 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInference-Time Scaling for Visual AutoRegressive modeling by Searching Representative Samples
Jan 12, 2026While inference-time scaling has significantly enhanced generative quality in large language and diffusion models, its application to vector-quantized (VQ) visual autoregressive modeling (VAR) remains unexplored. We introduce VAR-Scaling, the first general framework for inference-time scaling in VAR, addressing the critical challenge of discrete latent spaces that prohibit continuous path search. We find that VAR scales exhibit two distinct pattern types: general patterns and specific patterns, where later-stage specific patterns conditionally optimize early-stage general patterns. To overcome the discrete latent space barrier in VQ models, we map sampling spaces to quasi-continuous feature spaces via kernel density estimation (KDE), where high-density samples approximate stable, high-quality solutions. This transformation enables effective navigation of sampling distributions. We propose a density-adaptive hybrid sampling strategy: Top-k sampling focuses on high-density regions to preserve quality near distribution modes, while Random-k sampling explores low-density areas to maintain diversity and prevent premature convergence. Consequently, VAR-Scaling optimizes sample fidelity at critical scales to enhance output quality. Experiments in class-conditional and text-to-image evaluations demonstrate significant improvements in inference process. The code is available at https://github.com/WD7ang/VAR-Scaling.
Composable Strategy Framework with Integrated Video-Text based Large Language Models for Heart Failure Assessment
Feb 23, 2025



Heart failure is one of the leading causes of death worldwide, with millons of deaths each year, according to data from the World Health Organization (WHO) and other public health agencies. While significant progress has been made in the field of heart failure, leading to improved survival rates and improvement of ejection fraction, there remains substantial unmet needs, due to the complexity and multifactorial characteristics. Therefore, we propose a composable strategy framework for assessment and treatment optimization in heart failure. This framework simulates the doctor-patient consultation process and leverages multi-modal algorithms to analyze a range of data, including video, physical examination, text results as well as medical history. By integrating these various data sources, our framework offers a more holistic evaluation and optimized treatment plan for patients. Our results demonstrate that this multi-modal approach outperforms single-modal artificial intelligence (AI) algorithms in terms of accuracy in heart failure (HF) prognosis prediction. Through this method, we can further evaluate the impact of various pathological indicators on HF prognosis,providing a more comprehensive evaluation.
Self-Reasoning Assistant Learning for non-Abelian Gauge Fields Design
Jul 23, 2024



Non-Abelian braiding has attracted substantial attention because of its pivotal role in describing the exchange behaviour of anyons, in which the input and outcome of non-Abelian braiding are connected by a unitary matrix. Implementing braiding in a classical system can assist the experimental investigation of non-Abelian physics. However, the design of non-Abelian gauge fields faces numerous challenges stemmed from the intricate interplay of group structures, Lie algebra properties, representation theory, topology, and symmetry breaking. The extreme diversity makes it a powerful tool for the study of condensed matter physics. Whereas the widely used artificial intelligence with data-driven approaches has greatly promoted the development of physics, most works are limited on the data-to-data design. Here we propose a self-reasoning assistant learning framework capable of directly generating non-Abelian gauge fields. This framework utilizes the forward diffusion process to capture and reproduce the complex patterns and details inherent in the target distribution through continuous transformation. Then the reverse diffusion process is used to make the generated data closer to the distribution of the original situation. Thus, it owns strong self-reasoning capabilities, allowing to automatically discover the feature representation and capture more subtle relationships from the dataset. Moreover, the self-reasoning eliminates the need for manual feature engineering and simplifies the process of model building. Our framework offers a disruptive paradigm shift to parse complex physical processes, automatically uncovering patterns from massive datasets.
