 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSDE-Driven Spatio-Temporal Hypergraph Neural Networks for Irregular Longitudinal fMRI Connectome Modeling in Alzheimer's Disease
Mar 20, 2026Longitudinal neuroimaging is essential for modeling disease progression in Alzheimer's disease (AD), yet irregular sampling and missing visits pose substantial challenges for learning reliable temporal representations. To address this challenge, we propose SDE-HGNN, a stochastic differential equation (SDE)-driven spatio-temporal hypergraph neural network for irregular longitudinal fMRI connectome modeling. The framework first employs an SDE-based reconstruction module to recover continuous latent trajectories from irregular observations. Based on these reconstructed representations, dynamic hypergraphs are constructed to capture higher-order interactions among brain regions over time. To further model temporal evolution, hypergraph convolution parameters evolve through SDE-controlled recurrent dynamics conditioned on inter-scan intervals, enabling disease-stage-adaptive connectivity modeling. We also incorporate a sparsity-based importance learning mechanism to identify salient brain regions and discriminative connectivity patterns. Extensive experiments on the OASIS-3 and ADNI cohorts demonstrate consistent improvements over state-of-the-art graph and hypergraph baselines in AD progression prediction. The source code is available at https://anonymous.4open.science/r/SDE-HGNN-017F.
Brenier Isotonic Regression
Mar 11, 2026Isotonic regression (IR) is shape-constrained regression to maintain a univariate fitting curve non-decreasing, which has numerous applications including single-index models and probability calibration. When it comes to multi-output regression, the classical IR is no longer applicable because the monotonicity is not readily extendable. We consider a novel multi-output regression problem where a regression function is \emph{cyclically monotone}. Roughly speaking, a cyclically monotone function is the gradient of some convex potential. Whereas enforcing cyclic monotonicity is apparently challenging, we leverage the fact that Kantorovich's optimal transport (OT) always yields a cyclically monotone coupling as an optimal solution. This perspective naturally allows us to interpret a regression function and the convex potential as a link function in generalized linear models and Brenier's potential in OT, respectively, and hence we call this IR extension \emph{Brenier isotonic regression}. We demonstrate experiments with probability calibration and generalized linear models. In particular, IR outperforms many famous baselines in probability calibration robustly.
AgentDropoutV2: Optimizing Information Flow in Multi-Agent Systems via Test-Time Rectify-or-Reject Pruning
Feb 26, 2026While Multi-Agent Systems (MAS) excel in complex reasoning, they suffer from the cascading impact of erroneous information generated by individual participants. Current solutions often resort to rigid structural engineering or expensive fine-tuning, limiting their deployability and adaptability. We propose AgentDropoutV2, a test-time rectify-or-reject pruning framework designed to dynamically optimize MAS information flow without retraining. Our approach acts as an active firewall, intercepting agent outputs and employing a retrieval-augmented rectifier to iteratively correct errors based on a failure-driven indicator pool. This mechanism allows for the precise identification of potential errors using distilled failure patterns as prior knowledge. Irreparable outputs are subsequently pruned to prevent error propagation, while a fallback strategy preserves system integrity. Empirical results on extensive math benchmarks show that AgentDropoutV2 significantly boosts the MAS's task performance, achieving an average accuracy gain of 6.3 percentage points on math benchmarks. Furthermore, the system exhibits robust generalization and adaptivity, dynamically modulating rectification efforts based on task difficulty while leveraging context-aware indicators to resolve a wide spectrum of error patterns. Our code and dataset are released at https://github.com/TonySY2/AgentDropoutV2.
