 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructVRM: Aligning Multimodal Reasoning with Structured and Verifiable Reward Models
Aug 07, 2025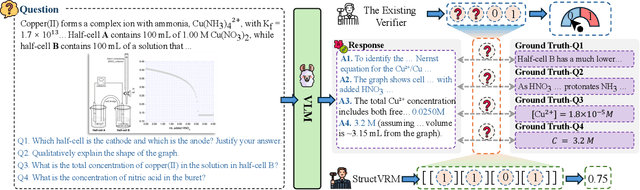

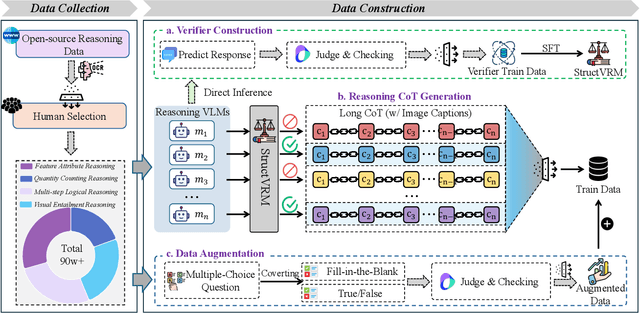
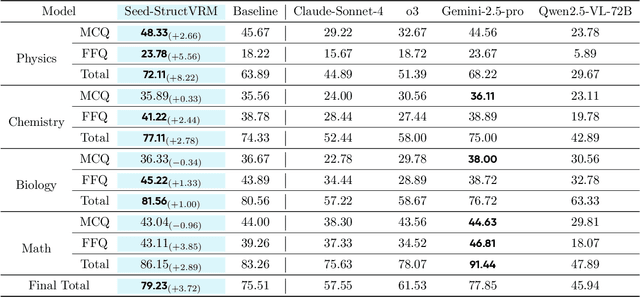
Existing Vision-Language Models often struggle with complex, multi-question reasoning tasks where partial correctness is crucial for effective learning. Traditional reward mechanisms, which provide a single binary score for an entire response, are too coarse to guide models through intricate problems with multiple sub-parts. To address this, we introduce StructVRM, a method that aligns multimodal reasoning with Structured and Verifiable Reward Models. At its core is a model-based verifier trained to provide fine-grained, sub-question-level feedback, assessing semantic and mathematical equivalence rather than relying on rigid string matching. This allows for nuanced, partial credit scoring in previously intractable problem formats. Extensive experiments demonstrate the effectiveness of StructVRM. Our trained model, Seed-StructVRM, achieves state-of-the-art performance on six out of twelve public multimodal benchmarks and our newly curated, high-difficulty STEM-Bench. The success of StructVRM validates that training with structured, verifiable rewards is a highly effective approach for advancing the capabilities of multimodal models in complex, real-world reasoning domains.
SpeedUpNet: A Plug-and-Play Hyper-Network for Accelerating Text-to-Image Diffusion Models
Dec 20, 2023Text-to-image diffusion models (SD) exhibit significant advancements while requiring extensive computational resources. Though many acceleration methods have been proposed, they suffer from generation quality degradation or extra training cost generalizing to new fine-tuned models. To address these limitations, we propose a novel and universal Stable-Diffusion (SD) acceleration module called SpeedUpNet(SUN). SUN can be directly plugged into various fine-tuned SD models without extra training. This technique utilizes cross-attention layers to learn the relative offsets in the generated image results between negative and positive prompts achieving classifier-free guidance distillation with negative prompts controllable, and introduces a Multi-Step Consistency (MSC) loss to ensure a harmonious balance between reducing inference steps and maintaining consistency in the generated output. Consequently, SUN significantly reduces the number of inference steps to just 4 steps and eliminates the need for classifier-free guidance. It leads to an overall speedup of more than 10 times for SD models compared to the state-of-the-art 25-step DPM-solver++, and offers two extra advantages: (1) classifier-free guidance distillation with controllable negative prompts and (2) seamless integration into various fine-tuned Stable-Diffusion models without training. The effectiveness of the SUN has been verified through extensive experimentation. Project Page: https://williechai.github.io/speedup-plugin-for-stable-diffusions.github.io
1st Place Solution of LVIS Challenge 2020: A Good Box is not a Guarantee of a Good Mask
Sep 03, 2020This article introduces the solutions of the team lvisTraveler for LVIS Challenge 2020. In this work, two characteristics of LVIS dataset are mainly considered: the long-tailed distribution and high quality instance segmentation mask. We adopt a two-stage training pipeline. In the first stage, we incorporate EQL and self-training to learn generalized representation. In the second stage, we utilize Balanced GroupSoftmax to promote the classifier, and propose a novel proposal assignment strategy and a new balanced mask loss for mask head to get more precise mask predictions. Finally, we achieve 41.5 and 41.2 AP on LVIS v1.0 val and test-dev splits respectively, outperforming the baseline based on X101-FPN-MaskRCNN by a large margin.