Deep learning for the design of non-Hermitian topolectrical circuits
Feb 15, 2024



Non-Hermitian topological phases can produce some remarkable properties, compared with their Hermitian counterpart, such as the breakdown of conventional bulk-boundary correspondence and the non-Hermitian topological edge mode. Here, we introduce several algorithms with multi-layer perceptron (MLP), and convolutional neural network (CNN) in the field of deep learning, to predict the winding of eigenvalues non-Hermitian Hamiltonians. Subsequently, we use the smallest module of the periodic circuit as one unit to construct high-dimensional circuit data features. Further, we use the Dense Convolutional Network (DenseNet), a type of convolutional neural network that utilizes dense connections between layers to design a non-Hermitian topolectrical Chern circuit, as the DenseNet algorithm is more suitable for processing high-dimensional data. Our results demonstrate the effectiveness of the deep learning network in capturing the global topological characteristics of a non-Hermitian system based on training data.
Seeking Subjectivity in Visual Emotion Distribution Learning
Jul 25, 2022
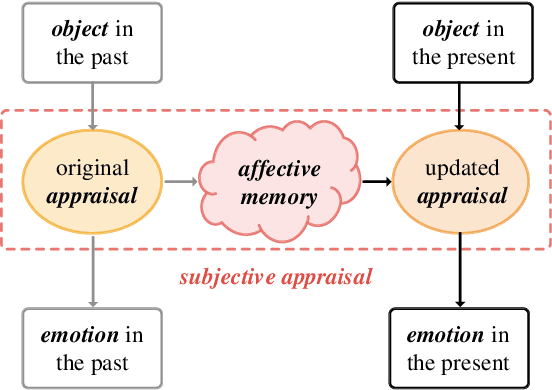


Visual Emotion Analysis (VEA), which aims to predict people's emotions towards different visual stimuli, has become an attractive research topic recently. Rather than a single label classification task, it is more rational to regard VEA as a Label Distribution Learning (LDL) problem by voting from different individuals. Existing methods often predict visual emotion distribution in a unified network, neglecting the inherent subjectivity in its crowd voting process. In psychology, the \textit{Object-Appraisal-Emotion} model has demonstrated that each individual's emotion is affected by his/her subjective appraisal, which is further formed by the affective memory. Inspired by this, we propose a novel \textit{Subjectivity Appraise-and-Match Network (SAMNet)} to investigate the subjectivity in visual emotion distribution. To depict the diversity in crowd voting process, we first propose the \textit{Subjectivity Appraising} with multiple branches, where each branch simulates the emotion evocation process of a specific individual. Specifically, we construct the affective memory with an attention-based mechanism to preserve each individual's unique emotional experience. A subjectivity loss is further proposed to guarantee the divergence between different individuals. Moreover, we propose the \textit{Subjectivity Matching} with a matching loss, aiming at assigning unordered emotion labels to ordered individual predictions in a one-to-one correspondence with the Hungarian algorithm. Extensive experiments and comparisons are conducted on public visual emotion distribution datasets, and the results demonstrate that the proposed SAMNet consistently outperforms the state-of-the-art methods. Ablation study verifies the effectiveness of our method and visualization proves its interpretability.
SOLVER: Scene-Object Interrelated Visual Emotion Reasoning Network
Oct 24, 2021
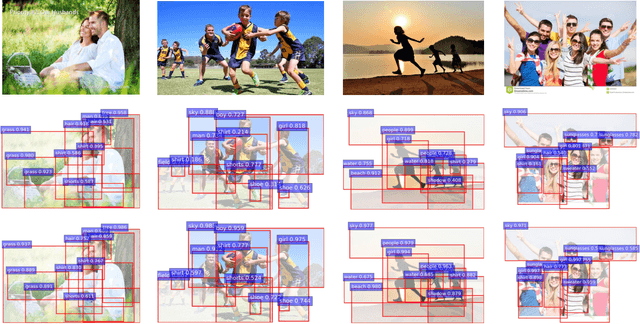


Visual Emotion Analysis (VEA) aims at finding out how people feel emotionally towards different visual stimuli, which has attracted great attention recently with the prevalence of sharing images on social networks. Since human emotion involves a highly complex and abstract cognitive process, it is difficult to infer visual emotions directly from holistic or regional features in affective images. It has been demonstrated in psychology that visual emotions are evoked by the interactions between objects as well as the interactions between objects and scenes within an image. Inspired by this, we propose a novel Scene-Object interreLated Visual Emotion Reasoning network (SOLVER) to predict emotions from images. To mine the emotional relationships between distinct objects, we first build up an Emotion Graph based on semantic concepts and visual features. Then, we conduct reasoning on the Emotion Graph using Graph Convolutional Network (GCN), yielding emotion-enhanced object features. We also design a Scene-Object Fusion Module to integrate scenes and objects, which exploits scene features to guide the fusion process of object features with the proposed scene-based attention mechanism. Extensive experiments and comparisons are conducted on eight public visual emotion datasets, and the results demonstrate that the proposed SOLVER consistently outperforms the state-of-the-art methods by a large margin. Ablation studies verify the effectiveness of our method and visualizations prove its interpretability, which also bring new insight to explore the mysteries in VEA. Notably, we further discuss SOLVER on three other potential datasets with extended experiments, where we validate the robustness of our method and notice some limitations of it.