CogRail: Benchmarking VLMs in Cognitive Intrusion Perception for Intelligent Railway Transportation Systems
Jan 14, 2026Accurate and early perception of potential intrusion targets is essential for ensuring the safety of railway transportation systems. However, most existing systems focus narrowly on object classification within fixed visual scopes and apply rule-based heuristics to determine intrusion status, often overlooking targets that pose latent intrusion risks. Anticipating such risks requires the cognition of spatial context and temporal dynamics for the object of interest (OOI), which presents challenges for conventional visual models. To facilitate deep intrusion perception, we introduce a novel benchmark, CogRail, which integrates curated open-source datasets with cognitively driven question-answer annotations to support spatio-temporal reasoning and prediction. Building upon this benchmark, we conduct a systematic evaluation of state-of-the-art visual-language models (VLMs) using multimodal prompts to identify their strengths and limitations in this domain. Furthermore, we fine-tune VLMs for better performance and propose a joint fine-tuning framework that integrates three core tasks, position perception, movement prediction, and threat analysis, facilitating effective adaptation of general-purpose foundation models into specialized models tailored for cognitive intrusion perception. Extensive experiments reveal that current large-scale multimodal models struggle with the complex spatial-temporal reasoning required by the cognitive intrusion perception task, underscoring the limitations of existing foundation models in this safety-critical domain. In contrast, our proposed joint fine-tuning framework significantly enhances model performance by enabling targeted adaptation to domain-specific reasoning demands, highlighting the advantages of structured multi-task learning in improving both accuracy and interpretability. Code will be available at https://github.com/Hub-Tian/CogRail.
AstroReview: An LLM-driven Multi-Agent Framework for Telescope Proposal Peer Review and Refinement
Dec 31, 2025Competitive access to modern observatories has intensified as proposal volumes outpace available telescope time, making timely, consistent, and transparent peer review a critical bottleneck for the advancement of astronomy. Automating parts of this process is therefore both scientifically significant and operationally necessary to ensure fair allocation and reproducible decisions at scale. We present AstroReview, an open-source, agent-based framework that automates proposal review in three stages: (i) novelty and scientific merit, (ii) feasibility and expected yield, and (iii) meta-review and reliability verification. Task isolation and explicit reasoning traces curb hallucinations and improve transparency. Without any domain specific fine tuning, AstroReview used in our experiments only for the last stage, correctly identifies genuinely accepted proposals with an accuracy of 87%. The AstroReview in Action module replicates the review and refinement loop; with its integrated Proposal Authoring Agent, the acceptance rate of revised drafts increases by 66% after two iterations, showing that iterative feedback combined with automated meta-review and reliability verification delivers measurable quality gains. Together, these results point to a practical path toward scalable, auditable, and higher throughput proposal review for resource limited facilities.
Aria: An Agent For Retrieval and Iterative Auto-Formalization via Dependency Graph
Oct 06, 2025Accurate auto-formalization of theorem statements is essential for advancing automated discovery and verification of research-level mathematics, yet remains a major bottleneck for LLMs due to hallucinations, semantic mismatches, and their inability to synthesize new definitions. To tackle these issues, we present Aria (Agent for Retrieval and Iterative Autoformalization), a system for conjecture-level formalization in Lean that emulates human expert reasoning via a two-phase Graph-of-Thought process: recursively decomposing statements into a dependency graph and then constructing formalizations from grounded concepts. To ensure semantic correctness, we introduce AriaScorer, a checker that retrieves definitions from Mathlib for term-level grounding, enabling rigorous and reliable verification. We evaluate Aria on diverse benchmarks. On ProofNet, it achieves 91.6% compilation success rate and 68.5% final accuracy, surpassing previous methods. On FATE-X, a suite of challenging algebra problems from research literature, it outperforms the best baseline with 44.0% vs. 24.0% final accuracy. On a dataset of homological conjectures, Aria reaches 42.9% final accuracy while all other models score 0%.
REAL-Prover: Retrieval Augmented Lean Prover for Mathematical Reasoning
May 27, 2025Nowadays, formal theorem provers have made monumental progress on high-school and competition-level mathematics, but few of them generalize to more advanced mathematics. In this paper, we present REAL-Prover, a new open-source stepwise theorem prover for Lean 4 to push this boundary. This prover, based on our fine-tuned large language model (REAL-Prover-v1) and integrated with a retrieval system (Leansearch-PS), notably boosts performance on solving college-level mathematics problems. To train REAL-Prover-v1, we developed HERALD-AF, a data extraction pipeline that converts natural language math problems into formal statements, and a new open-source Lean 4 interactive environment (Jixia-interactive) to facilitate synthesis data collection. In our experiments, our prover using only supervised fine-tune achieves competitive results with a 23.7% success rate (Pass@64) on the ProofNet dataset-comparable to state-of-the-art (SOTA) models. To further evaluate our approach, we introduce FATE-M, a new benchmark focused on algebraic problems, where our prover achieves a SOTA success rate of 56.7% (Pass@64).
