 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA multitask framework for automated interpretation of multi-frame right upper quadrant ultrasound in clinical decision support
Jan 17, 2026Ultrasound is a cornerstone of emergency and hepatobiliary imaging, yet its interpretation remains highly operator-dependent and time-sensitive. Here, we present a multitask vision-language agent (VLM) developed to assist with comprehensive right upper quadrant (RUQ) ultrasound interpretation across the full diagnostic workflow. The system was trained on a large, multi-center dataset comprising a primary cohort from Johns Hopkins Medical Institutions (9,189 cases, 594,099 images) and externally validated on cohorts from Stanford University (108 cases, 3,240 images) and a major Chinese medical center (257 cases, 3,178 images). Built on the Qwen2.5-VL-7B architecture, the agent integrates frame-level visual understanding with report-grounded language reasoning to perform three tasks: (i) classification of 18 hepatobiliary and gallbladder conditions, (ii) generation of clinically coherent diagnostic reports, and (iii) surgical decision support based on ultrasound findings and clinical data. The model achieved high diagnostic accuracy across all tasks, generated reports that were indistinguishable from expert-written versions in blinded evaluations, and demonstrated superior factual accuracy and information density on content-based metrics. The agent further identified patients requiring cholecystectomy with high precision, supporting real-time decision-making. These results highlight the potential of generalist vision-language models to improve diagnostic consistency, reporting efficiency, and surgical triage in real-world ultrasound practice.
Abn-BLIP: Abnormality-aligned Bootstrapping Language-Image Pre-training for Pulmonary Embolism Diagnosis and Report Generation from CTPA
Mar 03, 2025Medical imaging plays a pivotal role in modern healthcare, with computed tomography pulmonary angiography (CTPA) being a critical tool for diagnosing pulmonary embolism and other thoracic conditions. However, the complexity of interpreting CTPA scans and generating accurate radiology reports remains a significant challenge. This paper introduces Abn-BLIP (Abnormality-aligned Bootstrapping Language-Image Pretraining), an advanced diagnosis model designed to align abnormal findings to generate the accuracy and comprehensiveness of radiology reports. By leveraging learnable queries and cross-modal attention mechanisms, our model demonstrates superior performance in detecting abnormalities, reducing missed findings, and generating structured reports compared to existing methods. Our experiments show that Abn-BLIP outperforms state-of-the-art medical vision-language models and 3D report generation methods in both accuracy and clinical relevance. These results highlight the potential of integrating multimodal learning strategies for improving radiology reporting. The source code is available at https://github.com/zzs95/abn-blip.
Optimizing Prompt Strategies for SAM: Advancing lesion Segmentation Across Diverse Medical Imaging Modalities
Dec 28, 2024



Purpose: To evaluate various Segmental Anything Model (SAM) prompt strategies across four lesions datasets and to subsequently develop a reinforcement learning (RL) agent to optimize SAM prompt placement. Materials and Methods: This retrospective study included patients with four independent ovarian, lung, renal, and breast tumor datasets. Manual segmentation and SAM-assisted segmentation were performed for all lesions. A RL model was developed to predict and select SAM points to maximize segmentation performance. Statistical analysis of segmentation was conducted using pairwise t-tests. Results: Results show that increasing the number of prompt points significantly improves segmentation accuracy, with Dice coefficients rising from 0.272 for a single point to 0.806 for five or more points in ovarian tumors. The prompt location also influenced performance, with surface and union-based prompts outperforming center-based prompts, achieving mean Dice coefficients of 0.604 and 0.724 for ovarian and breast tumors, respectively. The RL agent achieved a peak Dice coefficient of 0.595 for ovarian tumors, outperforming random and alternative RL strategies. Additionally, it significantly reduced segmentation time, achieving a nearly 10-fold improvement compared to manual methods using SAM. Conclusion: While increased SAM prompts and non-centered prompts generally improved segmentation accuracy, each pathology and modality has specific optimal thresholds and placement strategies. Our RL agent achieved superior performance compared to other agents while achieving a significant reduction in segmentation time.