* Accepted by TIP
Stimuli-Aware Visual Emotion Analysis
Sep 04, 2021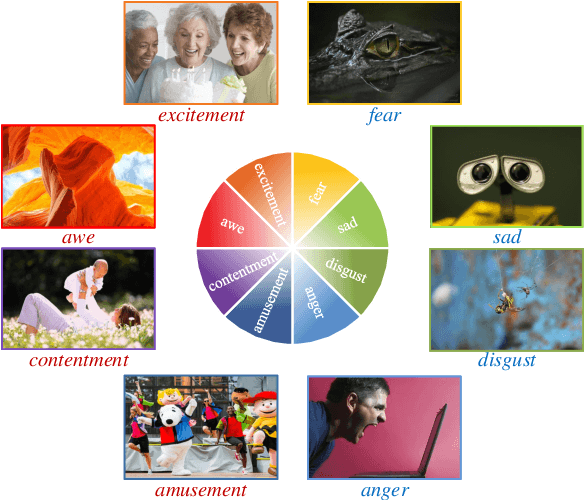
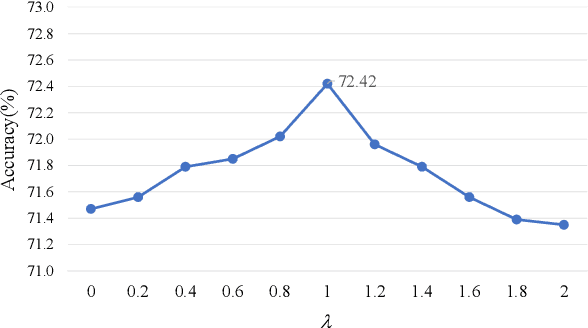

Visual emotion analysis (VEA) has attracted great attention recently, due to the increasing tendency of expressing and understanding emotions through images on social networks. Different from traditional vision tasks, VEA is inherently more challenging since it involves a much higher level of complexity and ambiguity in human cognitive process. Most of the existing methods adopt deep learning techniques to extract general features from the whole image, disregarding the specific features evoked by various emotional stimuli. Inspired by the \textit{Stimuli-Organism-Response (S-O-R)} emotion model in psychological theory, we proposed a stimuli-aware VEA method consisting of three stages, namely stimuli selection (S), feature extraction (O) and emotion prediction (R). First, specific emotional stimuli (i.e., color, object, face) are selected from images by employing the off-the-shelf tools. To the best of our knowledge, it is the first time to introduce stimuli selection process into VEA in an end-to-end network. Then, we design three specific networks, i.e., Global-Net, Semantic-Net and Expression-Net, to extract distinct emotional features from different stimuli simultaneously. Finally, benefiting from the inherent structure of Mikel's wheel, we design a novel hierarchical cross-entropy loss to distinguish hard false examples from easy ones in an emotion-specific manner. Experiments demonstrate that the proposed method consistently outperforms the state-of-the-art approaches on four public visual emotion datasets. Ablation study and visualizations further prove the validity and interpretability of our method.
