptimal performance in high-speed object moving scenarios. To address this gap, we propose PoseStreamer, a robust multi-modal 6DoF pose estimation framework designed specifically on high-speed moving scenarios. Our approach integrates three core components: an Adaptive Pose Memory Queue that utilizes historical orientation cues for temporal consistency, an Object-centric 2D Tracker that provides strong 2D priors to boost 3D center recall, and a Ray Pose Filter for geometric refinement along camera rays. Furthermore, we introduce MoCapCube6D, a novel multi-modal dataset constructed to benchmark performance under rapid motion. Extensive experiments demonstrate that PoseStreamer not only achieves superior accuracy in high-speed moving scenarios, but also exhibits strong generalizability as a template-free framework for unseen moving objects.
PoseStreamer: A Multi-modal Framework for 6DoF Pose Estimation of Unseen Moving Objects
Dec 31, 2025Six degree of freedom (6DoF) pose estimation for novel objects is a critical task in computer vision, yet it faces significant challenges in high-speed and low-light scenarios where standard RGB cameras suffer from motion blur. While event cameras offer a promising solution due to their high temporal resolution, current 6DoF pose estimation methods typically yield suboptimal performance in high-speed object moving scenarios. To address this gap, we propose PoseStreamer, a robust multi-modal 6DoF pose estimation framework designed specifically on high-speed moving scenarios. Our approach integrates three core components: an Adaptive Pose Memory Queue that utilizes historical orientation cues for temporal consistency, an Object-centric 2D Tracker that provides strong 2D priors to boost 3D center recall, and a Ray Pose Filter for geometric refinement along camera rays. Furthermore, we introduce MoCapCube6D, a novel multi-modal dataset constructed to benchmark performance under rapid motion. Extensive experiments demonstrate that PoseStreamer not only achieves superior accuracy in high-speed moving scenarios, but also exhibits strong generalizability as a template-free framework for unseen moving objects.
Artificial Intelligence-Based Multiscale Temporal Modeling for Anomaly Detection in Cloud Services
Aug 20, 2025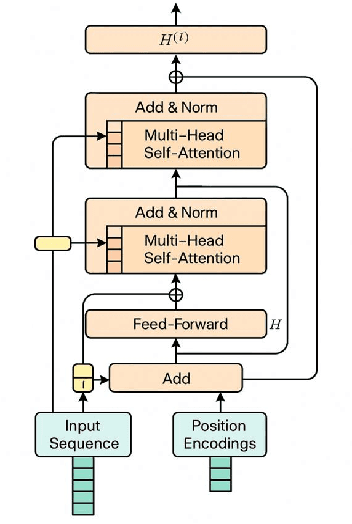
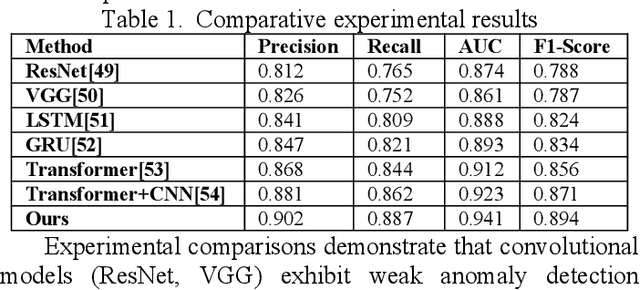
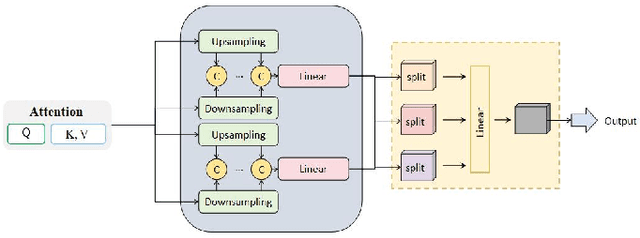
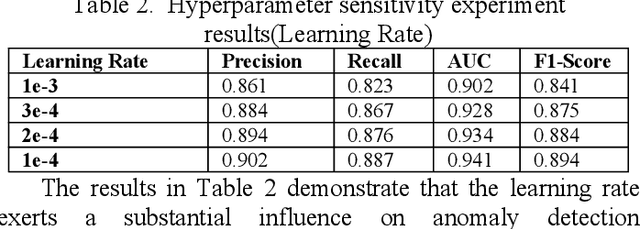
This study proposes an anomaly detection method based on the Transformer architecture with integrated multiscale feature perception, aiming to address the limitations of temporal modeling and scale-aware feature representation in cloud service environments. The method first employs an improved Transformer module to perform temporal modeling on high-dimensional monitoring data, using a self-attention mechanism to capture long-range dependencies and contextual semantics. Then, a multiscale feature construction path is introduced to extract temporal features at different granularities through downsampling and parallel encoding. An attention-weighted fusion module is designed to dynamically adjust the contribution of each scale to the final decision, enhancing the model's robustness in anomaly pattern modeling. In the input modeling stage, standardized multidimensional time series are constructed, covering core signals such as CPU utilization, memory usage, and task scheduling states, while positional encoding is used to strengthen the model's temporal awareness. A systematic experimental setup is designed to evaluate performance, including comparative experiments and hyperparameter sensitivity analysis, focusing on the impact of optimizers, learning rates, anomaly ratios, and noise levels. Experimental results show that the proposed method outperforms mainstream baseline models in key metrics, including precision, recall, AUC, and F1-score, and maintains strong stability and detection performance under various perturbation conditions, demonstrating its superior capability in complex cloud environments.
