 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Evidential-enhanced Tri-Branch Consistency Learning Method for Semi-supervised Medical Image Segmentation
Apr 10, 2024Semi-supervised segmentation presents a promising approach for large-scale medical image analysis, effectively reducing annotation burdens while achieving comparable performance. This methodology holds substantial potential for streamlining the segmentation process and enhancing its feasibility within clinical settings for translational investigations. While cross-supervised training, based on distinct co-training sub-networks, has become a prevalent paradigm for this task, addressing critical issues such as predication disagreement and label-noise suppression requires further attention and progress in cross-supervised training. In this paper, we introduce an Evidential Tri-Branch Consistency learning framework (ETC-Net) for semi-supervised medical image segmentation. ETC-Net employs three branches: an evidential conservative branch, an evidential progressive branch, and an evidential fusion branch. The first two branches exhibit complementary characteristics, allowing them to address prediction diversity and enhance training stability. We also integrate uncertainty estimation from the evidential learning into cross-supervised training, mitigating the negative impact of erroneous supervision signals. Additionally, the evidential fusion branch capitalizes on the complementary attributes of the first two branches and leverages an evidence-based Dempster-Shafer fusion strategy, supervised by more reliable and accurate pseudo-labels of unlabeled data. Extensive experiments conducted on LA, Pancreas-CT, and ACDC datasets demonstrate that ETC-Net surpasses other state-of-the-art methods for semi-supervised segmentation. The code will be made available in the near future at https://github.com/Medsemiseg.
Multi Task Consistency Guided Source-Free Test-Time Domain Adaptation Medical Image Segmentation
Oct 18, 2023


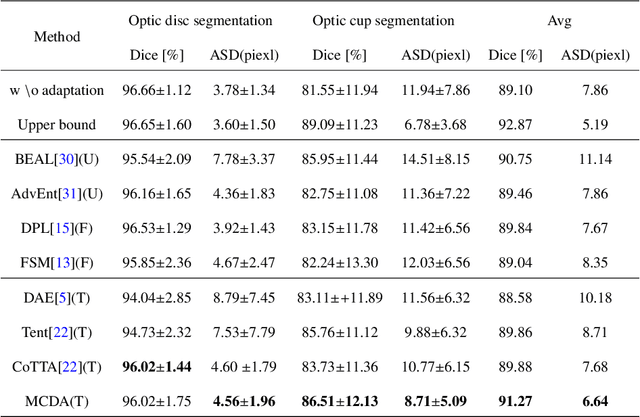
Source-free test-time adaptation for medical image segmentation aims to enhance the adaptability of segmentation models to diverse and previously unseen test sets of the target domain, which contributes to the generalizability and robustness of medical image segmentation models without access to the source domain. Ensuring consistency between target edges and paired inputs is crucial for test-time adaptation. To improve the performance of test-time domain adaptation, we propose a multi task consistency guided source-free test-time domain adaptation medical image segmentation method which ensures the consistency of the local boundary predictions and the global prototype representation. Specifically, we introduce a local boundary consistency constraint method that explores the relationship between tissue region segmentation and tissue boundary localization tasks. Additionally, we propose a global feature consistency constraint toto enhance the intra-class compactness. We conduct extensive experiments on the segmentation of benchmark fundus images. Compared to prediction directly by the source domain model, the segmentation Dice score is improved by 6.27\% and 0.96\% in RIM-ONE-r3 and Drishti GS datasets, respectively. Additionally, the results of experiments demonstrate that our proposed method outperforms existing competitive domain adaptation segmentation algorithms.
Cross-supervised Dual Classifiers for Semi-supervised Medical Image Segmentation
May 25, 2023Semi-supervised medical image segmentation offers a promising solution for large-scale medical image analysis by significantly reducing the annotation burden while achieving comparable performance. Employing this method exhibits a high degree of potential for optimizing the segmentation process and increasing its feasibility in clinical settings during translational investigations. Recently, cross-supervised training based on different co-training sub-networks has become a standard paradigm for this task. Still, the critical issues of sub-network disagreement and label-noise suppression require further attention and progress in cross-supervised training. This paper proposes a cross-supervised learning framework based on dual classifiers (DC-Net), including an evidential classifier and a vanilla classifier. The two classifiers exhibit complementary characteristics, enabling them to handle disagreement effectively and generate more robust and accurate pseudo-labels for unlabeled data. We also incorporate the uncertainty estimation from the evidential classifier into cross-supervised training to alleviate the negative effect of the error supervision signal. The extensive experiments on LA and Pancreas-CT dataset illustrate that DC-Net outperforms other state-of-the-art methods for semi-supervised segmentation. The code will be released soon.
