 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePaint: Inpainting using Denoising Diffusion Probabilistic Models
Feb 07, 2022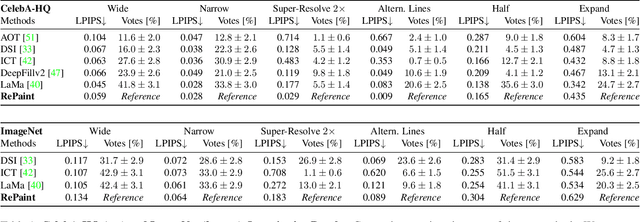
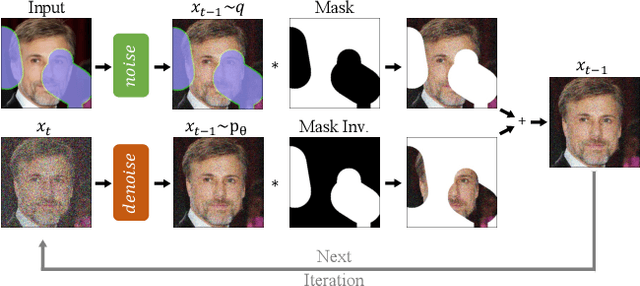


Free-form inpainting is the task of adding new content to an image in the regions specified by an arbitrary binary mask. Most existing approaches train for a certain distribution of masks, which limits their generalization capabilities to unseen mask types. Furthermore, training with pixel-wise and perceptual losses often leads to simple textural extensions towards the missing areas instead of semantically meaningful generation. In this work, we propose RePaint: A Denoising Diffusion Probabilistic Model (DDPM) based inpainting approach that is applicable to even extreme masks. We employ a pretrained unconditional DDPM as the generative prior. To condition the generation process, we only alter the reverse diffusion iterations by sampling the unmasked regions using the given image information. Since this technique does not modify or condition the original DDPM network itself, the model produces high-quality and diverse output images for any inpainting form. We validate our method for both faces and general-purpose image inpainting using standard and extreme masks. RePaint outperforms state-of-the-art Autoregressive, and GAN approaches for at least five out of six mask distributions. Github Repository: git.io/RePaint
Real-Time Video Super-Resolution on Smartphones with Deep Learning, Mobile AI 2021 Challenge: Report
May 17, 2021

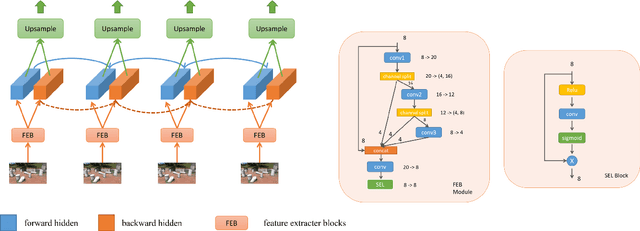
Video super-resolution has recently become one of the most important mobile-related problems due to the rise of video communication and streaming services. While many solutions have been proposed for this task, the majority of them are too computationally expensive to run on portable devices with limited hardware resources. To address this problem, we introduce the first Mobile AI challenge, where the target is to develop an end-to-end deep learning-based video super-resolution solutions that can achieve a real-time performance on mobile GPUs. The participants were provided with the REDS dataset and trained their models to do an efficient 4X video upscaling. The runtime of all models was evaluated on the OPPO Find X2 smartphone with the Snapdragon 865 SoC capable of accelerating floating-point networks on its Adreno GPU. The proposed solutions are fully compatible with any mobile GPU and can upscale videos to HD resolution at up to 80 FPS while demonstrating high fidelity results. A detailed description of all models developed in the challenge is provided in this paper.
