 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEDN: Motion-Emotion Feature Decoupling Network for Micro-Expression Recognition
Apr 20, 2026Unlike macro-expression, micro-expression does not follow a strictly consistent mapping rule between emotions and Action Units (AUs). As a result, some micro-expressions share identical AUs yet represent completely opposite emotional categories, making them highly visually similar. Existing microexpression recognition (MER) methods mostly rely on explicit facial motion cues (e.g., optical flow, frame differences, AU features) while ignoring implicit emotion information. To tackle this issue, this paper presents a Motion Emotion Feature Decoupling Network (MEDN) for MER. We design a dual-branch framework to separately extract motion and emotion features. In the motion branch, an AU-detection task restricts features to the explicit motion domain, and orthogonal loss is adopted to reduce motion emotion feature coupling. For implicit emotion modeling, we propose a Sparse Emotion Vision Transformer (SEVit) that sparsifies spatial tokens to highlight local temporal variations with multi-scale sparsity rates. A Collaborative Fusion Module (CoFM) is further developed to fuse disentangled motion and emotion features adaptively. Extensive experiments on three benchmark datasets validate that MEDN effectively decouples motion and emotion features and achieves superior recognition performance, offering a new perspective for enhancing recognition accuracy and generalization.
Seeing Like Radiologists: Context- and Gaze-Guided Vision-Language Pretraining for Chest X-rays
Mar 27, 2026Despite recent advances in medical vision-language pretraining, existing models still struggle to capture the diagnostic workflow: radiographs are typically treated as context-agnostic images, while radiologists' gaze -- a crucial cue for visual reasoning -- remains largely underexplored by existing methods. These limitations hinder the modeling of disease-specific patterns and weaken cross-modal alignment. To bridge this gap, we introduce CoGaze, a Context- and Gaze-guided vision-language pretraining framework for chest X-rays. We first propose a context-infused vision encoder that models how radiologists integrate clinical context -- including patient history, symptoms, and diagnostic intent -- to guide diagnostic reasoning. We then present a multi-level supervision paradigm that (1) enforces intra- and inter-modal semantic alignment through hybrid-positive contrastive learning, (2) injects diagnostic priors via disease-aware cross-modal representation learning, and (3) leverages radiologists' gaze as probabilistic priors to guide attention toward diagnostically salient regions. Extensive experiments demonstrate that CoGaze consistently outperforms state-of-the-art methods across diverse tasks, achieving up to +2.0% CheXbertF1 and +1.2% BLEU2 for free-text and structured report generation, +23.2% AUROC for zero-shot classification, and +12.2% Precision@1 for image-text retrieval. Code is available at https://github.com/mk-runner/CoGaze.
PriorRG: Prior-Guided Contrastive Pre-training and Coarse-to-Fine Decoding for Chest X-ray Report Generation
Aug 07, 2025



Chest X-ray report generation aims to reduce radiologists' workload by automatically producing high-quality preliminary reports. A critical yet underexplored aspect of this task is the effective use of patient-specific prior knowledge -- including clinical context (e.g., symptoms, medical history) and the most recent prior image -- which radiologists routinely rely on for diagnostic reasoning. Most existing methods generate reports from single images, neglecting this essential prior information and thus failing to capture diagnostic intent or disease progression. To bridge this gap, we propose PriorRG, a novel chest X-ray report generation framework that emulates real-world clinical workflows via a two-stage training pipeline. In Stage 1, we introduce a prior-guided contrastive pre-training scheme that leverages clinical context to guide spatiotemporal feature extraction, allowing the model to align more closely with the intrinsic spatiotemporal semantics in radiology reports. In Stage 2, we present a prior-aware coarse-to-fine decoding for report generation that progressively integrates patient-specific prior knowledge with the vision encoder's hidden states. This decoding allows the model to align with diagnostic focus and track disease progression, thereby enhancing the clinical accuracy and fluency of the generated reports. Extensive experiments on MIMIC-CXR and MIMIC-ABN datasets demonstrate that PriorRG outperforms state-of-the-art methods, achieving a 3.6% BLEU-4 and 3.8% F1 score improvement on MIMIC-CXR, and a 5.9% BLEU-1 gain on MIMIC-ABN. Code and checkpoints will be released upon acceptance.
