 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAndroid Coach: Improve Online Agentic Training Efficiency with Single State Multiple Actions
Apr 08, 2026Online reinforcement learning (RL) serves as an effective method for enhancing the capabilities of Android agents. However, guiding agents to learn through online interaction is prohibitively expensive due to the high latency of emulators and the sample inefficiency of existing RL algorithms. We identify a fundamental limitation in current approaches: the Single State Single Action paradigm, which updates the policy with one-to-one state-action pairs from online one-way rollouts without fully exploring each costly emulator state. In this paper, we propose Android Coach, a novel framework that shifts the training paradigm to Single State Multiple Actions, allowing the agent to sample and utilize multiple actions for a single online state. We enable this without additional emulator overhead by learning a critic that estimates action values. To ensure the critic serves as a reliable coach, we integrate a process reward model and introduce a group-wise advantage estimator based on the averaged critic outputs. Extensive experiments demonstrate the effectiveness and efficiency of Android Coach: it achieves 7.5% and 8.3% success rate improvements on AndroidLab and AndroidWorld over UI-TARS-1.5-7B, and attains 1.4x higher training efficiency than Single State Single Action methods PPO and GRPO at matched success rates.
Follow the Clues, Frame the Truth: Hybrid-evidential Deductive Reasoning in Open-Vocabulary Multimodal Emotion Recognition
Mar 17, 2026Open-Vocabulary Multimodal Emotion Recognition (OV-MER) is inherently challenging due to the ambiguity of equivocal multimodal cues, which often stem from distinct unobserved situational dynamics. While Multimodal Large Language Models (MLLMs) offer extensive semantic coverage, their performance is often bottlenecked by premature commitment to dominant data priors, resulting in suboptimal heuristics that overlook crucial, complementary affective cues across modalities. We argue that effective affective reasoning requires more than surface-level association; it necessitates reconstructing nuanced emotional states by synthesizing multiple evidence-grounded rationales that reconcile these observations from diverse latent perspectives. We introduce HyDRA, a Hybrid-evidential Deductive Reasoning Architecture that formalizes inference as a Propose-Verify-Decide protocol. To internalize this abductive process, we employ reinforcement learning with hierarchical reward shaping, aligning the reasoning trajectories with final task performance to ensure they best reconcile the observed multimodal cues. Systematic evaluations validate our design choices, with HyDRA consistently outperforming strong baselines--especially in ambiguous or conflicting scenarios--while providing interpretable, diagnostic evidence traces.
Lightweight Ac Arc Fault Diagnosis via Fourier Transform Inspired Multi-frequency Neural Network
Oct 30, 2025



Lightweight online detection of series arc faults is critically needed in residential and industrial power systems to prevent electrical fires. Existing diagnostic methods struggle to achieve both rapid response and robust accuracy under resource-constrained conditions. To overcome the challenge, this work suggests leveraging a multi-frequency neural network named MFNN, embedding prior physical knowledge into the network. Inspired by arcing current curve and the Fourier decomposition analysis, we create an adaptive activation function with super-expressiveness, termed EAS, and a novel network architecture with branch networks to help MFNN extract features with multiple frequencies. In our experiments, eight advanced arc fault diagnosis models across an experimental dataset with multiple sampling times and multi-level noise are used to demonstrate the superiority of MFNN. The corresponding experiments show: 1) The MFNN outperforms other models in arc fault location, befitting from signal decomposition of branch networks. 2) The noise immunity of MFNN is much better than that of other models, achieving 14.51% over LCNN and 16.3% over BLS in test accuracy when SNR=-9. 3) EAS and the network architecture contribute to the excellent performance of MFNN.
Bi-Residual Neural Network based Synchronous Motor Electrical Faults Diagnosis: Intra-link Layer Design for High-frequency Features
May 29, 2025