Equalization Loss for Long-Tailed Object Recognition
Apr 14, 2020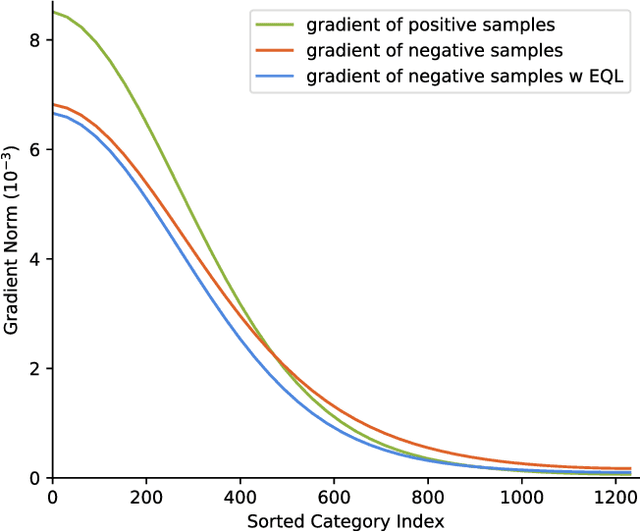
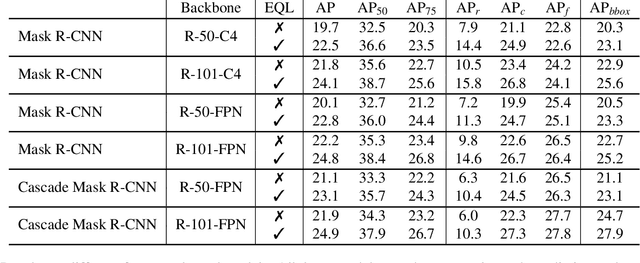
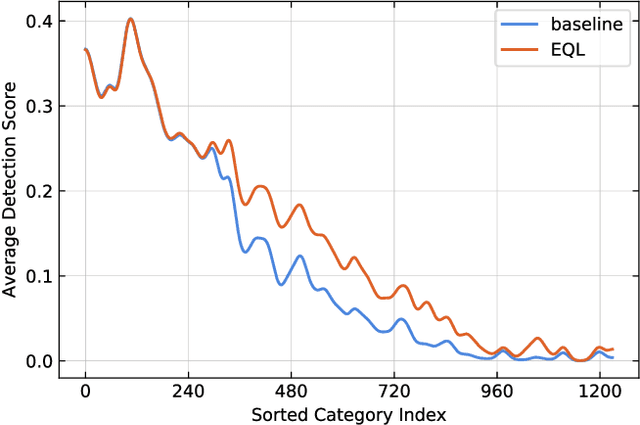
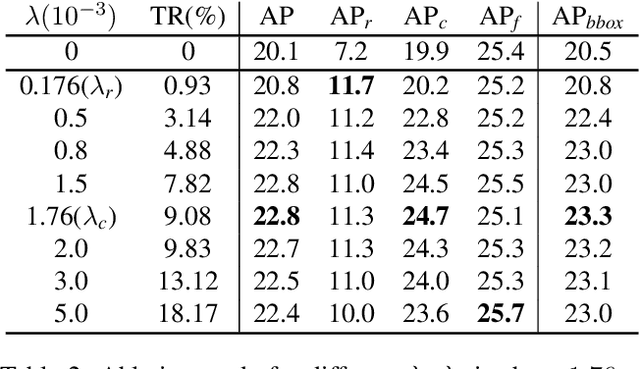
Object recognition techniques using convolutional neural networks (CNN) have achieved great success. However, state-of-the-art object detection methods still perform poorly on large vocabulary and long-tailed datasets, e.g. LVIS. In this work, we analyze this problem from a novel perspective: each positive sample of one category can be seen as a negative sample for other categories, making the tail categories receive more discouraging gradients. Based on it, we propose a simple but effective loss, named equalization loss, to tackle the problem of long-tailed rare categories by simply ignoring those gradients for rare categories. The equalization loss protects the learning of rare categories from being at a disadvantage during the network parameter updating. Thus the model is capable of learning better discriminative features for objects of rare classes. Without any bells and whistles, our method achieves AP gains of 4.1% and 4.8% for the rare and common categories on the challenging LVIS benchmark, compared to the Mask R-CNN baseline. With the utilization of the effective equalization loss, we finally won the 1st place in the LVIS Challenge 2019. Code has been made available at: https: //github.com/tztztztztz/eql.detectron2
Equalization Loss for Large Vocabulary Instance Segmentation
Nov 12, 2019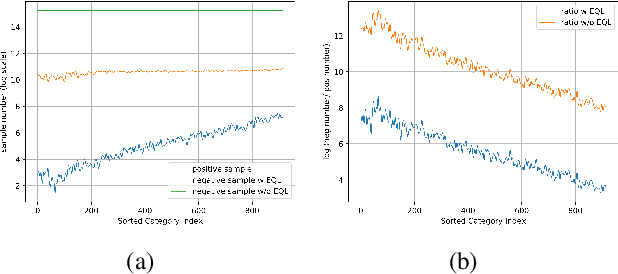
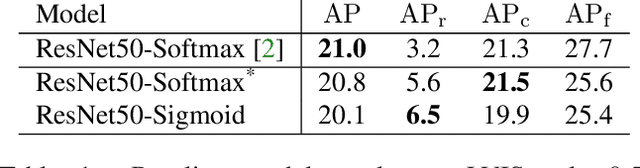


