 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Video Face Enhancement with Enhanced Spatial-Temporal Consistency
Nov 25, 2024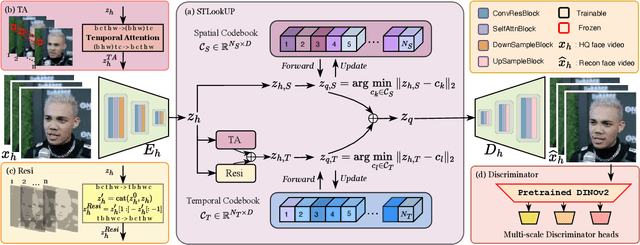
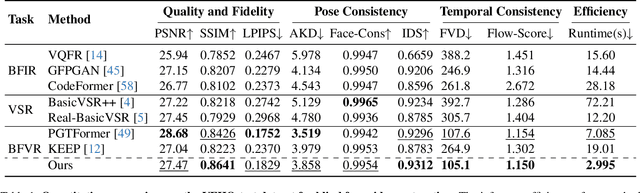
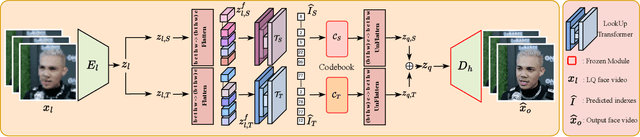

As a very common type of video, face videos often appear in movies, talk shows, live broadcasts, and other scenes. Real-world online videos are often plagued by degradations such as blurring and quantization noise, due to the high compression ratio caused by high communication costs and limited transmission bandwidth. These degradations have a particularly serious impact on face videos because the human visual system is highly sensitive to facial details. Despite the significant advancement in video face enhancement, current methods still suffer from $i)$ long processing time and $ii)$ inconsistent spatial-temporal visual effects (e.g., flickering). This study proposes a novel and efficient blind video face enhancement method to overcome the above two challenges, restoring high-quality videos from their compressed low-quality versions with an effective de-flickering mechanism. In particular, the proposed method develops upon a 3D-VQGAN backbone associated with spatial-temporal codebooks recording high-quality portrait features and residual-based temporal information. We develop a two-stage learning framework for the model. In Stage \Rmnum{1}, we learn the model with a regularizer mitigating the codebook collapse problem. In Stage \Rmnum{2}, we learn two transformers to lookup code from the codebooks and further update the encoder of low-quality videos. Experiments conducted on the VFHQ-Test dataset demonstrate that our method surpasses the current state-of-the-art blind face video restoration and de-flickering methods on both efficiency and effectiveness. Code is available at \url{https://github.com/Dixin-Lab/BFVR-STC}.
Token Caching for Diffusion Transformer Acceleration
Sep 27, 2024



Diffusion transformers have gained substantial interest in diffusion generative modeling due to their outstanding performance. However, their high computational cost, arising from the quadratic computational complexity of attention mechanisms and multi-step inference, presents a significant bottleneck. To address this challenge, we propose TokenCache, a novel post-training acceleration method that leverages the token-based multi-block architecture of transformers to reduce redundant computations among tokens across inference steps. TokenCache specifically addresses three critical questions in the context of diffusion transformers: (1) which tokens should be pruned to eliminate redundancy, (2) which blocks should be targeted for efficient pruning, and (3) at which time steps caching should be applied to balance speed and quality. In response to these challenges, TokenCache introduces a Cache Predictor that assigns importance scores to tokens, enabling selective pruning without compromising model performance. Furthermore, we propose an adaptive block selection strategy to focus on blocks with minimal impact on the network's output, along with a Two-Phase Round-Robin (TPRR) scheduling policy to optimize caching intervals throughout the denoising process. Experimental results across various models demonstrate that TokenCache achieves an effective trade-off between generation quality and inference speed for diffusion transformers. Our code will be publicly available.
EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions
Jul 11, 2024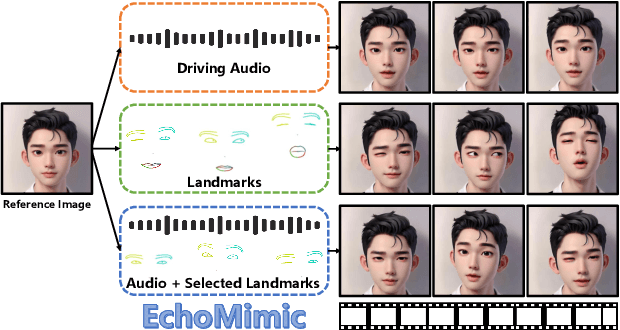
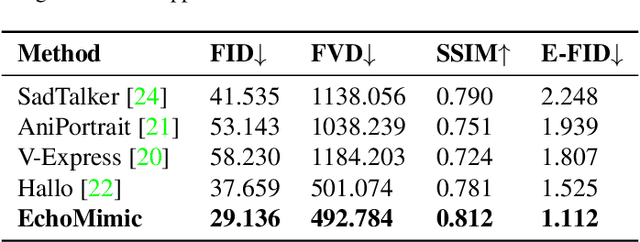
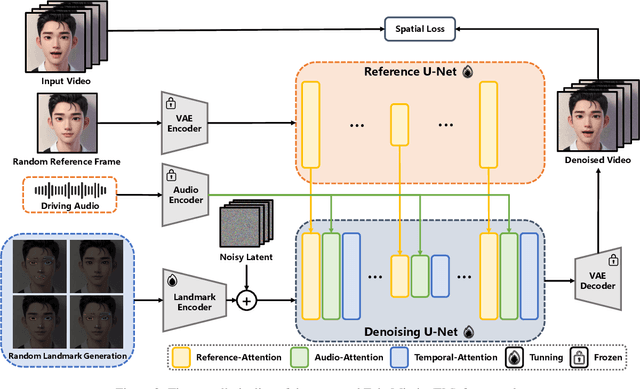

The area of portrait image animation, propelled by audio input, has witnessed notable progress in the generation of lifelike and dynamic portraits. Conventional methods are limited to utilizing either audios or facial key points to drive images into videos, while they can yield satisfactory results, certain issues exist. For instance, methods driven solely by audios can be unstable at times due to the relatively weaker audio signal, while methods driven exclusively by facial key points, although more stable in driving, can result in unnatural outcomes due to the excessive control of key point information. In addressing the previously mentioned challenges, in this paper, we introduce a novel approach which we named EchoMimic. EchoMimic is concurrently trained using both audios and facial landmarks. Through the implementation of a novel training strategy, EchoMimic is capable of generating portrait videos not only by audios and facial landmarks individually, but also by a combination of both audios and selected facial landmarks. EchoMimic has been comprehensively compared with alternative algorithms across various public datasets and our collected dataset, showcasing superior performance in both quantitative and qualitative evaluations. Additional visualization and access to the source code can be located on the EchoMimic project page.