Rhetorical Text-to-Image Generation via Two-layer Diffusion Policy Optimization
May 28, 2025Generating images from rhetorical languages remains a critical challenge for text-to-image models. Even state-of-the-art (SOTA) multimodal large language models (MLLM) fail to generate images based on the hidden meaning inherent in rhetorical language--despite such content being readily mappable to visual representations by humans. A key limitation is that current models emphasize object-level word embedding alignment, causing metaphorical expressions to steer image generation towards their literal visuals and overlook the intended semantic meaning. To address this, we propose Rhet2Pix, a framework that formulates rhetorical text-to-image generation as a multi-step policy optimization problem, incorporating a two-layer MDP diffusion module. In the outer layer, Rhet2Pix converts the input prompt into incrementally elaborated sub-sentences and executes corresponding image-generation actions, constructing semantically richer visuals. In the inner layer, Rhet2Pix mitigates reward sparsity during image generation by discounting the final reward and optimizing every adjacent action pair along the diffusion denoising trajectory. Extensive experiments demonstrate the effectiveness of Rhet2Pix in rhetorical text-to-image generation. Our model outperforms SOTA MLLMs such as GPT-4o, Grok-3 and leading academic baselines across both qualitative and quantitative evaluations. The code and dataset used in this work are publicly available.
Chi-Square Wavelet Graph Neural Networks for Heterogeneous Graph Anomaly Detection
May 25, 2025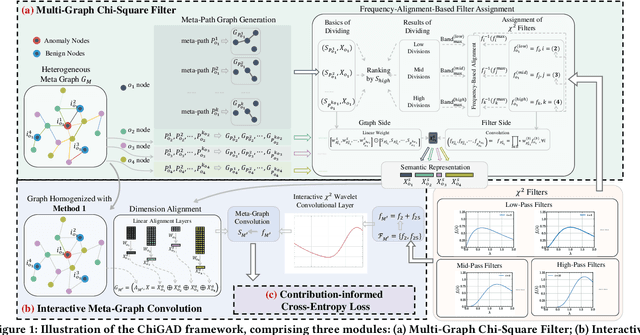
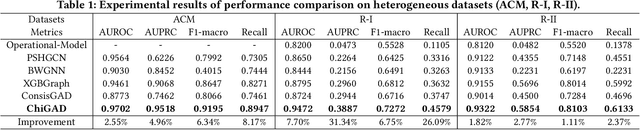
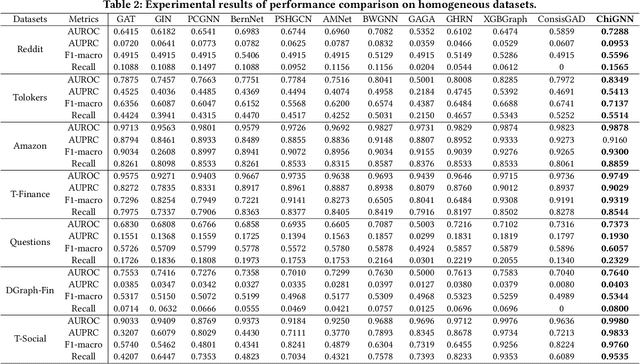
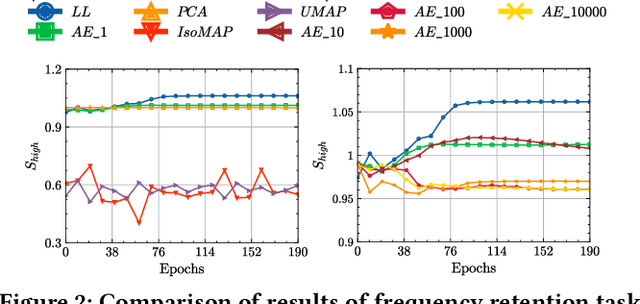
Graph Anomaly Detection (GAD) in heterogeneous networks presents unique challenges due to node and edge heterogeneity. Existing Graph Neural Network (GNN) methods primarily focus on homogeneous GAD and thus fail to address three key issues: (C1) Capturing abnormal signal and rich semantics across diverse meta-paths; (C2) Retaining high-frequency content in HIN dimension alignment; and (C3) Learning effectively from difficult anomaly samples with class imbalance. To overcome these, we propose ChiGAD, a spectral GNN framework based on a novel Chi-Square filter, inspired by the wavelet effectiveness in diverse domains. Specifically, ChiGAD consists of: (1) Multi-Graph Chi-Square Filter, which captures anomalous information via applying dedicated Chi-Square filters to each meta-path graph; (2) Interactive Meta-Graph Convolution, which aligns features while preserving high-frequency information and incorporates heterogeneous messages by a unified Chi-Square Filter; and (3) Contribution-Informed Cross-Entropy Loss, which prioritizes difficult anomalies to address class imbalance. Extensive experiments on public and industrial datasets show that ChiGAD outperforms state-of-the-art models on multiple metrics. Additionally, its homogeneous variant, ChiGNN, excels on seven GAD datasets, validating the effectiveness of Chi-Square filters. Our code is available at https://github.com/HsipingLi/ChiGAD.
REVAL: A Comprehension Evaluation on Reliability and Values of Large Vision-Language Models
Mar 20, 2025



