 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing Like Radiologists: Context- and Gaze-Guided Vision-Language Pretraining for Chest X-rays
Mar 27, 2026Despite recent advances in medical vision-language pretraining, existing models still struggle to capture the diagnostic workflow: radiographs are typically treated as context-agnostic images, while radiologists' gaze -- a crucial cue for visual reasoning -- remains largely underexplored by existing methods. These limitations hinder the modeling of disease-specific patterns and weaken cross-modal alignment. To bridge this gap, we introduce CoGaze, a Context- and Gaze-guided vision-language pretraining framework for chest X-rays. We first propose a context-infused vision encoder that models how radiologists integrate clinical context -- including patient history, symptoms, and diagnostic intent -- to guide diagnostic reasoning. We then present a multi-level supervision paradigm that (1) enforces intra- and inter-modal semantic alignment through hybrid-positive contrastive learning, (2) injects diagnostic priors via disease-aware cross-modal representation learning, and (3) leverages radiologists' gaze as probabilistic priors to guide attention toward diagnostically salient regions. Extensive experiments demonstrate that CoGaze consistently outperforms state-of-the-art methods across diverse tasks, achieving up to +2.0% CheXbertF1 and +1.2% BLEU2 for free-text and structured report generation, +23.2% AUROC for zero-shot classification, and +12.2% Precision@1 for image-text retrieval. Code is available at https://github.com/mk-runner/CoGaze.
A Vision-and-Knowledge Enhanced Large Language Model for Generalizable Pedestrian Crossing Behavior Inference
Jan 02, 2026Existing paradigms for inferring pedestrian crossing behavior, ranging from statistical models to supervised learning methods, demonstrate limited generalizability and perform inadequately on new sites. Recent advances in Large Language Models (LLMs) offer a shift from numerical pattern fitting to semantic, context-aware behavioral reasoning, yet existing LLM applications lack domain-specific adaptation and visual context. This study introduces Pedestrian Crossing LLM (PedX-LLM), a vision-and-knowledge enhanced framework designed to transform pedestrian crossing inference from site-specific pattern recognition to generalizable behavioral reasoning. By integrating LLaVA-extracted visual features with textual data and transportation domain knowledge, PedX-LLM fine-tunes a LLaMA-2-7B foundation model via Low-Rank Adaptation (LoRA) to infer crossing decisions. PedX-LLM achieves 82.0% balanced accuracy, outperforming the best statistical and supervised learning methods. Results demonstrate that the vision-augmented module contributes a 2.9% performance gain by capturing the built environment and integrating domain knowledge yields an additional 4.1% improvement. To evaluate generalizability across unseen environments, cross-site validation was conducted using site-based partitioning. The zero-shot PedX-LLM configuration achieves 66.9% balanced accuracy on five unseen test sites, outperforming the baseline data-driven methods by at least 18 percentage points. Incorporating just five validation examples via few-shot learning to PedX-LLM further elevates the balanced accuracy to 72.2%. PedX-LLM demonstrates strong generalizability to unseen scenarios, confirming that vision-and-knowledge-enhanced reasoning enables the model to mimic human-like decision logic and overcome the limitations of purely data-driven methods.
PriorRG: Prior-Guided Contrastive Pre-training and Coarse-to-Fine Decoding for Chest X-ray Report Generation
Aug 07, 2025



Chest X-ray report generation aims to reduce radiologists' workload by automatically producing high-quality preliminary reports. A critical yet underexplored aspect of this task is the effective use of patient-specific prior knowledge -- including clinical context (e.g., symptoms, medical history) and the most recent prior image -- which radiologists routinely rely on for diagnostic reasoning. Most existing methods generate reports from single images, neglecting this essential prior information and thus failing to capture diagnostic intent or disease progression. To bridge this gap, we propose PriorRG, a novel chest X-ray report generation framework that emulates real-world clinical workflows via a two-stage training pipeline. In Stage 1, we introduce a prior-guided contrastive pre-training scheme that leverages clinical context to guide spatiotemporal feature extraction, allowing the model to align more closely with the intrinsic spatiotemporal semantics in radiology reports. In Stage 2, we present a prior-aware coarse-to-fine decoding for report generation that progressively integrates patient-specific prior knowledge with the vision encoder's hidden states. This decoding allows the model to align with diagnostic focus and track disease progression, thereby enhancing the clinical accuracy and fluency of the generated reports. Extensive experiments on MIMIC-CXR and MIMIC-ABN datasets demonstrate that PriorRG outperforms state-of-the-art methods, achieving a 3.6% BLEU-4 and 3.8% F1 score improvement on MIMIC-CXR, and a 5.9% BLEU-1 gain on MIMIC-ABN. Code and checkpoints will be released upon acceptance.