Self-aware and Cross-sample Prototypical Learning for Semi-supervised Medical Image Segmentation
May 25, 2023



Consistency learning plays a crucial role in semi-supervised medical image segmentation as it enables the effective utilization of limited annotated data while leveraging the abundance of unannotated data. The effectiveness and efficiency of consistency learning are challenged by prediction diversity and training stability, which are often overlooked by existing studies. Meanwhile, the limited quantity of labeled data for training often proves inadequate for formulating intra-class compactness and inter-class discrepancy of pseudo labels. To address these issues, we propose a self-aware and cross-sample prototypical learning method (SCP-Net) to enhance the diversity of prediction in consistency learning by utilizing a broader range of semantic information derived from multiple inputs. Furthermore, we introduce a self-aware consistency learning method that exploits unlabeled data to improve the compactness of pseudo labels within each class. Moreover, a dual loss re-weighting method is integrated into the cross-sample prototypical consistency learning method to improve the reliability and stability of our model. Extensive experiments on ACDC dataset and PROMISE12 dataset validate that SCP-Net outperforms other state-of-the-art semi-supervised segmentation methods and achieves significant performance gains compared to the limited supervised training. Our code will come soon.
The CLIP Model is Secretly an Image-to-Prompt Converter
May 22, 2023



The Stable Diffusion model is a prominent text-to-image generation model that relies on a text prompt as its input, which is encoded using the Contrastive Language-Image Pre-Training (CLIP). However, text prompts have limitations when it comes to incorporating implicit information from reference images. Existing methods have attempted to address this limitation by employing expensive training procedures involving millions of training samples for image-to-image generation. In contrast, this paper demonstrates that the CLIP model, as utilized in Stable Diffusion, inherently possesses the ability to instantaneously convert images into text prompts. Such an image-to-prompt conversion can be achieved by utilizing a linear projection matrix that is calculated in a closed form. Moreover, the paper showcases that this capability can be further enhanced by either utilizing a small amount of similar-domain training data (approximately 100 images) or incorporating several online training steps (around 30 iterations) on the reference images. By leveraging these approaches, the proposed method offers a simple and flexible solution to bridge the gap between images and text prompts. This methodology can be applied to various tasks such as image variation and image editing, facilitating more effective and seamless interaction between images and textual prompts.
Position-Aware Relation Learning for RGB-Thermal Salient Object Detection
Sep 21, 2022
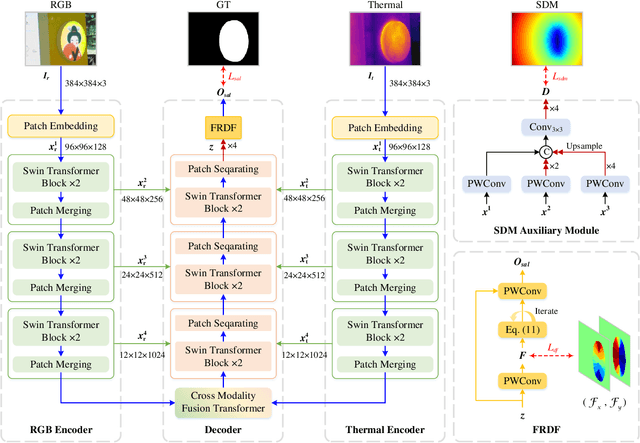
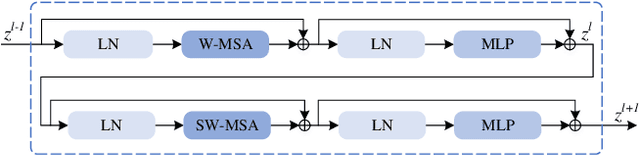

RGB-Thermal salient object detection (SOD) combines two spectra to segment visually conspicuous regions in images. Most existing methods use boundary maps to learn the sharp boundary. These methods ignore the interactions between isolated boundary pixels and other confident pixels, leading to sub-optimal performance. To address this problem,we propose a position-aware relation learning network (PRLNet) for RGB-T SOD based on swin transformer. PRLNet explores the distance and direction relationships between pixels to strengthen intra-class compactness and inter-class separation, generating salient object masks with clear boundaries and homogeneous regions. Specifically, we develop a novel signed distance map auxiliary module (SDMAM) to improve encoder feature representation, which takes into account the distance relation of different pixels in boundary neighborhoods. Then, we design a feature refinement approach with directional field (FRDF), which rectifies features of boundary neighborhood by exploiting the features inside salient objects. FRDF utilizes the directional information between object pixels to effectively enhance the intra-class compactness of salient regions. In addition, we constitute a pure transformer encoder-decoder network to enhance multispectral feature representation for RGB-T SOD. Finally, we conduct quantitative and qualitative experiments on three public benchmark datasets.The results demonstrate that our proposed method outperforms the state-of-the-art methods.
