 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoTorrent: Towards Swift, Sustained, and Streaming Multi-Modal Video Generation
Feb 14, 2026Recent multi-modal video generation models have achieved high visual quality, but their prohibitive latency and limited temporal stability hinder real-time deployment. Streaming inference exacerbates these issues, leading to pronounced multimodal degradation, such as spatial blurring, temporal drift, and lip desynchronization, which creates an unresolved efficiency-performance trade-off. To this end, we propose EchoTorrent, a novel schema with a fourfold design: (1) Multi-Teacher Training fine-tunes a pre-trained model on distinct preference domains to obtain specialized domain experts, which sequentially transfer domain-specific knowledge to a student model; (2) Adaptive CFG Calibration (ACC-DMD), which calibrates the audio CFG augmentation errors in DMD via a phased spatiotemporal schedule, eliminating redundant CFG computations and enabling single-pass inference per step; (3) Hybrid Long Tail Forcing, which enforces alignment exclusively on tail frames during long-horizon self-rollout training via a causal-bidirectional hybrid architecture, effectively mitigates spatiotemporal degradation in streaming mode while enhancing fidelity to reference frames; and (4) VAE Decoder Refiner through pixel-domain optimization of the VAE decoder to recover high-frequency details while circumventing latent-space ambiguities. Extensive experiments and analysis demonstrate that EchoTorrent achieves few-pass autoregressive generation with substantially extended temporal consistency, identity preservation, and audio-lip synchronization.
M$^2$-Miner: Multi-Agent Enhanced MCTS for Mobile GUI Agent Data Mining
Feb 05, 2026Graphical User Interface (GUI) agent is pivotal to advancing intelligent human-computer interaction paradigms. Constructing powerful GUI agents necessitates the large-scale annotation of high-quality user-behavior trajectory data (i.e., intent-trajectory pairs) for training. However, manual annotation methods and current GUI agent data mining approaches typically face three critical challenges: high construction cost, poor data quality, and low data richness. To address these issues, we propose M$^2$-Miner, the first low-cost and automated mobile GUI agent data-mining framework based on Monte Carlo Tree Search (MCTS). For better data mining efficiency and quality, we present a collaborative multi-agent framework, comprising InferAgent, OrchestraAgent, and JudgeAgent for guidance, acceleration, and evaluation. To further enhance the efficiency of mining and enrich intent diversity, we design an intent recycling strategy to extract extra valuable interaction trajectories. Additionally, a progressive model-in-the-loop training strategy is introduced to improve the success rate of data mining. Extensive experiments have demonstrated that the GUI agent fine-tuned using our mined data achieves state-of-the-art performance on several commonly used mobile GUI benchmarks. Our work will be released to facilitate the community research.
SPEED-Q: Staged Processing with Enhanced Distillation towards Efficient Low-bit On-device VLM Quantization
Nov 12, 2025Deploying Vision-Language Models (VLMs) on edge devices (e.g., smartphones and robots) is crucial for enabling low-latency and privacy-preserving intelligent applications. Given the resource constraints of these devices, quantization offers a promising solution by improving memory efficiency and reducing bandwidth requirements, thereby facilitating the deployment of VLMs. However, existing research has rarely explored aggressive quantization on VLMs, particularly for the models ranging from 1B to 2B parameters, which are more suitable for resource-constrained edge devices. In this paper, we propose SPEED-Q, a novel Staged Processing with Enhanced Distillation framework for VLM low-bit weight-only quantization that systematically addresses the following two critical obstacles: (1) significant discrepancies in quantization sensitivity between vision (ViT) and language (LLM) components in VLMs; (2) training instability arising from the reduced numerical precision inherent in low-bit quantization. In SPEED-Q, a staged sensitivity adaptive mechanism is introduced to effectively harmonize performance across different modalities. We further propose a distillation-enhanced quantization strategy to stabilize the training process and reduce data dependence. Together, SPEED-Q enables accurate, stable, and data-efficient quantization of complex VLMs. SPEED-Q is the first framework tailored for quantizing entire small-scale billion-parameter VLMs to low bits. Extensive experiments across multiple benchmarks demonstrate that SPEED-Q achieves up to 6x higher accuracy than existing quantization methods under 2-bit settings and consistently outperforms prior on-device VLMs under both 2-bit and 4-bit settings. Our code and models are available at https://github.com/antgroup/SPEED-Q.