Chi-Square Wavelet Graph Neural Networks for Heterogeneous Graph Anomaly Detection
May 25, 2025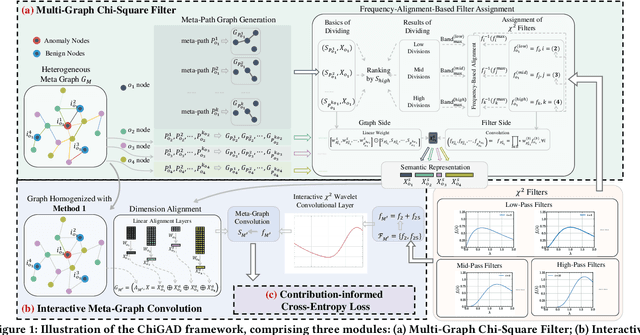
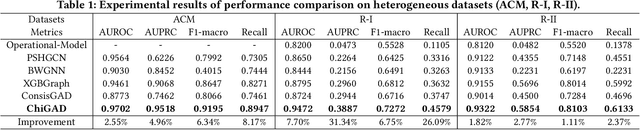
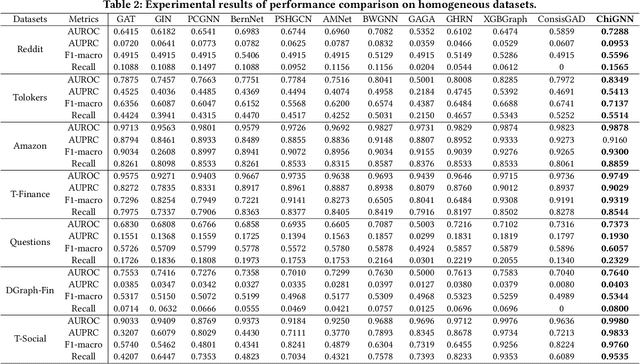
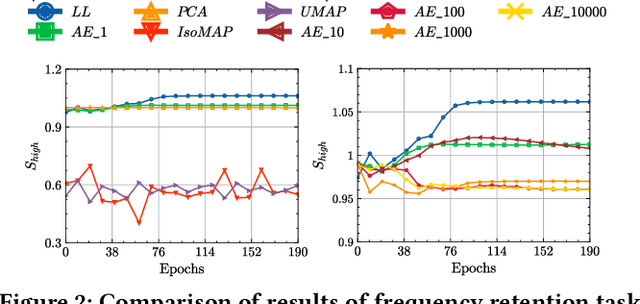
Graph Anomaly Detection (GAD) in heterogeneous networks presents unique challenges due to node and edge heterogeneity. Existing Graph Neural Network (GNN) methods primarily focus on homogeneous GAD and thus fail to address three key issues: (C1) Capturing abnormal signal and rich semantics across diverse meta-paths; (C2) Retaining high-frequency content in HIN dimension alignment; and (C3) Learning effectively from difficult anomaly samples with class imbalance. To overcome these, we propose ChiGAD, a spectral GNN framework based on a novel Chi-Square filter, inspired by the wavelet effectiveness in diverse domains. Specifically, ChiGAD consists of: (1) Multi-Graph Chi-Square Filter, which captures anomalous information via applying dedicated Chi-Square filters to each meta-path graph; (2) Interactive Meta-Graph Convolution, which aligns features while preserving high-frequency information and incorporates heterogeneous messages by a unified Chi-Square Filter; and (3) Contribution-Informed Cross-Entropy Loss, which prioritizes difficult anomalies to address class imbalance. Extensive experiments on public and industrial datasets show that ChiGAD outperforms state-of-the-art models on multiple metrics. Additionally, its homogeneous variant, ChiGNN, excels on seven GAD datasets, validating the effectiveness of Chi-Square filters. Our code is available at https://github.com/HsipingLi/ChiGAD.
