 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Training-Free Framework for Video License Plate Tracking and Recognition with Only One-Shot
Aug 11, 2024
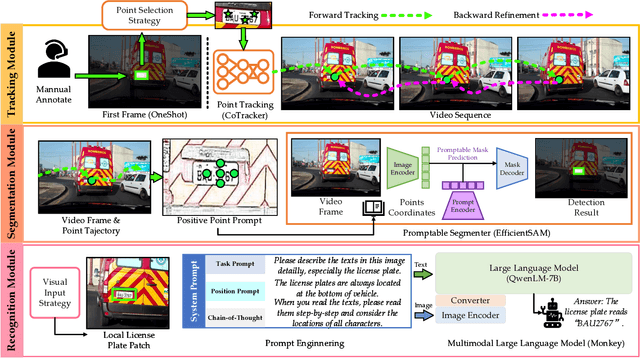
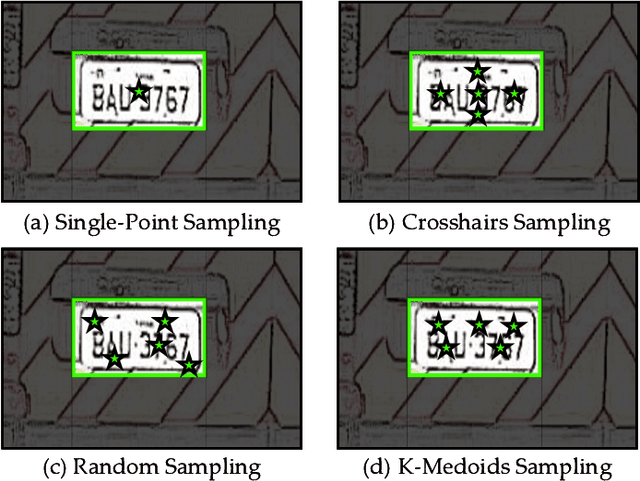
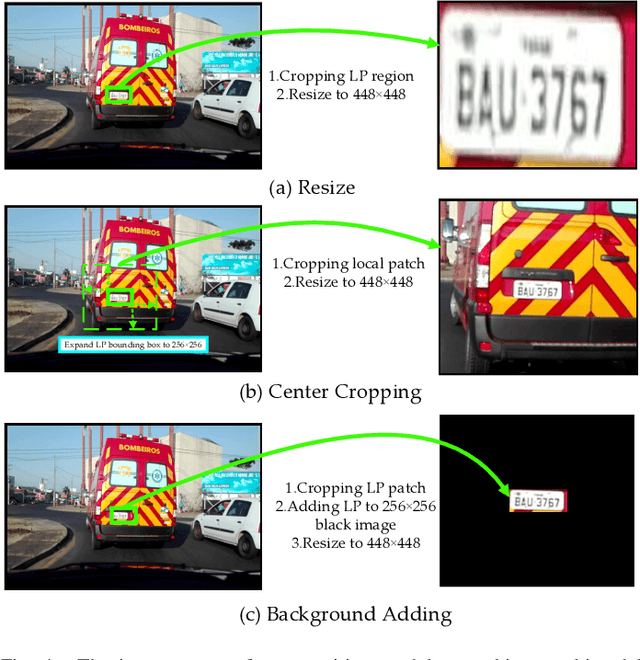
Traditional license plate detection and recognition models are often trained on closed datasets, limiting their ability to handle the diverse license plate formats across different regions. The emergence of large-scale pre-trained models has shown exceptional generalization capabilities, enabling few-shot and zero-shot learning. We propose OneShotLP, a training-free framework for video-based license plate detection and recognition, leveraging these advanced models. Starting with the license plate position in the first video frame, our method tracks this position across subsequent frames using a point tracking module, creating a trajectory of prompts. These prompts are input into a segmentation module that uses a promptable large segmentation model to generate local masks of the license plate regions. The segmented areas are then processed by multimodal large language models (MLLMs) for accurate license plate recognition. OneShotLP offers significant advantages, including the ability to function effectively without extensive training data and adaptability to various license plate styles. Experimental results on UFPR-ALPR and SSIG-SegPlate datasets demonstrate the superior accuracy of our approach compared to traditional methods. This highlights the potential of leveraging pre-trained models for diverse real-world applications in intelligent transportation systems. The code is available at https://github.com/Dinghaoxuan/OneShotLP.