FaceEditTalker: Interactive Talking Head Generation with Facial Attribute Editing
May 28, 2025Recent advances in audio-driven talking head generation have achieved impressive results in lip synchronization and emotional expression. However, they largely overlook the crucial task of facial attribute editing. This capability is crucial for achieving deep personalization and expanding the range of practical applications, including user-tailored digital avatars, engaging online education content, and brand-specific digital customer service. In these key domains, the flexible adjustment of visual attributes-such as hairstyle, accessories, and subtle facial features is essential for aligning with user preferences, reflecting diverse brand identities, and adapting to varying contextual demands. In this paper, we present FaceEditTalker, a unified framework that enables controllable facial attribute manipulation while generating high-quality, audio-synchronized talking head videos. Our method consists of two key components: an image feature space editing module, which extracts semantic and detail features and allows flexible control over attributes like expression, hairstyle, and accessories; and an audio-driven video generation module, which fuses these edited features with audio-guided facial landmarks to drive a diffusion-based generator. This design ensures temporal coherence, visual fidelity, and identity preservation across frames. Extensive experiments on public datasets demonstrate that our method outperforms state-of-the-art approaches in lip-sync accuracy, video quality, and attribute controllability. Project page: https://peterfanfan.github.io/FaceEditTalker/
Generative Sign-description Prompts with Multi-positive Contrastive Learning for Sign Language Recognition
May 05, 2025Sign language recognition (SLR) faces fundamental challenges in creating accurate annotations due to the inherent complexity of simultaneous manual and non-manual signals. To the best of our knowledge, this is the first work to integrate generative large language models (LLMs) into SLR tasks. We propose a novel Generative Sign-description Prompts Multi-positive Contrastive learning (GSP-MC) method that leverages retrieval-augmented generation (RAG) with domain-specific LLMs, incorporating multi-step prompt engineering and expert-validated sign language corpora to produce precise multipart descriptions. The GSP-MC method also employs a dual-encoder architecture to bidirectionally align hierarchical skeleton features with multiple text descriptions (global, synonym, and part level) through probabilistic matching. Our approach combines global and part-level losses, optimizing KL divergence to ensure robust alignment across all relevant text-skeleton pairs while capturing both sign-level semantics and detailed part dynamics. Experiments demonstrate state-of-the-art performance against existing methods on the Chinese SLR500 (reaching 97.1%) and Turkish AUTSL datasets (97.07% accuracy). The method's cross-lingual effectiveness highlight its potential for developing inclusive communication technologies.
Enhanced Contrastive Learning with Multi-view Longitudinal Data for Chest X-ray Report Generation
Feb 27, 2025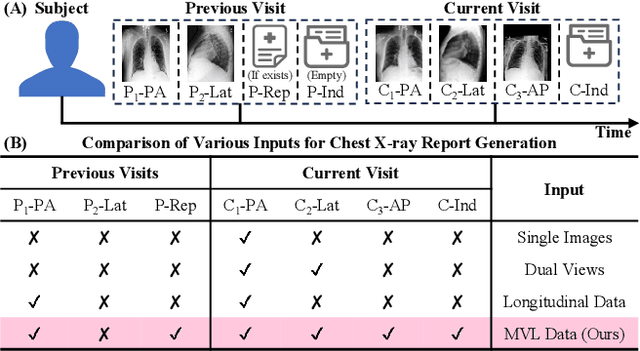

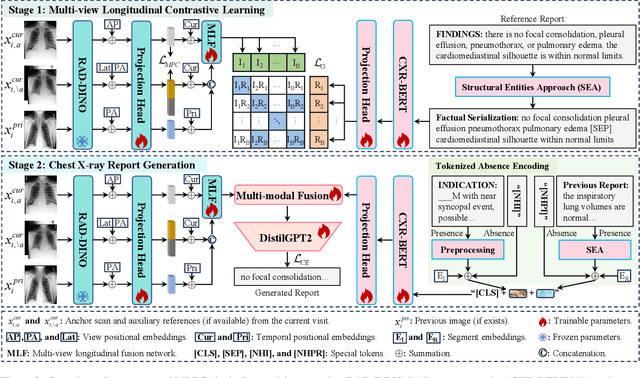
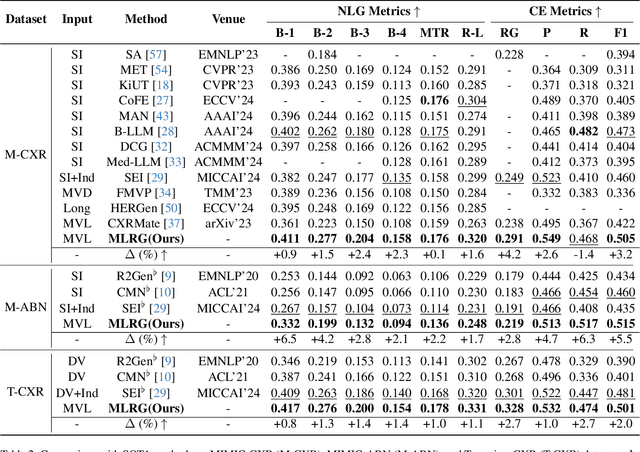
Automated radiology report generation offers an effective solution to alleviate radiologists' workload. However, most existing methods focus primarily on single or fixed-view images to model current disease conditions, which limits diagnostic accuracy and overlooks disease progression. Although some approaches utilize longitudinal data to track disease progression, they still rely on single images to analyze current visits. To address these issues, we propose enhanced contrastive learning with Multi-view Longitudinal data to facilitate chest X-ray Report Generation, named MLRG. Specifically, we introduce a multi-view longitudinal contrastive learning method that integrates spatial information from current multi-view images and temporal information from longitudinal data. This method also utilizes the inherent spatiotemporal information of radiology reports to supervise the pre-training of visual and textual representations. Subsequently, we present a tokenized absence encoding technique to flexibly handle missing patient-specific prior knowledge, allowing the model to produce more accurate radiology reports based on available prior knowledge. Extensive experiments on MIMIC-CXR, MIMIC-ABN, and Two-view CXR datasets demonstrate that our MLRG outperforms recent state-of-the-art methods, achieving a 2.3% BLEU-4 improvement on MIMIC-CXR, a 5.5% F1 score improvement on MIMIC-ABN, and a 2.7% F1 RadGraph improvement on Two-view CXR.