FireRedTTS-1S: An Upgraded Streamable Foundation Text-to-Speech System
Mar 26, 2025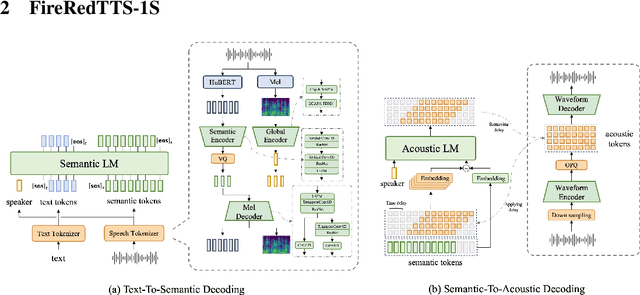
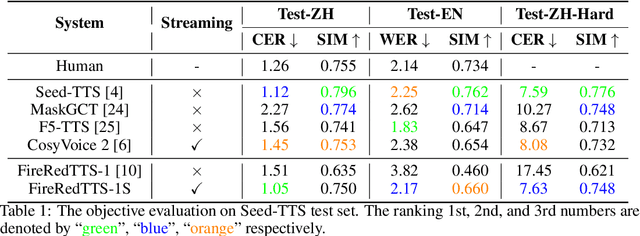
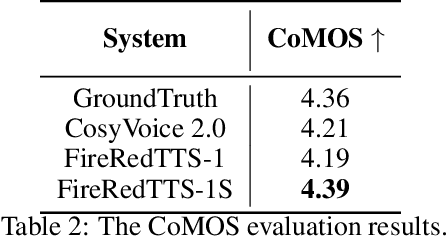
In this work, we propose a high-quality streaming foundation text-to-speech system, FireRedTTS-1S, upgraded from the streamable version of FireRedTTS. FireRedTTS-1S achieves streaming generation via two steps: text-to-semantic decoding and semantic-to-acoustic decoding. In text-to-semantic decoding, a semantic-aware speech tokenizer converts the speech signal into semantic tokens, which can be synthesized from the text via a semantic language model in an auto-regressive manner. Meanwhile, the semantic-to-acoustic decoding module simultaneously translates generated semantic tokens into the speech signal in a streaming way via a super-resolution causal audio codec and a multi-stream acoustic language model. This design enables us to produce high-quality speech audio in zero-shot settings while presenting a real-time generation process with low latency under 150ms. In experiments on zero-shot voice cloning, the objective results validate FireRedTTS-1S as a high-quality foundation model with comparable intelligibility and speaker similarity over industrial baseline systems. Furthermore, the subjective score of FireRedTTS-1S highlights its impressive synthesis performance, achieving comparable quality to the ground-truth recordings. These results validate FireRedTTS-1S as a high-quality streaming foundation TTS system.
Enhanced Contrastive Learning with Multi-view Longitudinal Data for Chest X-ray Report Generation
Feb 27, 2025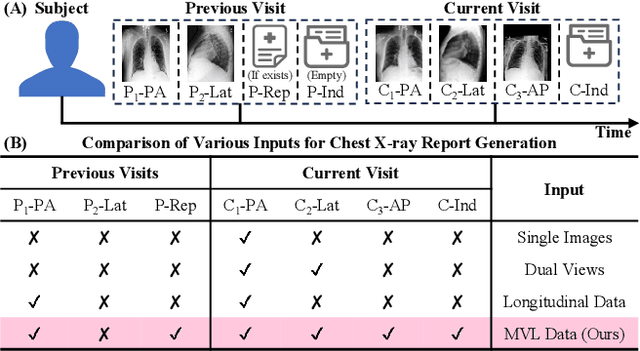

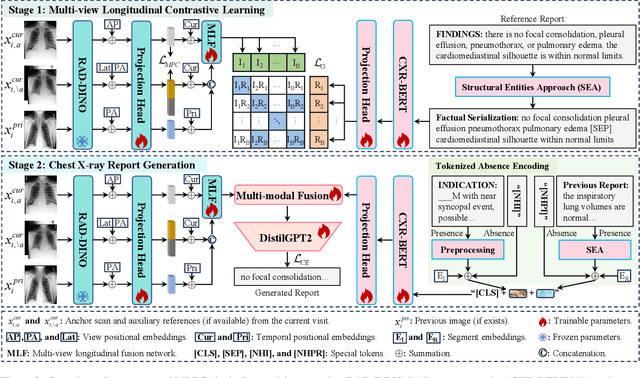
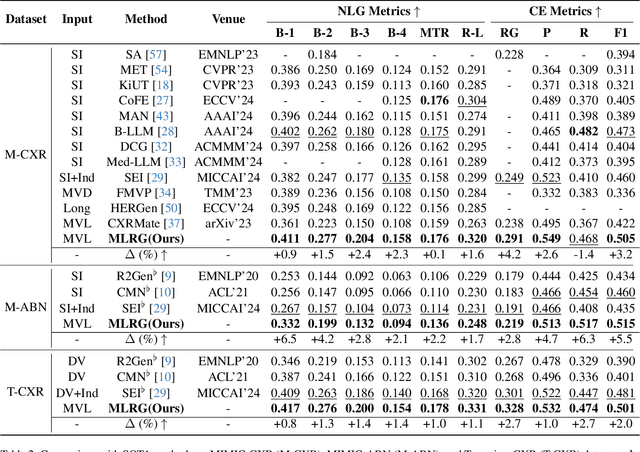
Automated radiology report generation offers an effective solution to alleviate radiologists' workload. However, most existing methods focus primarily on single or fixed-view images to model current disease conditions, which limits diagnostic accuracy and overlooks disease progression. Although some approaches utilize longitudinal data to track disease progression, they still rely on single images to analyze current visits. To address these issues, we propose enhanced contrastive learning with Multi-view Longitudinal data to facilitate chest X-ray Report Generation, named MLRG. Specifically, we introduce a multi-view longitudinal contrastive learning method that integrates spatial information from current multi-view images and temporal information from longitudinal data. This method also utilizes the inherent spatiotemporal information of radiology reports to supervise the pre-training of visual and textual representations. Subsequently, we present a tokenized absence encoding technique to flexibly handle missing patient-specific prior knowledge, allowing the model to produce more accurate radiology reports based on available prior knowledge. Extensive experiments on MIMIC-CXR, MIMIC-ABN, and Two-view CXR datasets demonstrate that our MLRG outperforms recent state-of-the-art methods, achieving a 2.3% BLEU-4 improvement on MIMIC-CXR, a 5.5% F1 score improvement on MIMIC-ABN, and a 2.7% F1 RadGraph improvement on Two-view CXR.