Recent object detection and instance segmentation tasks mainly focus on datasets with a relatively small set of categories, e.g. Pascal VOC with 20 classes and COCO with 80 classes. The new large vocabulary dataset LVIS brings new challenges to conventional methods. In this work, we propose an equalization loss to solve the long tail of rare categories problem. Combined with exploiting the data from detection datasets to alleviate the effect of missing-annotation problems during the training, our method achieves 5.1\% overall AP gain and 11.4\% AP gain of rare categories on LVIS benchmark without any bells and whistles compared to Mask R-CNN baseline. Finally we achieve 28.9 mask AP on the test-set of the LVIS and rank 1st place in LVIS Challenge 2019.
Learning an Efficient Network for Large-Scale Hierarchical Object Detection with Data Imbalance: 3rd Place Solution to Open Images Challenge 2019
Oct 26, 2019
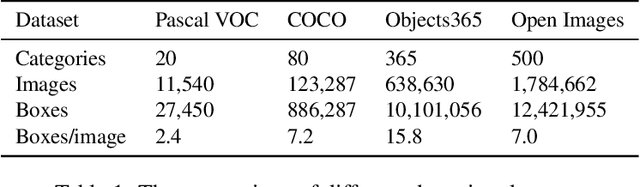
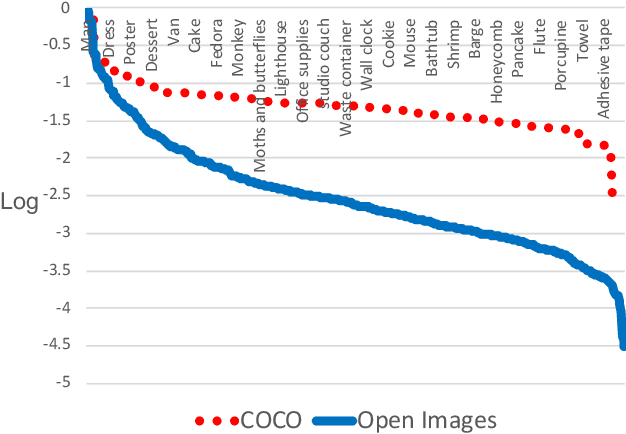
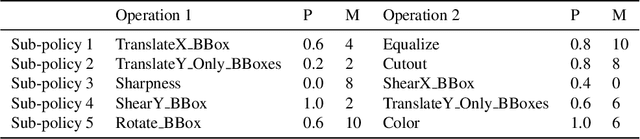
This report details our solution to the Google AI Open Images Challenge 2019 Object Detection Track. Based on our detailed analysis on the Open Images dataset, it is found that there are four typical features: large-scale, hierarchical tag system, severe annotation incompleteness and data imbalance. Considering these characteristics, many strategies are employed, including larger backbone, distributed softmax loss, class-aware sampling, expert model, and heavier classifier. In virtue of these effective strategies, our best single model could achieve a mAP of 61.90. After ensemble, the final mAP is boosted to 67.17 in the public leaderboard and 64.21 in the private leaderboard, which earns 3rd place in the Open Images Challenge 2019.