Optimizing prompt strategies for the Segment Anything Model are explored, focusing on prompt location, number, and reinforcement learning-based agent for prompt placement across four lesion datasets
Dec 23, 2024Purpose: To evaluate various Segmental Anything Model (SAM) prompt strategies across four lesions datasets and to subsequently develop a reinforcement learning (RL) agent to optimize SAM prompt placement. Materials and Methods: This retrospective study included patients with four independent ovarian, lung, renal, and breast tumor datasets. Manual segmentation and SAM-assisted segmentation were performed for all lesions. A RL model was developed to predict and select SAM points to maximize segmentation performance. Statistical analysis of segmentation was conducted using pairwise t-tests. Results: Results show that increasing the number of prompt points significantly improves segmentation accuracy, with Dice coefficients rising from 0.272 for a single point to 0.806 for five or more points in ovarian tumors. The prompt location also influenced performance, with surface and union-based prompts outperforming center-based prompts, achieving mean Dice coefficients of 0.604 and 0.724 for ovarian and breast tumors, respectively. The RL agent achieved a peak Dice coefficient of 0.595 for ovarian tumors, outperforming random and alternative RL strategies. Additionally, it significantly reduced segmentation time, achieving a nearly 10-fold improvement compared to manual methods using SAM. Conclusion: While increased SAM prompts and non-centered prompts generally improved segmentation accuracy, each pathology and modality has specific optimal thresholds and placement strategies. Our RL agent achieved superior performance compared to other agents while achieving a significant reduction in segmentation time.
Pulmonary Embolism Mortality Prediction Using Multimodal Learning Based on Computed Tomography Angiography and Clinical Data
Jun 03, 2024Purpose: Pulmonary embolism (PE) is a significant cause of mortality in the United States. The objective of this study is to implement deep learning (DL) models using Computed Tomography Pulmonary Angiography (CTPA), clinical data, and PE Severity Index (PESI) scores to predict PE mortality. Materials and Methods: 918 patients (median age 64 years, range 13-99 years, 52% female) with 3,978 CTPAs were identified via retrospective review across three institutions. To predict survival, an AI model was used to extract disease-related imaging features from CTPAs. Imaging features and/or clinical variables were then incorporated into DL models to predict survival outcomes. Four models were developed as follows: (1) using CTPA imaging features only; (2) using clinical variables only; (3) multimodal, integrating both CTPA and clinical variables; and (4) multimodal fused with calculated PESI score. Performance and contribution from each modality were evaluated using concordance index (c-index) and Net Reclassification Improvement, respectively. Performance was compared to PESI predictions using the Wilcoxon signed-rank test. Kaplan-Meier analysis was performed to stratify patients into high- and low-risk groups. Additional factor-risk analysis was conducted to account for right ventricular (RV) dysfunction. Results: For both data sets, the PESI-fused and multimodal models achieved higher c-indices than PESI alone. Following stratification of patients into high- and low-risk groups by multimodal and PESI-fused models, mortality outcomes differed significantly (both p<0.001). A strong correlation was found between high-risk grouping and RV dysfunction. Conclusions: Multiomic DL models incorporating CTPA features, clinical data, and PESI achieved higher c-indices than PESI alone for PE survival prediction.
Structural Entities Extraction and Patient Indications Incorporation for Chest X-ray Report Generation
May 23, 2024



The automated generation of imaging reports proves invaluable in alleviating the workload of radiologists. A clinically applicable reports generation algorithm should demonstrate its effectiveness in producing reports that accurately describe radiology findings and attend to patient-specific indications. In this paper, we introduce a novel method, \textbf{S}tructural \textbf{E}ntities extraction and patient indications \textbf{I}ncorporation (SEI) for chest X-ray report generation. Specifically, we employ a structural entities extraction (SEE) approach to eliminate presentation-style vocabulary in reports and improve the quality of factual entity sequences. This reduces the noise in the following cross-modal alignment module by aligning X-ray images with factual entity sequences in reports, thereby enhancing the precision of cross-modal alignment and further aiding the model in gradient-free retrieval of similar historical cases. Subsequently, we propose a cross-modal fusion network to integrate information from X-ray images, similar historical cases, and patient-specific indications. This process allows the text decoder to attend to discriminative features of X-ray images, assimilate historical diagnostic information from similar cases, and understand the examination intention of patients. This, in turn, assists in triggering the text decoder to produce high-quality reports. Experiments conducted on MIMIC-CXR validate the superiority of SEI over state-of-the-art approaches on both natural language generation and clinical efficacy metrics.