MCL: Multi-view Enhanced Contrastive Learning for Chest X-ray Report Generation
Nov 15, 2024



Radiology reports are crucial for planning treatment strategies and enhancing doctor-patient communication, yet manually writing these reports is burdensome for radiologists. While automatic report generation offers a solution, existing methods often rely on single-view radiographs, limiting diagnostic accuracy. To address this problem, we propose MCL, a Multi-view enhanced Contrastive Learning method for chest X-ray report generation. Specifically, we first introduce multi-view enhanced contrastive learning for visual representation by maximizing agreements between multi-view radiographs and their corresponding report. Subsequently, to fully exploit patient-specific indications (e.g., patient's symptoms) for report generation, we add a transitional ``bridge" for missing indications to reduce embedding space discrepancies caused by their presence or absence. Additionally, we construct Multi-view CXR and Two-view CXR datasets from public sources to support research on multi-view report generation. Our proposed MCL surpasses recent state-of-the-art methods across multiple datasets, achieving a 5.0% F1 RadGraph improvement on MIMIC-CXR, a 7.3% BLEU-1 improvement on MIMIC-ABN, a 3.1% BLEU-4 improvement on Multi-view CXR, and an 8.2% F1 CheXbert improvement on Two-view CXR.
Drone Data Analytics for Measuring Traffic Metrics at Intersections in High-Density Areas
Nov 04, 2024This study employed over 100 hours of high-altitude drone video data from eight intersections in Hohhot to generate a unique and extensive dataset encompassing high-density urban road intersections in China. This research has enhanced the YOLOUAV model to enable precise target recognition on unmanned aerial vehicle (UAV) datasets. An automated calibration algorithm is presented to create a functional dataset in high-density traffic flows, which saves human and material resources. This algorithm can capture up to 200 vehicles per frame while accurately tracking over 1 million road users, including cars, buses, and trucks. Moreover, the dataset has recorded over 50,000 complete lane changes. It is the largest publicly available road user trajectories in high-density urban intersections. Furthermore, this paper updates speed and acceleration algorithms based on UAV elevation and implements a UAV offset correction algorithm. A case study demonstrates the usefulness of the proposed methods, showing essential parameters to evaluate intersections and traffic conditions in traffic engineering. The model can track more than 200 vehicles of different types simultaneously in highly dense traffic on an urban intersection in Hohhot, generating heatmaps based on spatial-temporal traffic flow data and locating traffic conflicts by conducting lane change analysis and surrogate measures. With the diverse data and high accuracy of results, this study aims to advance research and development of UAVs in transportation significantly. The High-Density Intersection Dataset is available for download at https://github.com/Qpu523/High-density-Intersection-Dataset.