In practical resource-constrained environments, efficiently extracting the potential high-frequency fault-critical information is an inherent problem. To overcome this problem, this work suggests leveraging a bi-residual neural network named Bi-ResNet to extract the inner spatial-temporal high-frequency features using embedded spatial-temporal convolution blocks and intra-link layers. It can be considered as embedding a high-frequency extractor into networks without adding any parameters, helping shallow networks achieve the performance of deep networks. In our experiments, five advanced CNN-based neural networks and two baselines across a real-life dataset are utilized for synchronous motor electrical fault diagnosis to demonstrate the effectiveness of Bi-ResNet including one analytical, comparative, and ablation experiments. The corresponding experiments show: 1) The Bi-ResNet can perform better on low-resolution noisy data. 2) The proposed intra-links can help high-frequency components extraction and location from raw data. 3) There is a trade-off between intra-link number and input data complexity.
TOMATO: Assessing Visual Temporal Reasoning Capabilities in Multimodal Foundation Models
Oct 30, 2024



Existing benchmarks often highlight the remarkable performance achieved by state-of-the-art Multimodal Foundation Models (MFMs) in leveraging temporal context for video understanding. However, how well do the models truly perform visual temporal reasoning? Our study of existing benchmarks shows that this capability of MFMs is likely overestimated as many questions can be solved by using a single, few, or out-of-order frames. To systematically examine current visual temporal reasoning tasks, we propose three principles with corresponding metrics: (1) Multi-Frame Gain, (2) Frame Order Sensitivity, and (3) Frame Information Disparity. Following these principles, we introduce TOMATO, Temporal Reasoning Multimodal Evaluation, a novel benchmark crafted to rigorously assess MFMs' temporal reasoning capabilities in video understanding. TOMATO comprises 1,484 carefully curated, human-annotated questions spanning six tasks (i.e., action count, direction, rotation, shape & trend, velocity & frequency, and visual cues), applied to 1,417 videos, including 805 self-recorded and -generated videos, that encompass human-centric, real-world, and simulated scenarios. Our comprehensive evaluation reveals a human-model performance gap of 57.3% with the best-performing model. Moreover, our in-depth analysis uncovers more fundamental limitations beyond this gap in current MFMs. While they can accurately recognize events in isolated frames, they fail to interpret these frames as a continuous sequence. We believe TOMATO will serve as a crucial testbed for evaluating the next-generation MFMs and as a call to the community to develop AI systems capable of comprehending human world dynamics through the video modality.
EZIGen: Enhancing zero-shot subject-driven image generation with precise subject encoding and decoupled guidance
Sep 12, 2024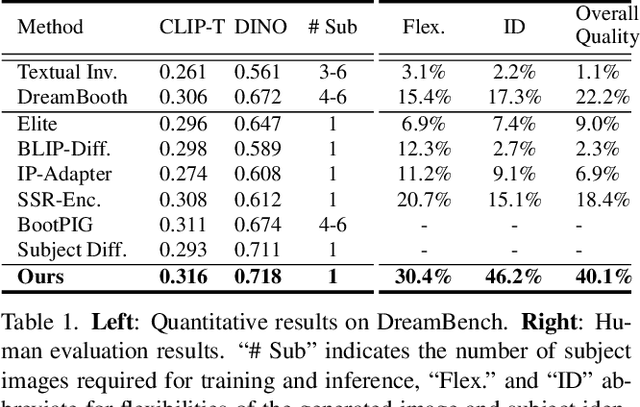