Multi-modality Regional Alignment Network for Covid X-Ray Survival Prediction and Report Generation
May 23, 2024In response to the worldwide COVID-19 pandemic, advanced automated technologies have emerged as valuable tools to aid healthcare professionals in managing an increased workload by improving radiology report generation and prognostic analysis. This study proposes Multi-modality Regional Alignment Network (MRANet), an explainable model for radiology report generation and survival prediction that focuses on high-risk regions. By learning spatial correlation in the detector, MRANet visually grounds region-specific descriptions, providing robust anatomical regions with a completion strategy. The visual features of each region are embedded using a novel survival attention mechanism, offering spatially and risk-aware features for sentence encoding while maintaining global coherence across tasks. A cross LLMs alignment is employed to enhance the image-to-text transfer process, resulting in sentences rich with clinical detail and improved explainability for radiologist. Multi-center experiments validate both MRANet's overall performance and each module's composition within the model, encouraging further advancements in radiology report generation research emphasizing clinical interpretation and trustworthiness in AI models applied to medical studies. The code is available at https://github.com/zzs95/MRANet.
Region-specific Risk Quantification for Interpretable Prognosis of COVID-19
May 05, 2024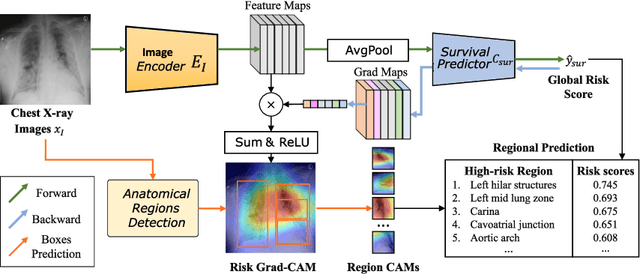
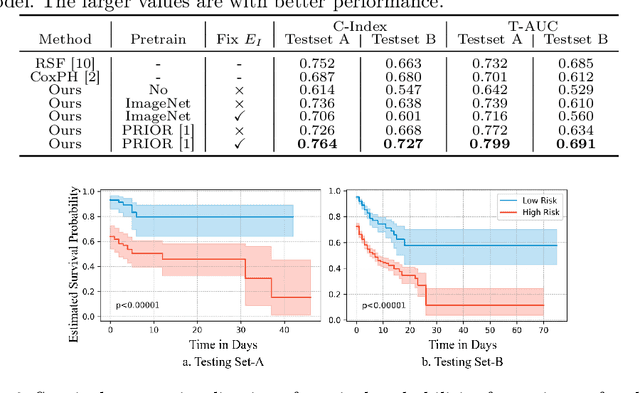

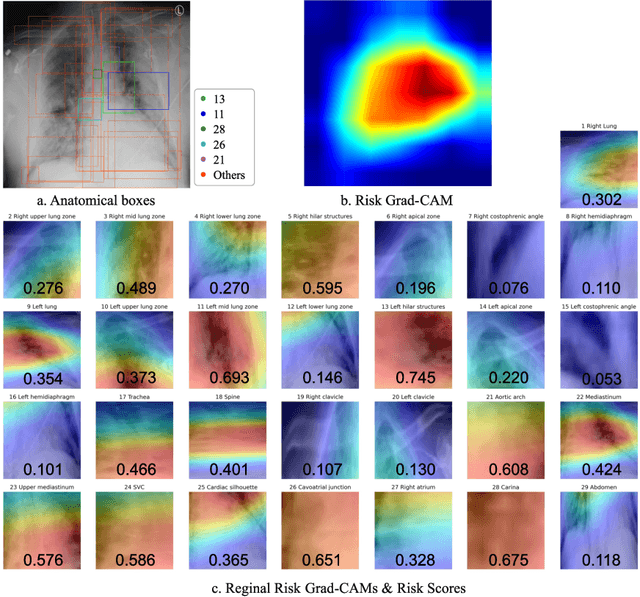
The COVID-19 pandemic has strained global public health, necessitating accurate diagnosis and intervention to control disease spread and reduce mortality rates. This paper introduces an interpretable deep survival prediction model designed specifically for improved understanding and trust in COVID-19 prognosis using chest X-ray (CXR) images. By integrating a large-scale pretrained image encoder, Risk-specific Grad-CAM, and anatomical region detection techniques, our approach produces regional interpretable outcomes that effectively capture essential disease features while focusing on rare but critical abnormal regions. Our model's predictive results provide enhanced clarity and transparency through risk area localization, enabling clinicians to make informed decisions regarding COVID-19 diagnosis with better understanding of prognostic insights. We evaluate the proposed method on a multi-center survival dataset and demonstrate its effectiveness via quantitative and qualitative assessments, achieving superior C-indexes (0.764 and 0.727) and time-dependent AUCs (0.799 and 0.691). These results suggest that our explainable deep survival prediction model surpasses traditional survival analysis methods in risk prediction, improving interpretability for clinical decision making and enhancing AI system trustworthiness.