FireRedTTS: A Foundation Text-To-Speech Framework for Industry-Level Generative Speech Applications
Sep 05, 2024



This work proposes FireRedTTS, a foundation text-to-speech framework, to meet the growing demands for personalized and diverse generative speech applications. The framework comprises three parts: data processing, foundation system, and downstream applications. First, we comprehensively present our data processing pipeline, which transforms massive raw audio into a large-scale high-quality TTS dataset with rich annotations and a wide coverage of content, speaking style, and timbre. Then, we propose a language-model-based foundation TTS system. The speech signal is compressed into discrete semantic tokens via a semantic-aware speech tokenizer, and can be generated by a language model from the prompt text and audio. Then, a two-stage waveform generator is proposed to decode them to the high-fidelity waveform. We present two applications of this system: voice cloning for dubbing and human-like speech generation for chatbots. The experimental results demonstrate the solid in-context learning capability of FireRedTTS, which can stably synthesize high-quality speech consistent with the prompt text and audio. For dubbing, FireRedTTS can clone target voices in a zero-shot way for the UGC scenario and adapt to studio-level expressive voice characters in the PUGC scenario via few-shot fine-tuning with 1-hour recording. Moreover, FireRedTTS achieves controllable human-like speech generation in a casual style with paralinguistic behaviors and emotions via instruction tuning, to better serve spoken chatbots.
SoCodec: A Semantic-Ordered Multi-Stream Speech Codec for Efficient Language Model Based Text-to-Speech Synthesis
Sep 02, 2024

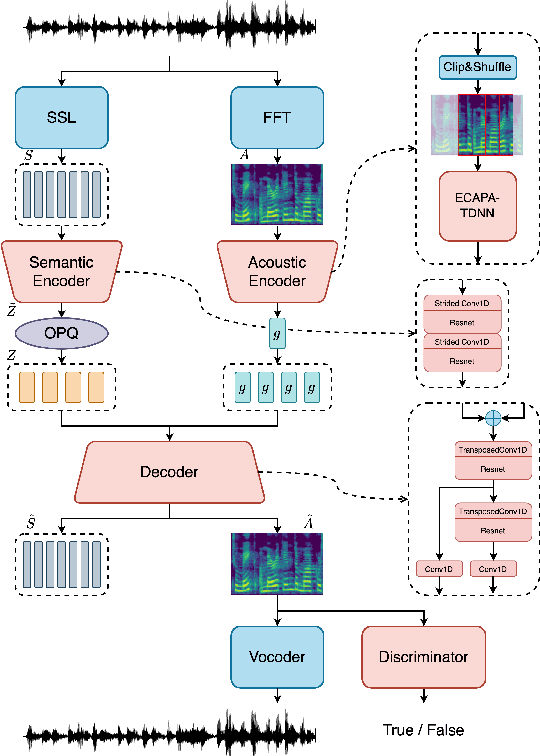

The long speech sequence has been troubling language models (LM) based TTS approaches in terms of modeling complexity and efficiency. This work proposes SoCodec, a semantic-ordered multi-stream speech codec, to address this issue. It compresses speech into a shorter, multi-stream discrete semantic sequence with multiple tokens at each frame. Meanwhile, the ordered product quantization is proposed to constrain this sequence into an ordered representation. It can be applied with a multi-stream delayed LM to achieve better autoregressive generation along both time and stream axes in TTS. The experimental result strongly demonstrates the effectiveness of the proposed approach, achieving superior performance over baseline systems even if compressing the frameshift of speech from 20ms to 240ms (12x). The ablation studies further validate the importance of learning the proposed ordered multi-stream semantic representation in pursuing shorter speech sequences for efficient LM-based TTS.