AgentDropout: Dynamic Agent Elimination for Token-Efficient and High-Performance LLM-Based Multi-Agent Collaboration
Mar 24, 2025Multi-agent systems (MAS) based on large language models (LLMs) have demonstrated significant potential in collaborative problem-solving. However, they still face substantial challenges of low communication efficiency and suboptimal task performance, making the careful design of the agents' communication topologies particularly important. Inspired by the management theory that roles in an efficient team are often dynamically adjusted, we propose AgentDropout, which identifies redundant agents and communication across different communication rounds by optimizing the adjacency matrices of the communication graphs and eliminates them to enhance both token efficiency and task performance. Compared to state-of-the-art methods, AgentDropout achieves an average reduction of 21.6% in prompt token consumption and 18.4% in completion token consumption, along with a performance improvement of 1.14 on the tasks. Furthermore, the extended experiments demonstrate that AgentDropout achieves notable domain transferability and structure robustness, revealing its reliability and effectiveness. We release our code at https://github.com/wangzx1219/AgentDropout.
MCTS-Judge: Test-Time Scaling in LLM-as-a-Judge for Code Correctness Evaluation
Feb 18, 2025The LLM-as-a-Judge paradigm shows promise for evaluating generative content but lacks reliability in reasoning-intensive scenarios, such as programming. Inspired by recent advances in reasoning models and shifts in scaling laws, we pioneer bringing test-time computation into LLM-as-a-Judge, proposing MCTS-Judge, a resource-efficient, System-2 thinking framework for code correctness evaluation. MCTS-Judge leverages Monte Carlo Tree Search (MCTS) to decompose problems into simpler, multi-perspective evaluations. Through a node-selection strategy that combines self-assessment based on historical actions in the current trajectory and the Upper Confidence Bound for Trees based on prior rollouts, MCTS-Judge balances global optimization and refinement of the current trajectory. We further designed a high-precision, unit-test-level reward mechanism to encourage the Large Language Model (LLM) to perform line-by-line analysis. Extensive experiments on three benchmarks and five LLMs demonstrate the effectiveness of MCTS-Judge, which improves the base model's accuracy from 41% to 80%, surpassing the o1-series models with 3x fewer tokens. Further evaluations validate the superiority of its reasoning trajectory in logic, analytics, thoroughness, and overall quality, while revealing the test-time scaling law of the LLM-as-a-Judge paradigm.
Hierarchical Trajectory (Re)Planning for a Large Scale Swarm
Jan 28, 2025
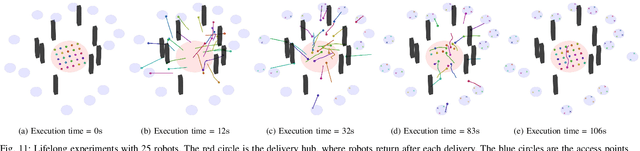
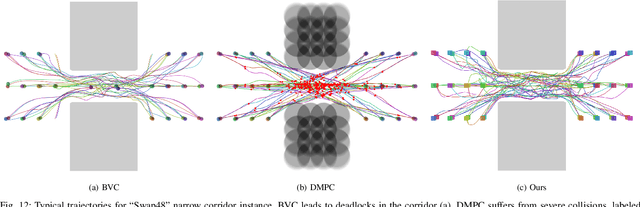
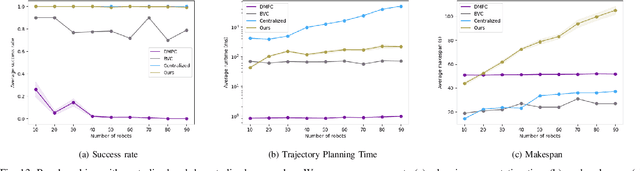
We consider the trajectory replanning problem for a large-scale swarm in a cluttered environment. Our path planner replans for robots by utilizing a hierarchical approach, dividing the workspace, and computing collision-free paths for robots within each cell in parallel. Distributed trajectory optimization generates a deadlock-free trajectory for efficient execution and maintains the control feasibility even when the optimization fails. Our hierarchical approach combines the benefits of both centralized and decentralized methods, achieving a high task success rate while providing real-time replanning capability. Compared to decentralized approaches, our approach effectively avoids deadlocks and collisions, significantly increasing the task success rate. We demonstrate the real-time performance of our algorithm with up to 142 robots in simulation, and a representative 24 physical Crazyflie nano-quadrotor experiment.