Self-Supervised Shadow Removal
Oct 22, 2020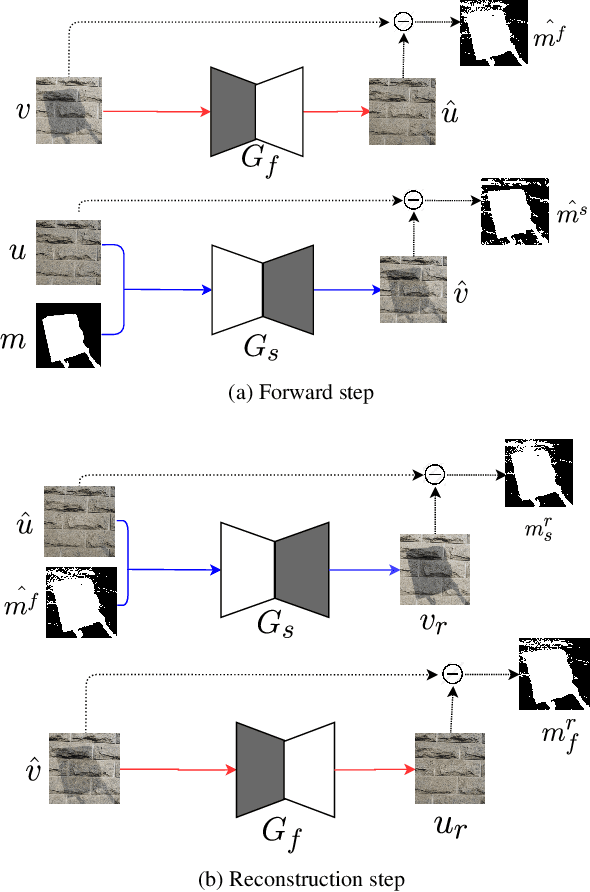



Shadow removal is an important computer vision task aiming at the detection and successful removal of the shadow produced by an occluded light source and a photo-realistic restoration of the image contents. Decades of re-search produced a multitude of hand-crafted restoration techniques and, more recently, learned solutions from shad-owed and shadow-free training image pairs. In this work,we propose an unsupervised single image shadow removal solution via self-supervised learning by using a conditioned mask. In contrast to existing literature, we do not require paired shadowed and shadow-free images, instead we rely on self-supervision and jointly learn deep models to remove and add shadows to images. We validate our approach on the recently introduced ISTD and USR datasets. We largely improve quantitatively and qualitatively over the compared methods and set a new state-of-the-art performance in single image shadow removal.
Unsupervised Multimodal Video-to-Video Translation via Self-Supervised Learning
Apr 14, 2020
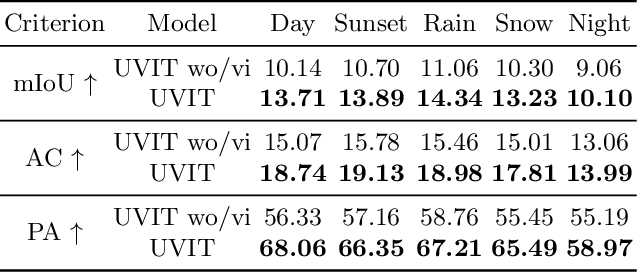
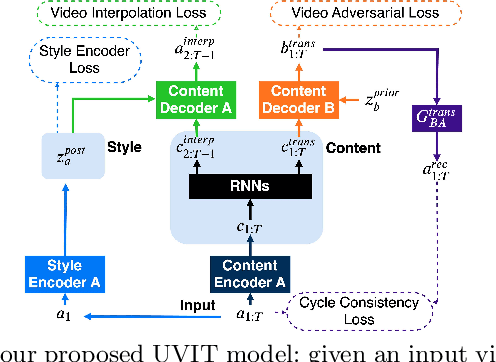

Existing unsupervised video-to-video translation methods fail to produce translated videos which are frame-wise realistic, semantic information preserving and video-level consistent. In this work, we propose UVIT, a novel unsupervised video-to-video translation model. Our model decomposes the style and the content, uses the specialized encoder-decoder structure and propagates the inter-frame information through bidirectional recurrent neural network (RNN) units. The style-content decomposition mechanism enables us to achieve style consistent video translation results as well as provides us with a good interface for modality flexible translation. In addition, by changing the input frames and style codes incorporated in our translation, we