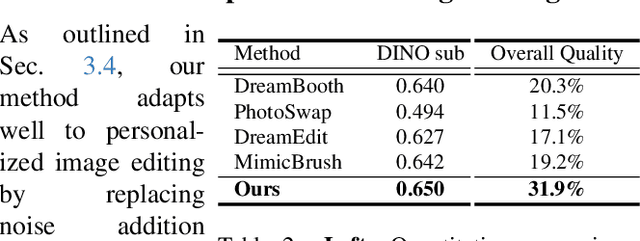

Zero-shot subject-driven image generation aims to produce images that incorporate a subject from a given example image. The challenge lies in preserving the subject's identity while aligning with the text prompt, which often requires modifying certain aspects of the subject's appearance. Despite advancements in diffusion model based methods, existing approaches still struggle to balance identity preservation with text prompt alignment. In this study, we conducted an in-depth investigation into this issue and uncovered key insights for achieving effective identity preservation while maintaining a strong balance. Our key findings include: (1) the design of the subject image encoder significantly impacts identity preservation quality, and (2) generating an initial layout is crucial for both text alignment and identity preservation. Building on these insights, we introduce a new approach called EZIGen, which employs two main strategies: a carefully crafted subject image Encoder based on the UNet architecture of the pretrained Stable Diffusion model to ensure high-quality identity transfer, following a process that decouples the guidance stages and iteratively refines the initial image layout. Through these strategies, EZIGen achieves state-of-the-art results on multiple subject-driven benchmarks with a unified model and 100 times less training data.
The CLIP Model is Secretly an Image-to-Prompt Converter
May 22, 2023



The Stable Diffusion model is a prominent text-to-image generation model that relies on a text prompt as its input, which is encoded using the Contrastive Language-Image Pre-Training (CLIP). However, text prompts have limitations when it comes to incorporating implicit information from reference images. Existing methods have attempted to address this limitation by employing expensive training procedures involving millions of training samples for image-to-image generation. In contrast, this paper demonstrates that the CLIP model, as utilized in Stable Diffusion, inherently possesses the ability to instantaneously convert images into text prompts. Such an image-to-prompt conversion can be achieved by utilizing a linear projection matrix that is calculated in a closed form. Moreover, the paper showcases that this capability can be further enhanced by either utilizing a small amount of similar-domain training data (approximately 100 images) or incorporating several online training steps (around 30 iterations) on the reference images. By leveraging these approaches, the proposed method offers a simple and flexible solution to bridge the gap between images and text prompts. This methodology can be applied to various tasks such as image variation and image editing, facilitating more effective and seamless interaction between images and textual prompts.
How Close is ChatGPT to Human Experts? Comparison Corpus, Evaluation, and Detection
Jan 18, 2023The introduction of ChatGPT has garnered widespread attention in both academic and industrial communities. ChatGPT is able to respond effectively to a wide range of human questions, providing fluent and comprehensive answers that significantly surpass previous public chatbots in terms of security and usefulness. On one hand, people are curious about how ChatGPT is able to achieve such strength and how far it is from human experts. On the other hand, people are starting to worry about the potential negative impacts that large language models (LLMs) like ChatGPT could have on society, such as fake news, plagiarism, and social security issues. In this work, we collected tens of thousands of comparison responses from both human experts and ChatGPT, with questions ranging from open-domain, financial, medical, legal, and psychological areas. We call the collected dataset the Human ChatGPT Comparison Corpus (HC3). Based on the HC3 dataset, we study the characteristics of ChatGPT's responses, the differences and gaps from human experts, and future directions for LLMs. We conducted comprehensive human evaluations and linguistic analyses of ChatGPT-generated content compared with that of humans, where many interesting results are revealed. After that, we conduct extensive experiments on how to effectively detect whether a certain text is generated by ChatGPT or humans. We build three different detection systems, explore several key factors that influence their effectiveness, and evaluate them in different scenarios. The dataset, code, and models are all publicly available at https://github.com/Hello-SimpleAI/chatgpt-comparison-detection.
Position-Aware Relation Learning for RGB-Thermal Salient Object Detection
Sep 21, 2022
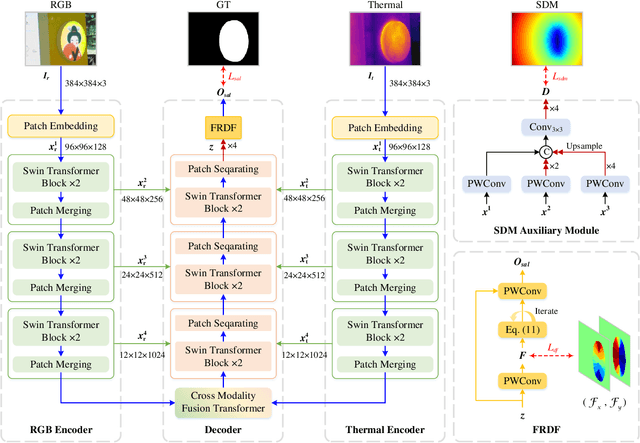
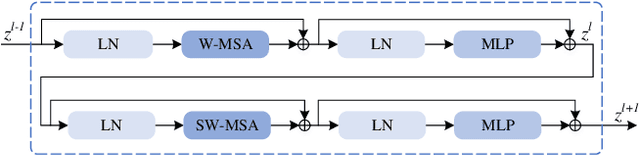