Don't Stop Learning: Towards Continual Learning for the CLIP Model
Jul 20, 2022
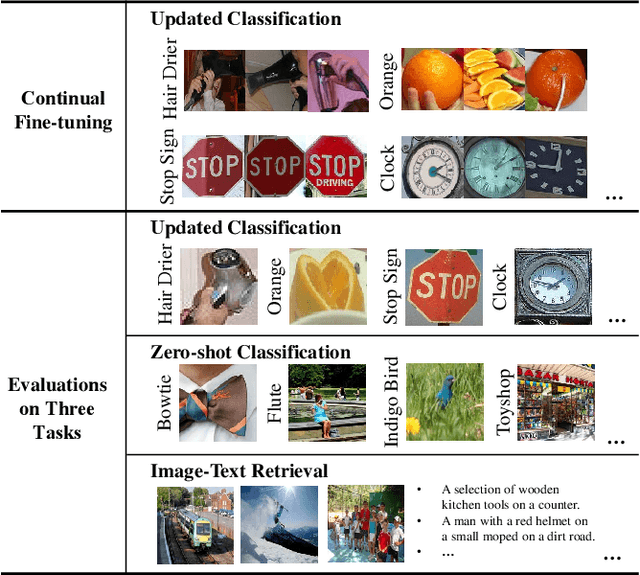
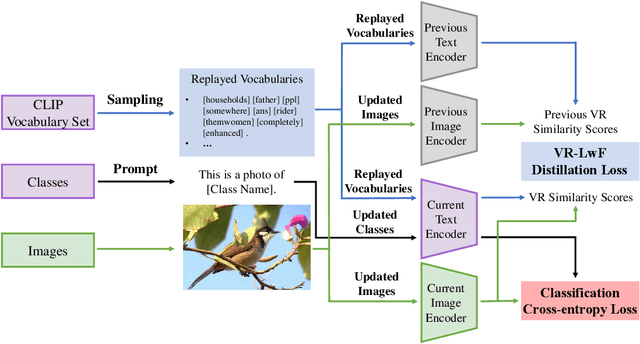
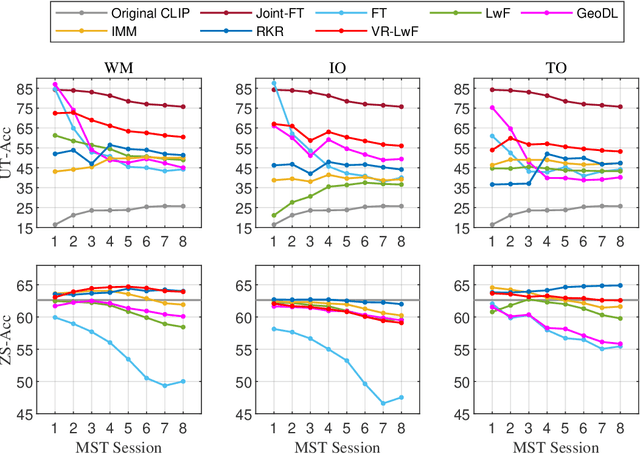
The Contrastive Language-Image Pre-training (CLIP) Model is a recently proposed large-scale pre-train model which attracts increasing attention in the computer vision community. Benefiting from its gigantic image-text training set, the CLIP model has learned outstanding capabilities in zero-shot learning and image-text matching. To boost the recognition performance of CLIP on some target visual concepts, it is often desirable to further update the CLIP model by fine-tuning some classes-of-interest on extra training data. This operation, however, raises an important concern: will the update hurt the zero-shot learning or image-text matching capability of the CLIP, i.e., the catastrophic forgetting issue? If yes, could existing continual learning algorithms be adapted to alleviate the risk of catastrophic forgetting? To answer these questions, this work conducts a systemic study on the continual learning issue of the CLIP model. We construct evaluation protocols to measure the impact of fine-tuning updates and explore different ways to upgrade existing continual learning methods to mitigate the forgetting issue of the CLIP model. Our study reveals the particular challenges of CLIP continual learning problem and lays a foundation for further researches. Moreover, we propose a new algorithm, dubbed Learning without Forgetting via Replayed Vocabulary (VR-LwF), which shows exact effectiveness for alleviating the forgetting issue of the CLIP model.