SparkUI-Parser: Enhancing GUI Perception with Robust Grounding and Parsing
Sep 05, 2025The existing Multimodal Large Language Models (MLLMs) for GUI perception have made great progress. However, the following challenges still exist in prior methods: 1) They model discrete coordinates based on text autoregressive mechanism, which results in lower grounding accuracy and slower inference speed. 2) They can only locate predefined sets of elements and are not capable of parsing the entire interface, which hampers the broad application and support for downstream tasks. To address the above issues, we propose SparkUI-Parser, a novel end-to-end framework where higher localization precision and fine-grained parsing capability of the entire interface are simultaneously achieved. Specifically, instead of using probability-based discrete modeling, we perform continuous modeling of coordinates based on a pre-trained Multimodal Large Language Model (MLLM) with an additional token router and coordinate decoder. This effectively mitigates the limitations inherent in the discrete output characteristics and the token-by-token generation process of MLLMs, consequently boosting both the accuracy and the inference speed. To further enhance robustness, a rejection mechanism based on a modified Hungarian matching algorithm is introduced, which empowers the model to identify and reject non-existent elements, thereby reducing false positives. Moreover, we present ScreenParse, a rigorously constructed benchmark to systematically assess structural perception capabilities of GUI models across diverse scenarios. Extensive experiments demonstrate that our approach consistently outperforms SOTA methods on ScreenSpot, ScreenSpot-v2, CAGUI-Grounding and ScreenParse benchmarks. The resources are available at https://github.com/antgroup/SparkUI-Parser.
EmojiDiff: Advanced Facial Expression Control with High Identity Preservation in Portrait Generation
Dec 02, 2024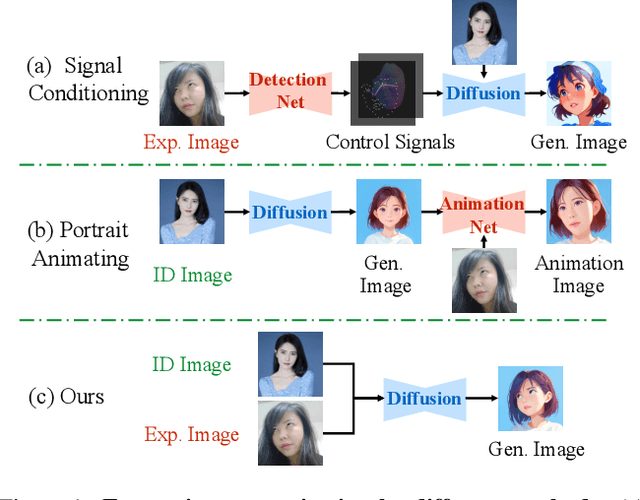
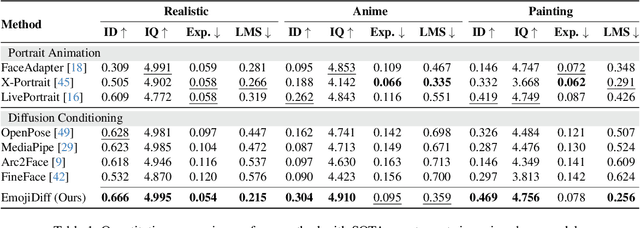

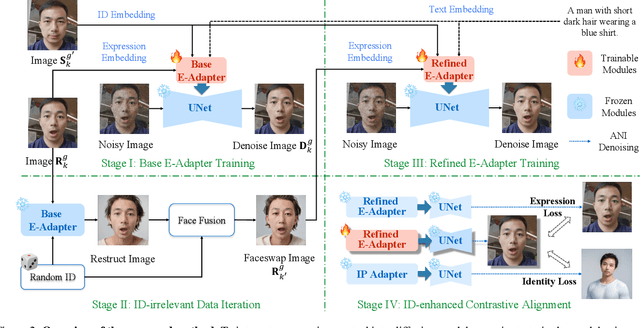
This paper aims to bring fine-grained expression control to identity-preserving portrait generation. Existing methods tend to synthesize portraits with either neutral or stereotypical expressions. Even when supplemented with control signals like facial landmarks, these models struggle to generate accurate and vivid expressions following user instructions. To solve this, we introduce EmojiDiff, an end-to-end solution to facilitate simultaneous dual control of fine expression and identity. Unlike the conventional methods using coarse control signals, our method directly accepts RGB expression images as input templates to provide extremely accurate and fine-grained expression control in the diffusion process. As its core, an innovative decoupled scheme is proposed to disentangle expression features