SamLP: A Customized Segment Anything Model for License Plate Detection
Jan 12, 2024With the emergence of foundation model, this novel paradigm of deep learning has encouraged many powerful achievements in natural language processing and computer vision. There are many advantages of foundation model, such as excellent feature extraction power, mighty generalization ability, great few-shot and zero-shot learning capacity, etc. which are beneficial to vision tasks. As the unique identity of vehicle, different countries and regions have diverse license plate (LP) styles and appearances, and even different types of vehicles have different LPs. However, recent deep learning based license plate detectors are mainly trained on specific datasets, and these limited datasets constrain the effectiveness and robustness of LP detectors. To alleviate the negative impact of limited data, an attempt to exploit the advantages of foundation model is implement in this paper. We customize a vision foundation model, i.e. Segment Anything Model (SAM), for LP detection task and propose the first LP detector based on vision foundation model, named SamLP. Specifically, we design a Low-Rank Adaptation (LoRA) fine-tuning strategy to inject extra parameters into SAM and transfer SAM into LP detection task. And then, we further propose a promptable fine-tuning step to provide SamLP with prompatable segmentation capacity. The experiments show that our proposed SamLP achieves promising detection performance compared to other LP detectors. Meanwhile, the proposed SamLP has great few-shot and zero-shot learning ability, which shows the potential of transferring vision foundation model. The code is available at https://github.com/Dinghaoxuan/SamLP
The CLIP Model is Secretly an Image-to-Prompt Converter
May 22, 2023



The Stable Diffusion model is a prominent text-to-image generation model that relies on a text prompt as its input, which is encoded using the Contrastive Language-Image Pre-Training (CLIP). However, text prompts have limitations when it comes to incorporating implicit information from reference images. Existing methods have attempted to address this limitation by employing expensive training procedures involving millions of training samples for image-to-image generation. In contrast, this paper demonstrates that the CLIP model, as utilized in Stable Diffusion, inherently possesses the ability to instantaneously convert images into text prompts. Such an image-to-prompt conversion can be achieved by utilizing a linear projection matrix that is calculated in a closed form. Moreover, the paper showcases that this capability can be further enhanced by either utilizing a small amount of similar-domain training data (approximately 100 images) or incorporating several online training steps (around 30 iterations) on the reference images. By leveraging these approaches, the proposed method offers a simple and flexible solution to bridge the gap between images and text prompts. This methodology can be applied to various tasks such as image variation and image editing, facilitating more effective and seamless interaction between images and textual prompts.
Don't Stop Learning: Towards Continual Learning for the CLIP Model
Jul 20, 2022
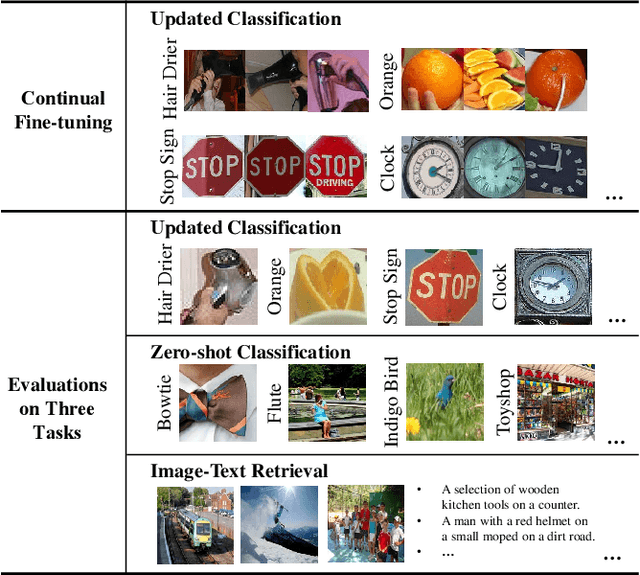
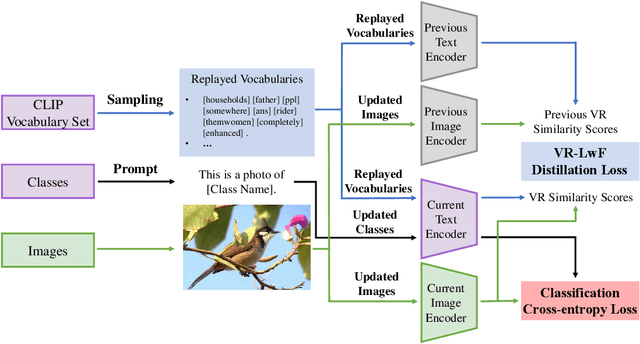
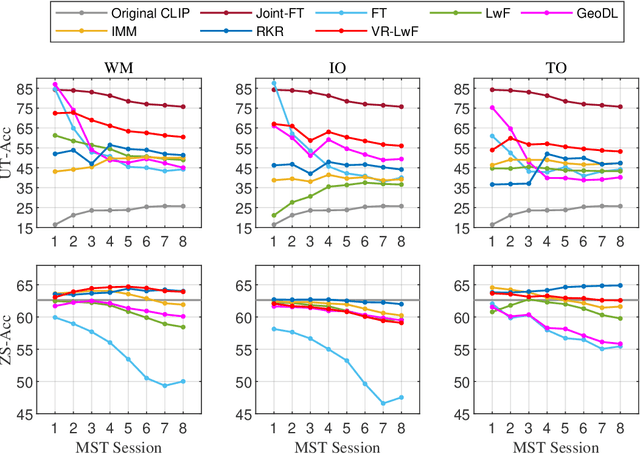
The Contrastive Language-Image Pre-training (CLIP) Model is a recently proposed large-scale pre-train model which attracts increasing attention in the computer vision community. Benefiting from its gigantic image-text training set, the CLIP model has learned outstanding capabilities in zero-shot learning and image-text matching. To boost the recognition performance of CLIP on some target visual concepts, it is often desirable to further update the CLIP model by fine-tuning some classes-of-interest on extra training data. This operation, however, raises an important concern: will the update hurt the zero-shot learning or image-text matching capability of the CLIP, i.e., the catastrophic forgetting issue? If yes, could existing continual learning algorithms be adapted to alleviate the risk of catastrophic forgetting? To answer these questions, this work conducts a systemic study on the continual learning issue of the CLIP model. We construct evaluation protocols to measure the impact of fine-tuning updates and explore different ways to upgrade existing continual learning methods to mitigate the forgetting issue of the CLIP model. Our study reveals the particular challenges of CLIP continual learning problem and lays a foundation for further researches. Moreover, we propose a new algorithm, dubbed Learning without Forgetting via Replayed Vocabulary (VR-LwF), which shows exact effectiveness for alleviating the forgetting issue of the CLIP model.