propose a video interpolation loss, which captures temporal information within the sequence to train our building blocks in a self-supervised manner. Our model can produce photo-realistic, spatio-temporal consistent translated videos in a multimodal way. Subjective and objective experimental results validate the superiority of our model over existing methods. More details can be found on our project website: https://uvit.netlify.com
Multi-View Dynamic Facial Action Unit Detection
Aug 20, 2018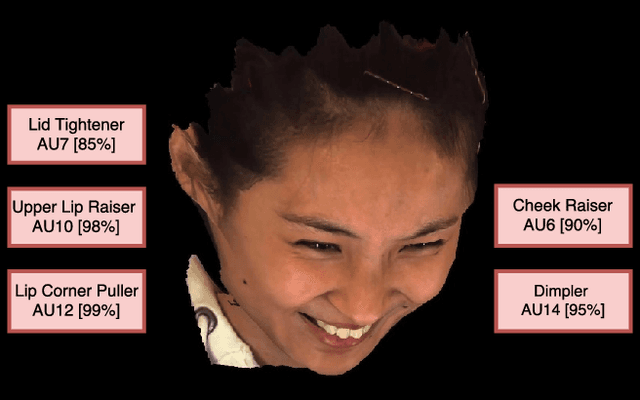
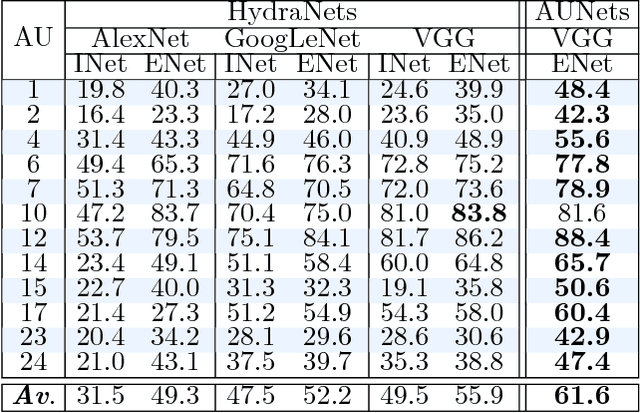
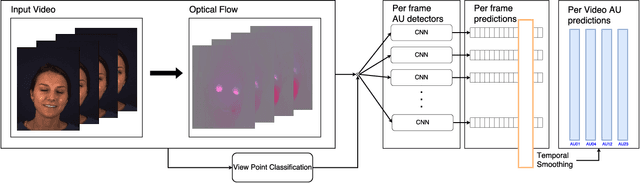
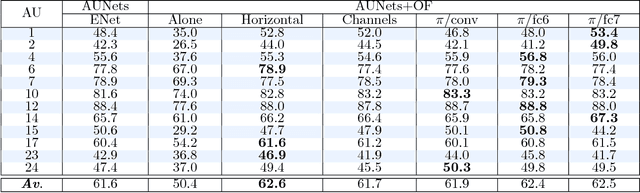
We propose a novel convolutional neural network approach to address the fine-grained recognition problem of multi-view dynamic facial action unit detection. We leverage recent gains in large-scale object recognition by formulating the task of predicting the presence or absence of a specific action unit in a still image of a human face as holistic classification. We then explore the design space of our approach by considering both shared and independent representations for separate action units, and also different CNN architectures for combining color and motion information. We then move to the novel setup of the FERA 2017 Challenge, in which we propose a multi-view extension of our approach that operates by first predicting the viewpoint from which the video was taken, and then evaluating an ensemble of action unit detectors that were trained for that specific viewpoint. Our approach is holistic, efficient, and modular, since new action units can be easily included in the overall system. Our approach significantly outperforms the baseline of the FERA 2017 Challenge, with an absolute improvement of 14% on the F1-metric. Additionally, it compares favorably against the winner of the FERA 2017 challenge. Code source is available at https://github.com/BCV-Uniandes/AUNets.