MCL: Multi-view Enhanced Contrastive Learning for Chest X-ray Report Generation
Nov 15, 2024



Radiology reports are crucial for planning treatment strategies and enhancing doctor-patient communication, yet manually writing these reports is burdensome for radiologists. While automatic report generation offers a solution, existing methods often rely on single-view radiographs, limiting diagnostic accuracy. To address this problem, we propose MCL, a Multi-view enhanced Contrastive Learning method for chest X-ray report generation. Specifically, we first introduce multi-view enhanced contrastive learning for visual representation by maximizing agreements between multi-view radiographs and their corresponding report. Subsequently, to fully exploit patient-specific indications (e.g., patient's symptoms) for report generation, we add a transitional ``bridge" for missing indications to reduce embedding space discrepancies caused by their presence or absence. Additionally, we construct Multi-view CXR and Two-view CXR datasets from public sources to support research on multi-view report generation. Our proposed MCL surpasses recent state-of-the-art methods across multiple datasets, achieving a 5.0% F1 RadGraph improvement on MIMIC-CXR, a 7.3% BLEU-1 improvement on MIMIC-ABN, a 3.1% BLEU-4 improvement on Multi-view CXR, and an 8.2% F1 CheXbert improvement on Two-view CXR.
LES-Talker: Fine-Grained Emotion Editing for Talking Head Generation in Linear Emotion Space
Nov 14, 2024While existing one-shot talking head generation models have achieved progress in coarse-grained emotion editing, there is still a lack of fine-grained emotion editing models with high interpretability. We argue that for an approach to be considered fine-grained, it needs to provide clear definitions and sufficiently detailed differentiation. We present LES-Talker, a novel one-shot talking head generation model with high interpretability, to achieve fine-grained emotion editing across emotion types, emotion levels, and facial units. We propose a Linear Emotion Space (LES) definition based on Facial Action Units to characterize emotion transformations as vector transformations. We design the Cross-Dimension Attention Net (CDAN) to deeply mine the correlation between LES representation and 3D model representation. Through mining multiple relationships across different feature and structure dimensions, we enable LES representation to guide the controllable deformation of 3D model. In order to adapt the multimodal data with deviations to the LES and enhance visual quality, we utilize specialized network design and training strategies. Experiments show that our method provides high visual quality along with multilevel and interpretable fine-grained emotion editing, outperforming mainstream methods.
Triple Point Masking
Sep 26, 2024Existing 3D mask learning methods encounter performance bottlenecks under limited data, and our objective is to overcome this limitation. In this paper, we introduce a triple point masking scheme, named TPM, which serves as a scalable framework for pre-training of masked autoencoders to achieve multi-mask learning for 3D point clouds. Specifically, we augment the baselines with two additional mask choices (i.e., medium mask and low mask) as our core insight is that the recovery process of an object can manifest in diverse ways. Previous high-masking schemes focus on capturing the global representation but lack the fine-grained recovery capability, so that the generated pre-trained weights tend to play a limited role in the fine-tuning process. With the support of the proposed TPM, available methods can exhibit more flexible and accurate completion capabilities, enabling the potential autoencoder in the pre-training stage to consider multiple representations of a single 3D object. In addition, an SVM-guided weight selection module is proposed to fill the encoder parameters for downstream networks with the optimal weight during the fine-tuning stage, maximizing linear accuracy and facilitating the acquisition of intricate representations for new objects. Extensive experiments show that the four baselines equipped with the proposed TPM achieve comprehensive performance improvements on various downstream tasks.
Structure-enhanced Contrastive Learning for Graph Clustering
Aug 19, 2024



Graph clustering is a crucial task in network analysis with widespread applications, focusing on partitioning nodes into distinct groups with stronger intra-group connections than inter-group ones. Recently, contrastive learning has achieved significant progress in graph clustering. However, most methods suffer from the following issues: 1) an over-reliance on meticulously designed data augmentation strategies, which can undermine the potential of contrastive learning. 2) overlooking cluster-oriented structural information, particularly the higher-order cluster(community) structure information, which could unveil the mesoscopic cluster structure information of the network. In this study, Structure-enhanced Contrastive Learning (SECL) is introduced to addresses these issues by leveraging inherent network structures. SECL utilizes a cross-view contrastive learning mechanism to enhance node embeddings without elaborate data augmentations, a structural contrastive learning module for ensuring structural consistency, and a modularity maximization strategy for harnessing clustering-oriented information. This comprehensive approach results in robust node representations that greatly enhance clustering performance. Extensive experiments on six datasets confirm SECL's superiority over current state-of-the-art methods, indicating a substantial improvement in the domain of graph clustering.