 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions
Jul 11, 2024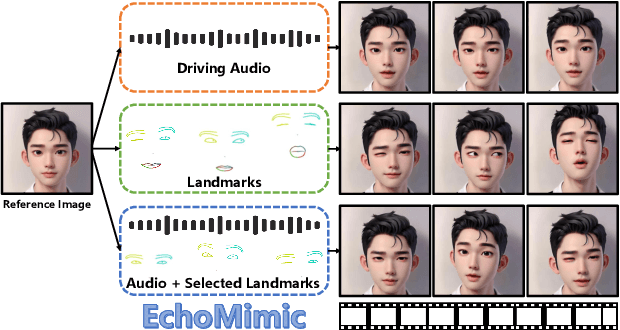
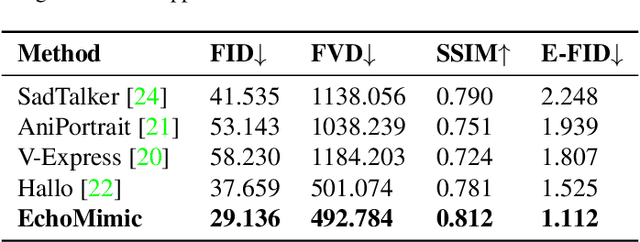
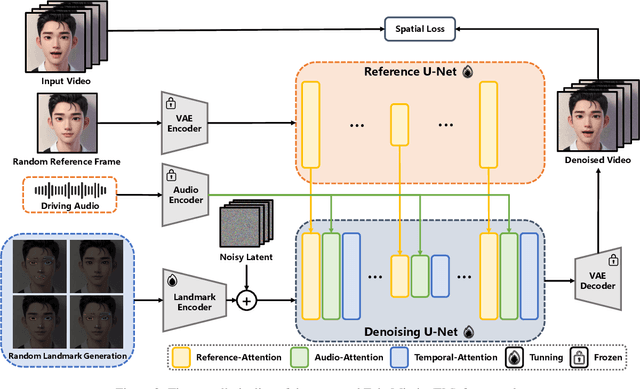

The area of portrait image animation, propelled by audio input, has witnessed notable progress in the generation of lifelike and dynamic portraits. Conventional methods are limited to utilizing either audios or facial key points to drive images into videos, while they can yield satisfactory results, certain issues exist. For instance, methods driven solely by audios can be unstable at times due to the relatively weaker audio signal, while methods driven exclusively by facial key points, although more stable in driving, can result in unnatural outcomes due to the excessive control of key point information. In addressing the previously mentioned challenges, in this paper, we introduce a novel approach which we named EchoMimic. EchoMimic is concurrently trained using both audios and facial landmarks. Through the implementation of a novel training strategy, EchoMimic is capable of generating portrait videos not only by audios and facial landmarks individually, but also by a combination of both audios and selected facial landmarks. EchoMimic has been comprehensively compared with alternative algorithms across various public datasets and our collected dataset, showcasing superior performance in both quantitative and qualitative evaluations. Additional visualization and access to the source code can be located on the EchoMimic project page.
SpeedUpNet: A Plug-and-Play Hyper-Network for Accelerating Text-to-Image Diffusion Models
Dec 20, 2023Text-to-image diffusion models (SD) exhibit significant advancements while requiring extensive computational resources. Though many acceleration methods have been proposed, they suffer from generation quality degradation or extra training cost generalizing to new fine-tuned models. To address these limitations, we propose a novel and universal Stable-Diffusion (SD) acceleration module called SpeedUpNet(SUN). SUN can be directly plugged into various fine-tuned SD models without extra training. This technique utilizes cross-attention layers to learn the relative offsets in the generated image results between negative and positive prompts achieving classifier-free guidance distillation with negative prompts controllable, and introduces a Multi-Step Consistency (MSC) loss to ensure a harmonious balance between reducing inference steps and maintaining consistency in the generated output. Consequently, SUN significantly reduces the number of inference steps to just 4 steps and eliminates the need for classifier-free guidance. It leads to an overall speedup of more than 10 times for SD models compared to the state-of-the-art 25-step DPM-solver++, and offers two extra advantages: (1) classifier-free guidance distillation with controllable negative prompts and (2) seamless integration into various fine-tuned Stable-Diffusion models without training. The effectiveness of the SUN has been verified through extensive experimentation. Project Page: https://williechai.github.io/speedup-plugin-for-stable-diffusions.github.io