SMC-UDA: Structure-Modal Constraint for Unsupervised Cross-Domain Renal Segmentation
Jun 14, 2023Medical image segmentation based on deep learning often fails when deployed on images from a different domain. The domain adaptation methods aim to solve domain-shift challenges, but still face some problems. The transfer learning methods require annotation on the target domain, and the generative unsupervised domain adaptation (UDA) models ignore domain-specific representations, whose generated quality highly restricts segmentation performance. In this study, we propose a novel Structure-Modal Constrained (SMC) UDA framework based on a discriminative paradigm and introduce edge structure as a bridge between domains. The proposed multi-modal learning backbone distills structure information from image texture to distinguish domain-invariant edge structure. With the structure-constrained self-learning and progressive ROI, our methods segment the kidney by locating the 3D spatial structure of the edge. We evaluated SMC-UDA on public renal segmentation datasets, adapting from the labeled source domain (CT) to the unlabeled target domain (CT/MRI). The experiments show that our proposed SMC-UDA has a strong generalization and outperforms generative UDA methods.
Collaborative Boundary-aware Context Encoding Networks for Error Map Prediction
Jun 25, 2020


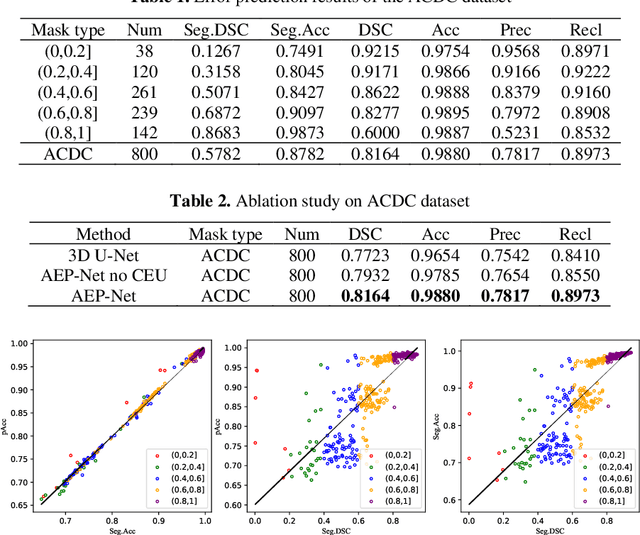
Medical image segmentation is usually regarded as one of the most important intermediate steps in clinical situations and medical imaging research. Thus, accurately assessing the segmentation quality of the automatically generated predictions is essential for guaranteeing the reliability of the results of the computer-assisted diagnosis (CAD). Many researchers apply neural networks to train segmentation quality regression models to estimate the segmentation quality of a new data cohort without labeled ground truth. Recently, a novel idea is proposed that transforming the segmentation quality assessment (SQA) problem intothe pixel-wise error map prediction task in the form of segmentation. However, the simple application of vanilla segmentation structures in medical image fails to detect some small and thin error regions of the auto-generated masks with complex anatomical structures. In this paper, we propose collaborative boundaryaware context encoding networks called AEP-Net for error prediction task. Specifically, we propose a collaborative feature transformation branch for better feature fusion between images and masks, and precise localization of error regions. Further, we propose a context encoding module to utilize the global predictor from the error map to enhance the feature representation and regularize the networks. We perform experiments on IBSR v2.0 dataset and ACDC dataset. The AEP-Net achieves an average DSC of 0.8358, 0.8164 for error prediction task,and shows a high Pearson correlation coefficient of 0.9873 between the actual segmentation accuracy and the predicted accuracy inferred from the predicted error map on IBSR v2.0 dataset, which verifies the efficacy of our AEP-Net.