in the expression template from other extraneous information, such as identity, skin, and style. On one hand, we introduce \textbf{I}D-irrelevant \textbf{D}ata \textbf{I}teration (IDI) to synthesize extremely high-quality cross-identity expression pairs for decoupled training, which is the crucial foundation to filter out identity information hidden in the expressions. On the other hand, we meticulously investigate network layer function and select expression-sensitive layers to inject reference expression features, effectively preventing style leakage from expression signals. To further improve identity fidelity, we propose a novel fine-tuning strategy named \textbf{I}D-enhanced \textbf{C}ontrast \textbf{A}lignment (ICA), which eliminates the negative impact of expression control on original identity preservation. Experimental results demonstrate that our method remarkably outperforms counterparts, achieves precise expression control with highly maintained identity, and generalizes well to various diffusion models.
Efficient Video Face Enhancement with Enhanced Spatial-Temporal Consistency
Nov 25, 2024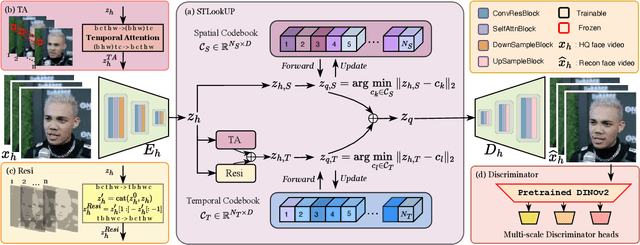
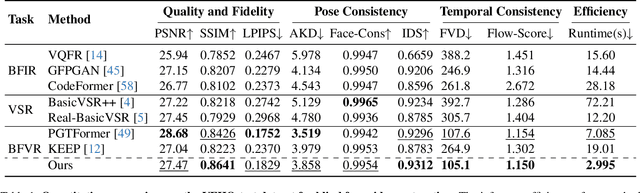
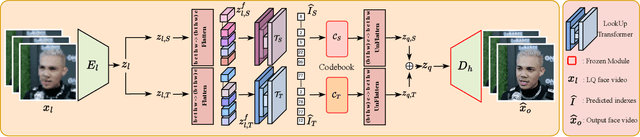

As a very common type of video, face videos often appear in movies, talk shows, live broadcasts, and other scenes. Real-world online videos are often plagued by degradations such as blurring and quantization noise, due to the high compression ratio caused by high communication costs and limited transmission bandwidth. These degradations have a particularly serious impact on face videos because the human visual system is highly sensitive to facial details. Despite the significant advancement in video face enhancement, current methods still suffer from $i)$ long processing time and $ii)$ inconsistent spatial-temporal visual effects (e.g., flickering). This study proposes a novel and efficient blind video face enhancement method to overcome the above two challenges, restoring high-quality videos from their compressed low-quality versions with an effective de-flickering mechanism. In particular, the proposed method develops upon a 3D-VQGAN backbone associated with spatial-temporal codebooks recording high-quality portrait features and residual-based temporal information. We develop a two-stage learning framework for the model. In Stage \Rmnum{1}, we learn the model with a regularizer mitigating the codebook collapse problem. In Stage \Rmnum{2}, we learn two transformers to lookup code from the codebooks and further update the encoder of low-quality videos. Experiments conducted on the VFHQ-Test dataset demonstrate that our method surpasses the current state-of-the-art blind face video restoration and de-flickering methods on both efficiency and effectiveness. Code is available at \url{https://github.com/Dixin-Lab/BFVR-STC}.