SpeedUpNet: A Plug-and-Play Hyper-Network for Accelerating Text-to-Image Diffusion Models
Dec 20, 2023Text-to-image diffusion models (SD) exhibit significant advancements while requiring extensive computational resources. Though many acceleration methods have been proposed, they suffer from generation quality degradation or extra training cost generalizing to new fine-tuned models. To address these limitations, we propose a novel and universal Stable-Diffusion (SD) acceleration module called SpeedUpNet(SUN). SUN can be directly plugged into various fine-tuned SD models without extra training. This technique utilizes cross-attention layers to learn the relative offsets in the generated image results between negative and positive prompts achieving classifier-free guidance distillation with negative prompts controllable, and introduces a Multi-Step Consistency (MSC) loss to ensure a harmonious balance between reducing inference steps and maintaining consistency in the generated output. Consequently, SUN significantly reduces the number of inference steps to just 4 steps and eliminates the need for classifier-free guidance. It leads to an overall speedup of more than 10 times for SD models compared to the state-of-the-art 25-step DPM-solver++, and offers two extra advantages: (1) classifier-free guidance distillation with controllable negative prompts and (2) seamless integration into various fine-tuned Stable-Diffusion models without training. The effectiveness of the SUN has been verified through extensive experimentation. Project Page: https://williechai.github.io/speedup-plugin-for-stable-diffusions.github.io
Facial Affect Analysis: Learning from Synthetic Data & Multi-Task Learning Challenges
Jul 20, 2022
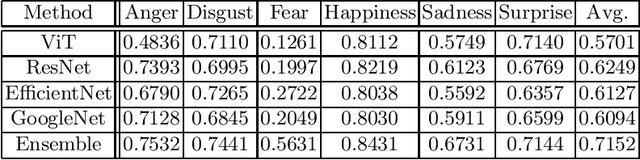