* Accepted by TIP
A Circular-Structured Representation for Visual Emotion Distribution Learning
Jun 28, 2021
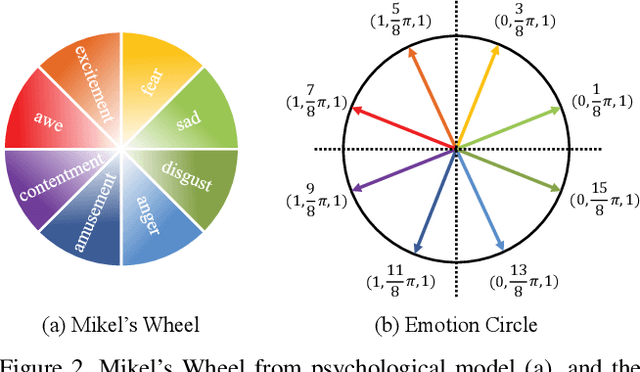
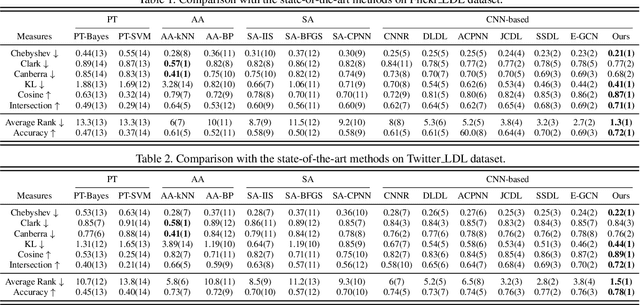
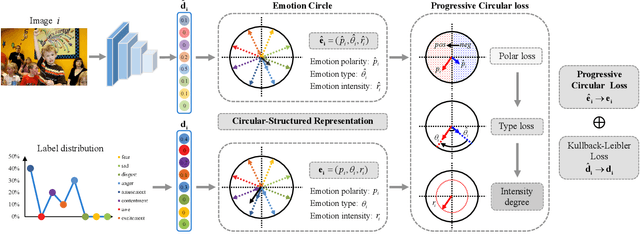
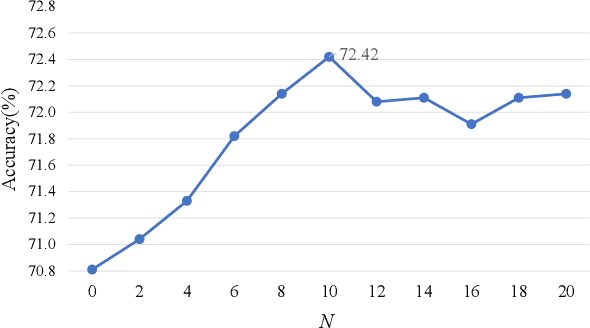
Visual Emotion Analysis (VEA) has attracted increasing attention recently with the prevalence of sharing images on social networks. Since human emotions are ambiguous and subjective, it is more reasonable to address VEA in a label distribution learning (LDL) paradigm rather than a single-label classification task. Different from other LDL tasks, there exist intrinsic relationships between emotions and unique characteristics within them, as demonstrated in psychological theories. Inspired by this, we propose a well-grounded circular-structured representation to utilize the prior knowledge for visual emotion distribution learning. To be specific, we first construct an Emotion Circle to unify any emotional state within it. On the proposed Emotion Circle, each emotion distribution is represented with an emotion vector, which is defined with three attributes (i.e., emotion polarity, emotion type, emotion intensity) as well as two properties (i.e., similarity, additivity). Besides, we design a novel Progressive Circular (PC) loss to penalize the dissimilarities between predicted emotion vector and labeled one in a coarse-to-fine manner, which further boosts the learning process in an emotion-specific way. Extensive experiments and comparisons are conducted on public visual emotion distribution datasets, and the results demonstrate that the proposed method outperforms the state-of-the-art methods.