The rapid evolution of Large Vision-Language Models (LVLMs) has highlighted the necessity for comprehensive evaluation frameworks that assess these models across diverse dimensions. While existing benchmarks focus on specific aspects such as perceptual abilities, cognitive capabilities, and safety against adversarial attacks, they often lack the breadth and depth required to provide a holistic understanding of LVLMs' strengths and limitations. To address this gap, we introduce REVAL, a comprehensive benchmark designed to evaluate the \textbf{RE}liability and \textbf{VAL}ue of LVLMs. REVAL encompasses over 144K image-text Visual Question Answering (VQA) samples, structured into two primary sections: Reliability, which assesses truthfulness (\eg, perceptual accuracy and hallucination tendencies) and robustness (\eg, resilience to adversarial attacks, typographic attacks, and image corruption), and Values, which evaluates ethical concerns (\eg, bias and moral understanding), safety issues (\eg, toxicity and jailbreak vulnerabilities), and privacy problems (\eg, privacy awareness and privacy leakage). We evaluate 26 models, including mainstream open-source LVLMs and prominent closed-source models like GPT-4o and Gemini-1.5-Pro. Our findings reveal that while current LVLMs excel in perceptual tasks and toxicity avoidance, they exhibit significant vulnerabilities in adversarial scenarios, privacy preservation, and ethical reasoning. These insights underscore critical areas for future improvements, guiding the development of more secure, reliable, and ethically aligned LVLMs. REVAL provides a robust framework for researchers to systematically assess and compare LVLMs, fostering advancements in the field.
SpaceGNN: Multi-Space Graph Neural Network for Node Anomaly Detection with Extremely Limited Labels
Feb 05, 2025



Node Anomaly Detection (NAD) has gained significant attention in the deep learning community due to its diverse applications in real-world scenarios. Existing NAD methods primarily embed graphs within a single Euclidean space, while overlooking the potential of non-Euclidean spaces. Besides, to address the prevalent issue of limited supervision in real NAD tasks, previous methods tend to leverage synthetic data to collect auxiliary information, which is not an effective solution as shown in our experiments. To overcome these challenges, we introduce a novel SpaceGNN model designed for NAD tasks with extremely limited labels. Specifically, we provide deeper insights into a task-relevant framework by empirically analyzing the benefits of different spaces for node representations, based on which, we design a Learnable Space Projection function that effectively encodes nodes into suitable spaces. Besides, we introduce the concept of weighted homogeneity, which we empirically and theoretically validate as an effective coefficient during information propagation. This concept inspires the design of the Distance Aware Propagation module. Furthermore, we propose the Multiple Space Ensemble module, which extracts comprehensive information for NAD under conditions of extremely limited supervision. Our findings indicate that this module is more beneficial than data augmentation techniques for NAD. Extensive experiments conducted on 9 real datasets confirm the superiority of SpaceGNN, which outperforms the best rival by an average of 8.55% in AUC and 4.31% in F1 scores. Our code is available at https://github.com/xydong127/SpaceGNN.