Facial affect analysis remains a challenging task with its setting transitioned from lab-controlled to in-the-wild situations. In this paper, we present novel frameworks to handle the two challenges in the 4th Affective Behavior Analysis In-The-Wild (ABAW) competition: i) Multi-Task-Learning (MTL) Challenge and ii) Learning from Synthetic Data (LSD) Challenge. For MTL challenge, we adopt the SMM-EmotionNet with a better ensemble strategy of feature vectors. For LSD challenge, we propose respective methods to combat the problems of single labels, imbalanced distribution, fine-tuning limitations, and choice of model architectures. Experimental results on the official validation sets from the competition demonstrated that our proposed approaches outperformed baselines by a large margin. The code is available at https://github.com/sylyoung/ABAW4-HUST-ANT.
Cross-Architecture Knowledge Distillation
Jul 12, 2022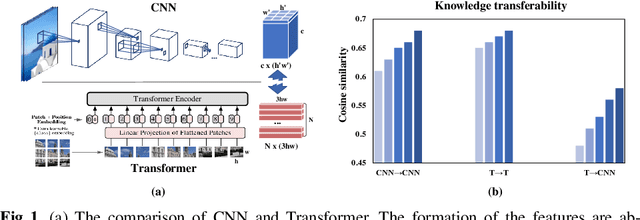
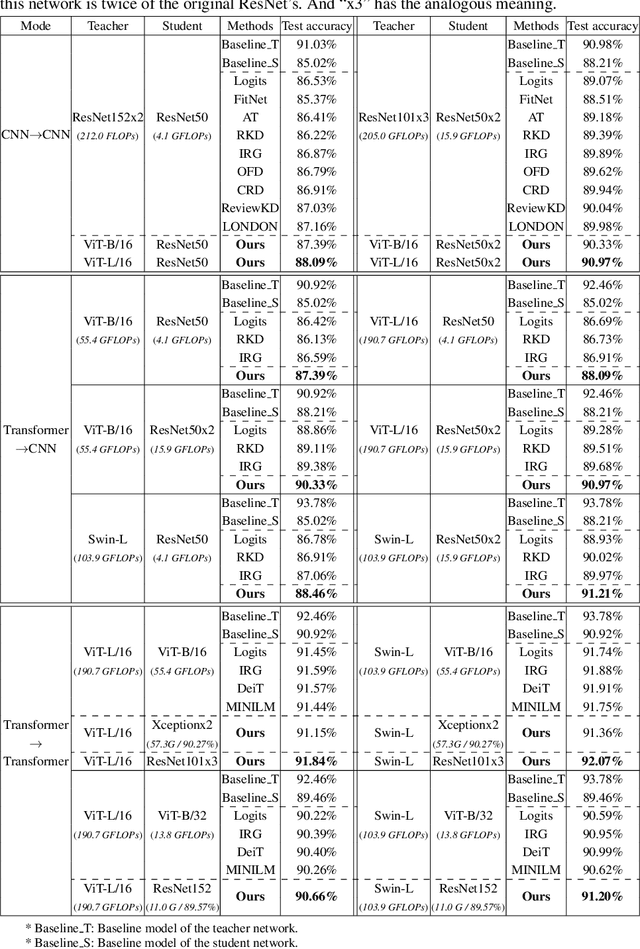
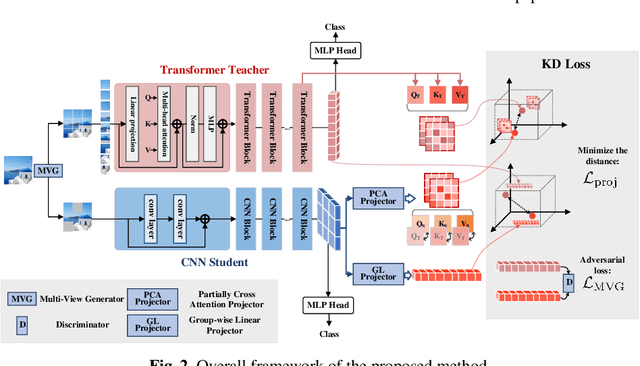
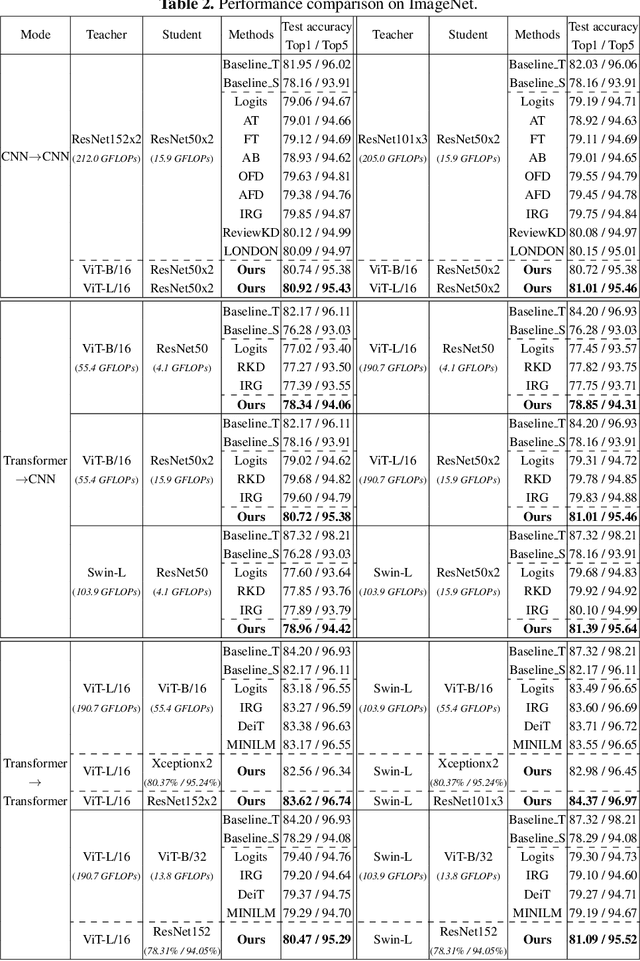
Transformer attracts much attention because of its ability to learn global relations and superior performance. In order to achieve higher performance, it is natural to distill complementary knowledge from Transformer to convolutional neural network (CNN). However, most existing knowledge distillation methods only consider homologous-architecture distillation, such as distilling knowledge from CNN to CNN. They may not be suitable when applying to cross-architecture scenarios, such as from Transformer to CNN. To deal with this problem, a novel cross-architecture knowledge distillation method is proposed. Specifically, instead of directly mimicking output/intermediate features of the teacher, a partially cross attention projector and a group-wise linear projector are introduced to align the student features with the teacher's in two projected feature spaces. And a multi-view robust training scheme is further presented to improve the robustness and stability of the framework. Extensive experiments show that the proposed method outperforms 14 state-of-the-arts on both small-scale and large-scale datasets.