Mutual- and Self- Prototype Alignment for Semi-supervised Medical Image Segmentation
Jun 03, 2022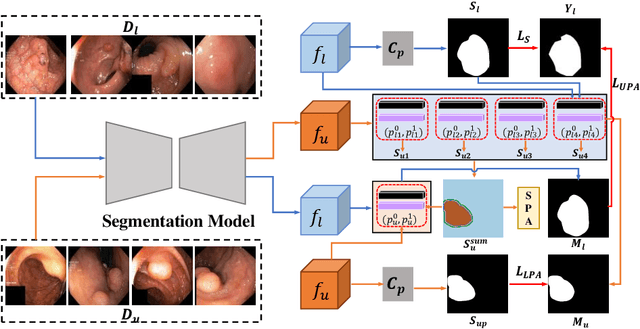
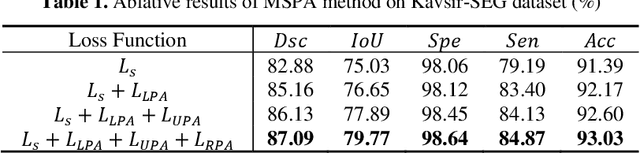
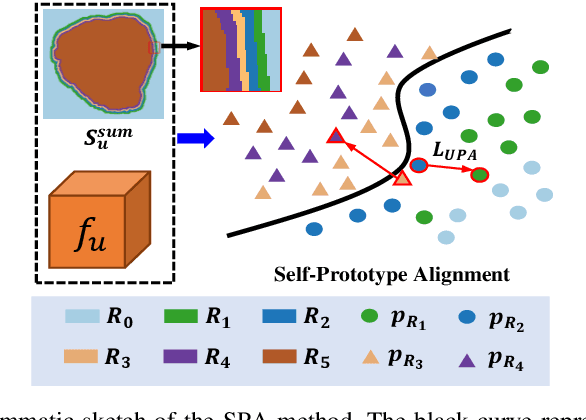
Semi-supervised learning methods have been explored in medical image segmentation tasks due to the scarcity of pixel-level annotation in the real scenario. Proto-type alignment based consistency constraint is an intuitional and plausible solu-tion to explore the useful information in the unlabeled data. In this paper, we propose a mutual- and self- prototype alignment (MSPA) framework to better utilize the unlabeled data. In specific, mutual-prototype alignment enhances the information interaction between labeled and unlabeled data. The mutual-prototype alignment imposes two consistency constraints in reverse directions between the unlabeled and labeled data, which enables the consistent embedding and model discriminability on unlabeled data. The proposed self-prototype alignment learns more stable region-wise features within unlabeled images, which optimizes the classification margin in semi-supervised segmentation by boosting the intra-class compactness and inter-class separation on the feature space. Extensive experimental results on three medical datasets demonstrate that with a small amount of labeled data, MSPA achieves large improvements by leveraging the unlabeled data. Our method also outperforms seven state-of-the-art semi-supervised segmentation methods on all three datasets.