RGB-Thermal salient object detection (SOD) combines two spectra to segment visually conspicuous regions in images. Most existing methods use boundary maps to learn the sharp boundary. These methods ignore the interactions between isolated boundary pixels and other confident pixels, leading to sub-optimal performance. To address this problem,we propose a position-aware relation learning network (PRLNet) for RGB-T SOD based on swin transformer. PRLNet explores the distance and direction relationships between pixels to strengthen intra-class compactness and inter-class separation, generating salient object masks with clear boundaries and homogeneous regions. Specifically, we develop a novel signed distance map auxiliary module (SDMAM) to improve encoder feature representation, which takes into account the distance relation of different pixels in boundary neighborhoods. Then, we design a feature refinement approach with directional field (FRDF), which rectifies features of boundary neighborhood by exploiting the features inside salient objects. FRDF utilizes the directional information between object pixels to effectively enhance the intra-class compactness of salient regions. In addition, we constitute a pure transformer encoder-decoder network to enhance multispectral feature representation for RGB-T SOD. Finally, we conduct quantitative and qualitative experiments on three public benchmark datasets.The results demonstrate that our proposed method outperforms the state-of-the-art methods.
Seeking Subjectivity in Visual Emotion Distribution Learning
Jul 25, 2022
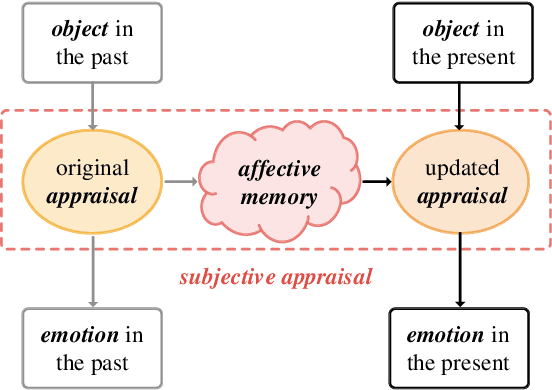


Visual Emotion Analysis (VEA), which aims to predict people's emotions towards different visual stimuli, has become an attractive research topic recently. Rather than a single label classification task, it is more rational to regard VEA as a Label Distribution Learning (LDL) problem by voting from different individuals. Existing methods often predict visual emotion distribution in a unified network, neglecting the inherent subjectivity in its crowd voting process. In psychology, the \textit{Object-Appraisal-Emotion} model has demonstrated that each individual's emotion is affected by his/her subjective appraisal, which is further formed by the affective memory. Inspired by this, we propose a novel \textit{Subjectivity Appraise-and-Match Network (SAMNet)} to investigate the subjectivity in visual emotion distribution. To depict the diversity in crowd voting process, we first propose the \textit{Subjectivity Appraising} with multiple branches, where each branch simulates the emotion evocation process of a specific individual. Specifically, we construct the affective memory with an attention-based mechanism to preserve each individual's unique emotional experience. A subjectivity loss is further proposed to guarantee the divergence between different individuals. Moreover, we propose the \textit{Subjectivity Matching} with a matching loss, aiming at assigning unordered emotion labels to ordered individual predictions in a one-to-one correspondence with the Hungarian algorithm. Extensive experiments and comparisons are conducted on public visual emotion distribution datasets, and the results demonstrate that the proposed SAMNet consistently outperforms the state-of-the-art methods. Ablation study verifies the effectiveness of our method and visualization proves its interpretability.