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

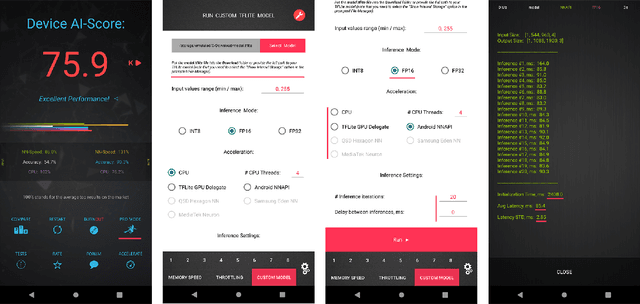
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Image Fine-grained Inpainting
Feb 07, 2020
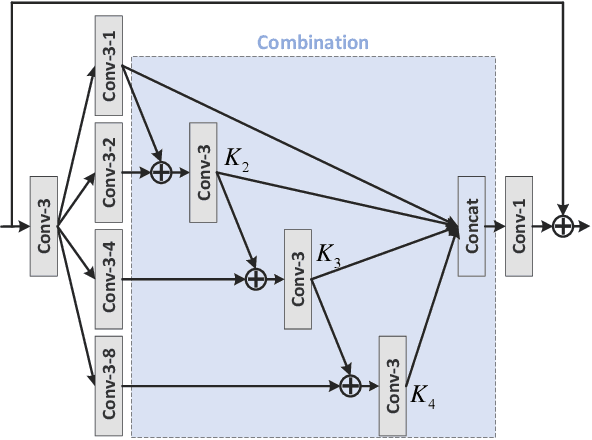
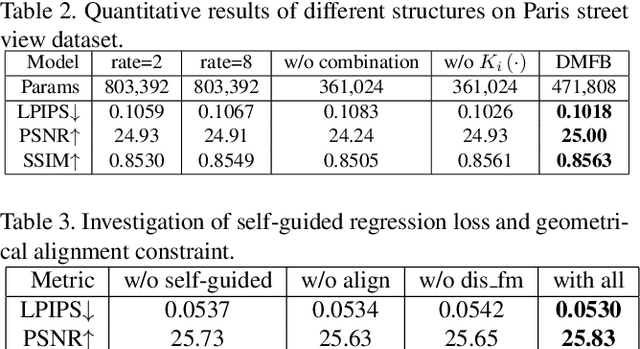
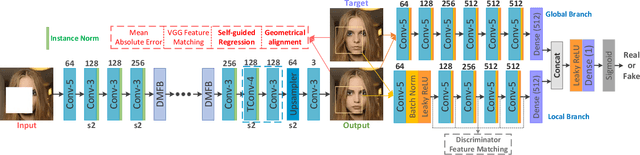
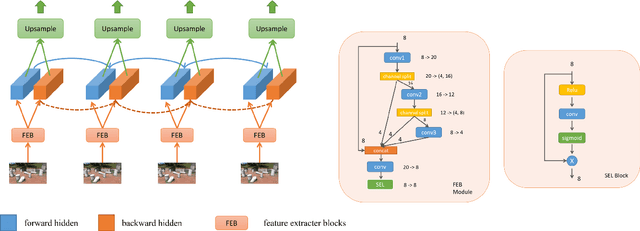
Image inpainting techniques have shown promising improvement with the assistance of generative adversarial networks (GANs) recently. However, most of them often suffered from completed results with unreasonable structure or blurriness. To mitigate this problem, in this paper, we present a one-stage model that utilizes dense combinations of dilated convolutions to obtain larger and more effective receptive fields. Benefited from the property of this network, we can more easily recover large regions in an incomplete image. To better train this efficient generator, except for frequently-used VGG feature matching loss, we design a novel self-guided regression loss for concentrating on uncertain areas and enhancing the semantic details. Besides, we devise a geometrical alignment constraint item to compensate for the pixel-based distance between prediction features and ground-truth ones. We also employ a discriminator with local and global branches to ensure local-global contents consistency. To further improve the quality of generated images, discriminator feature matching on the local branch is introduced, which dynamically minimizes the similarity of intermediate features between synthetic and ground-truth patches. Extensive experiments on several public datasets demonstrate that our approach outperforms current state-of-the-art methods. Code is available at~\url{https://github.com/Zheng222/DMFN}.