PixelGame: Infrared small target segmentation as a Nash equilibrium
May 26, 2022



A key challenge of infrared small target segmentation (ISTS) is to balance false negative pixels (FNs) and false positive pixels (FPs). Traditional methods combine FNs and FPs into a single objective by weighted sum, and the optimization process is decided by one actor. Minimizing FNs and FPs with the same strategy leads to antagonistic decisions. To address this problem, we propose a competitive game framework (pixelGame) from a novel perspective for ISTS. In pixelGame, FNs and FPs are controlled by different player whose goal is to minimize their own utility function. FNs-player and FPs-player are designed with different strategies: One is to minimize FNs and the other is to minimize FPs. The utility function drives the evolution of the two participants in competition. We consider the Nash equilibrium of pixelGame as the optimal solution. In addition, we propose maximum information modulation (MIM) to highlight the tar-get information. MIM effectively focuses on the salient region including small targets. Extensive experiments on two standard public datasets prove the effectiveness of our method. Compared with other state-of-the-art methods, our method achieves better performance in terms of F1-measure (F1) and the intersection of union (IoU).
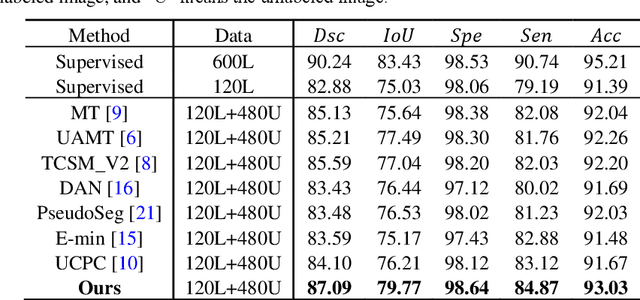
Collaborative Boundary-aware Context Encoding Networks for Error Map Prediction
Jun 25, 2020


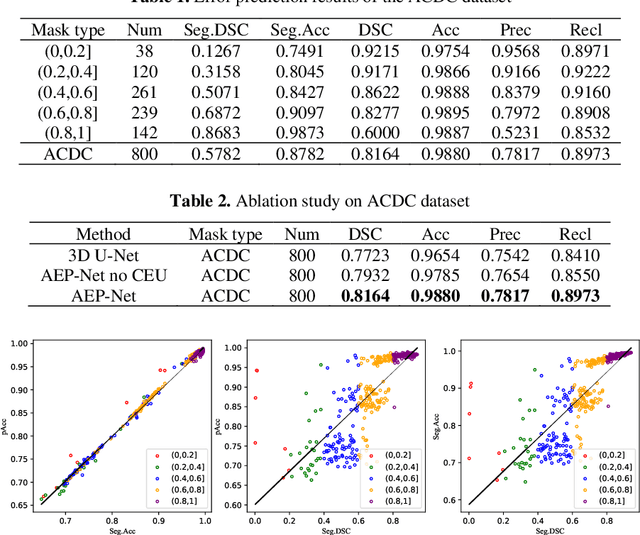
Medical image segmentation is usually regarded as one of the most important intermediate steps in clinical situations and medical imaging research. Thus, accurately assessing the segmentation quality of the automatically generated predictions is essential for guaranteeing the reliability of the results of the computer-assisted diagnosis (CAD). Many researchers apply neural networks to train segmentation quality regression models to estimate the segmentation quality of a new data cohort without labeled ground truth. Recently, a novel idea is proposed that transforming the segmentation quality assessment (SQA) problem intothe pixel-wise error map prediction task in the form of segmentation. However, the simple application of vanilla segmentation structures in medical image fails to detect some small and thin error regions of the auto-generated masks with complex anatomical structures. In this paper, we propose collaborative boundaryaware context encoding networks called AEP-Net for error prediction task. Specifically, we propose a collaborative feature transformation branch for better feature fusion between images and masks, and precise localization of error regions. Further, we propose a context encoding module to utilize the global predictor from the error map to enhance the feature representation and regularize the networks. We perform experiments on IBSR v2.0 dataset and ACDC dataset. The AEP-Net achieves an average DSC of 0.8358, 0.8164 for error prediction task,and shows a high Pearson correlation coefficient of 0.9873 between the actual segmentation accuracy and the predicted accuracy inferred from the predicted error map on IBSR v2.0 dataset, which verifies the efficacy of our AEP-Net.