EchoMimicV2: Towards Striking, Simplified, and Semi-Body Human Animation
Nov 15, 2024
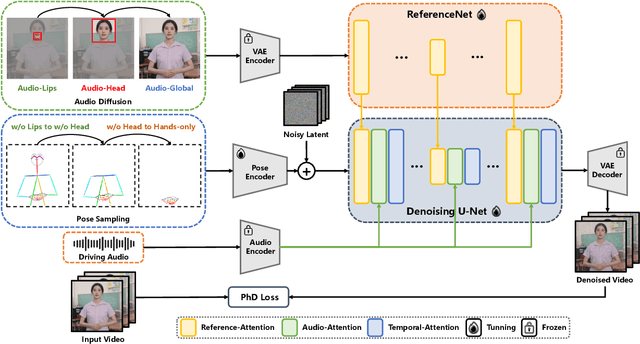
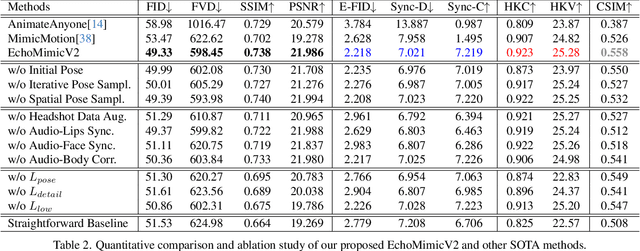

Recent work on human animation usually involves audio, pose, or movement maps conditions, thereby achieves vivid animation quality. However, these methods often face practical challenges due to extra control conditions, cumbersome condition injection modules, or limitation to head region driving. Hence, we ask if it is possible to achieve striking half-body human animation while simplifying unnecessary conditions. To this end, we propose a half-body human animation method, dubbed EchoMimicV2, that leverages a novel Audio-Pose Dynamic Harmonization strategy, including Pose Sampling and Audio Diffusion, to enhance half-body details, facial and gestural expressiveness, and meanwhile reduce conditions redundancy. To compensate for the scarcity of half-body data, we utilize Head Partial Attention to seamlessly accommodate headshot data into our training framework, which can be omitted during inference, providing a free lunch for animation. Furthermore, we design the Phase-specific Denoising Loss to guide motion, detail, and low-level quality for animation in specific phases, respectively. Besides, we also present a novel benchmark for evaluating the effectiveness of half-body human animation. Extensive experiments and analyses demonstrate that EchoMimicV2 surpasses existing methods in both quantitative and qualitative evaluations.
Token Caching for Diffusion Transformer Acceleration
Sep 27, 2024



Diffusion transformers have gained substantial interest in diffusion generative modeling due to their outstanding performance. However, their high computational cost, arising from the quadratic computational complexity of attention mechanisms and multi-step inference, presents a significant bottleneck. To address this challenge, we propose TokenCache, a novel post-training acceleration method that leverages the token-based multi-block architecture of transformers to reduce redundant computations among tokens across inference steps. TokenCache specifically addresses three critical questions in the context of diffusion transformers: (1) which tokens should be pruned to eliminate redundancy, (2) which blocks should be targeted for efficient pruning, and (3) at which time steps caching should be applied to balance speed and quality. In response to these challenges, TokenCache introduces a Cache Predictor that assigns importance scores to tokens, enabling selective pruning without compromising model performance. Furthermore, we propose an adaptive block selection strategy to focus on blocks with minimal impact on the network's output, along with a Two-Phase Round-Robin (TPRR) scheduling policy to optimize caching intervals throughout the denoising process. Experimental results across various models demonstrate that TokenCache achieves an effective trade-off between generation quality and inference speed for diffusion transformers. Our code will be publicly available.