Scalable Benchmarking and Robust Learning for Noise-Free Ego-Motion and 3D Reconstruction from Noisy Video
Jan 24, 2025We aim to redefine robust ego-motion estimation and photorealistic 3D reconstruction by addressing a critical limitation: the reliance on noise-free data in existing models. While such sanitized conditions simplify evaluation, they fail to capture the unpredictable, noisy complexities of real-world environments. Dynamic motion, sensor imperfections, and synchronization perturbations lead to sharp performance declines when these models are deployed in practice, revealing an urgent need for frameworks that embrace and excel under real-world noise. To bridge this gap, we tackle three core challenges: scalable data generation, comprehensive benchmarking, and model robustness enhancement. First, we introduce a scalable noisy data synthesis pipeline that generates diverse datasets simulating complex motion, sensor imperfections, and synchronization errors. Second, we leverage this pipeline to create Robust-Ego3D, a benchmark rigorously designed to expose noise-induced performance degradation, highlighting the limitations of current learning-based methods in ego-motion accuracy and 3D reconstruction quality. Third, we propose Correspondence-guided Gaussian Splatting (CorrGS), a novel test-time adaptation method that progressively refines an internal clean 3D representation by aligning noisy observations with rendered RGB-D frames from clean 3D map, enhancing geometric alignment and appearance restoration through visual correspondence. Extensive experiments on synthetic and real-world data demonstrate that CorrGS consistently outperforms prior state-of-the-art methods, particularly in scenarios involving rapid motion and dynamic illumination.
From Perfect to Noisy World Simulation: Customizable Embodied Multi-modal Perturbations for SLAM Robustness Benchmarking
Jun 24, 2024



Embodied agents require robust navigation systems to operate in unstructured environments, making the robustness of Simultaneous Localization and Mapping (SLAM) models critical to embodied agent autonomy. While real-world datasets are invaluable, simulation-based benchmarks offer a scalable approach for robustness evaluations. However, the creation of a challenging and controllable noisy world with diverse perturbations remains under-explored. To this end, we propose a novel, customizable pipeline for noisy data synthesis, aimed at assessing the resilience of multi-modal SLAM models against various perturbations. The pipeline comprises a comprehensive taxonomy of sensor and motion perturbations for embodied multi-modal (specifically RGB-D) sensing, categorized by their sources and propagation order, allowing for procedural composition. We also provide a toolbox for synthesizing these perturbations, enabling the transformation of clean environments into challenging noisy simulations. Utilizing the pipeline, we instantiate the large-scale Noisy-Replica benchmark, which includes diverse perturbation types, to evaluate the risk tolerance of existing advanced RGB-D SLAM models. Our extensive analysis uncovers the susceptibilities of both neural (NeRF and Gaussian Splatting -based) and non-neural SLAM models to disturbances, despite their demonstrated accuracy in standard benchmarks. Our code is publicly available at https://github.com/Xiaohao-Xu/SLAM-under-Perturbation.
VLBiasBench: A Comprehensive Benchmark for Evaluating Bias in Large Vision-Language Model
Jun 20, 2024



The emergence of Large Vision-Language Models (LVLMs) marks significant strides towards achieving general artificial intelligence. However, these advancements are tempered by the outputs that often reflect biases, a concern not yet extensively investigated. Existing benchmarks are not sufficiently comprehensive in evaluating biases due to their limited data scale, single questioning format and narrow sources of bias. To address this problem, we introduce VLBiasBench, a benchmark aimed at evaluating biases in LVLMs comprehensively. In VLBiasBench, we construct a dataset encompassing nine distinct categories of social biases, including age, disability status, gender, nationality, physical appearance, race, religion, profession, social economic status and two intersectional bias categories (race x gender, and race x social economic status). To create a large-scale dataset, we use Stable Diffusion XL model to generate 46,848 high-quality images, which are combined with different questions to form 128,342 samples. These questions are categorized into open and close ended types, fully considering the sources of bias and comprehensively evaluating the biases of LVLM from multiple perspectives. We subsequently conduct extensive evaluations on 15 open-source models as well as one advanced closed-source model, providing some new insights into the biases revealing from these models. Our benchmark is available at https://github.com/Xiangkui-Cao/VLBiasBench.