EchoMimic: Lifelike Audio-Driven Portrait Animations through Editable Landmark Conditions
Jul 11, 2024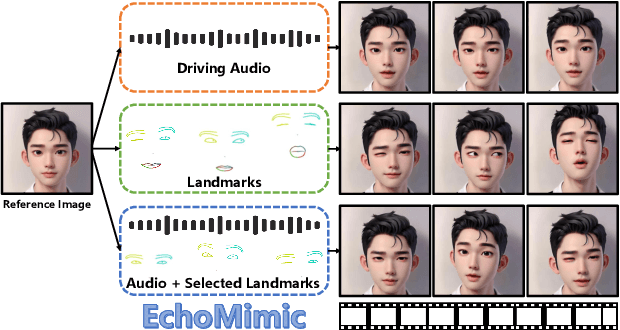
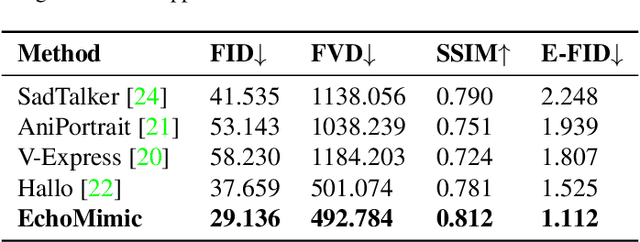
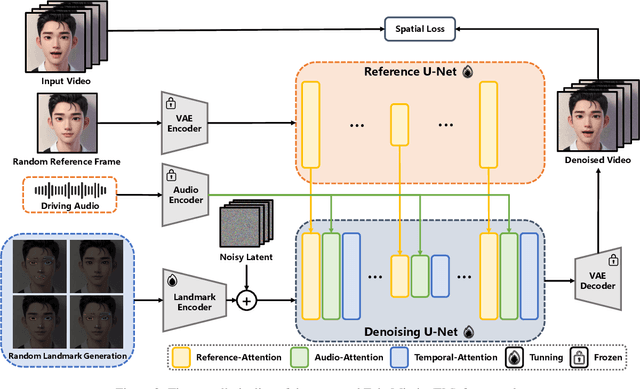

The area of portrait image animation, propelled by audio input, has witnessed notable progress in the generation of lifelike and dynamic portraits. Conventional methods are limited to utilizing either audios or facial key points to drive images into videos, while they can yield satisfactory results, certain issues exist. For instance, methods driven solely by audios can be unstable at times due to the relatively weaker audio signal, while methods driven exclusively by facial key points, although more stable in driving, can result in unnatural outcomes due to the excessive control of key point information. In addressing the previously mentioned challenges, in this paper, we introduce a novel approach which we named EchoMimic. EchoMimic is concurrently trained using both audios and facial landmarks. Through the implementation of a novel training strategy, EchoMimic is capable of generating portrait videos not only by audios and facial landmarks individually, but also by a combination of both audios and selected facial landmarks. EchoMimic has been comprehensively compared with alternative algorithms across various public datasets and our collected dataset, showcasing superior performance in both quantitative and qualitative evaluations. Additional visualization and access to the source code can be located on the EchoMimic project page.
SpeedUpNet: A Plug-and-Play Hyper-Network for Accelerating Text-to-Image Diffusion Models
Dec 20, 2023Text-to-image diffusion models (SD) exhibit significant advancements while requiring extensive computational resources. Though many acceleration methods have been proposed, they suffer from generation quality degradation or extra training cost generalizing to new fine-tuned models. To address these limitations, we propose a novel and universal Stable-Diffusion (SD) acceleration module called SpeedUpNet(SUN). SUN can be directly plugged into various fine-tuned SD models without extra training. This technique utilizes cross-attention layers to learn the relative offsets in the generated image results between negative and positive prompts achieving classifier-free guidance distillation with negative prompts controllable, and introduces a Multi-Step Consistency (MSC) loss to ensure a harmonious balance between reducing inference steps and maintaining consistency in the generated output. Consequently, SUN significantly reduces the number of inference steps to just 4 steps and eliminates the need for classifier-free guidance. It leads to an overall speedup of more than 10 times for SD models compared to the state-of-the-art 25-step DPM-solver++, and offers two extra advantages: (1) classifier-free guidance distillation with controllable negative prompts and (2) seamless integration into various fine-tuned Stable-Diffusion models without training. The effectiveness of the SUN has been verified through extensive experimentation. Project Page: https://williechai.github.io/speedup-plugin-for-stable-diffusions.github.io