 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEqualization Loss for Large Vocabulary Instance Segmentation
Paper and Code
Nov 12, 2019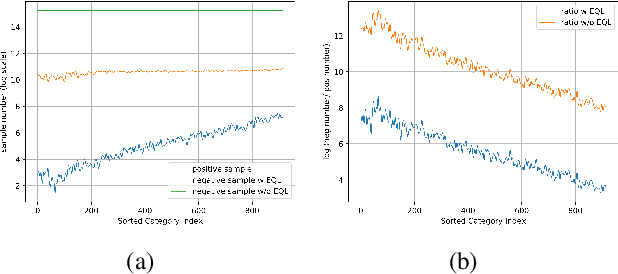
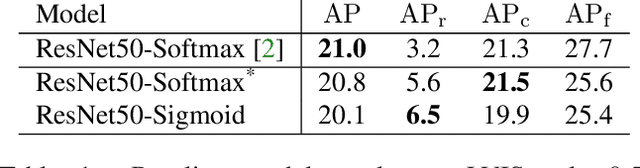


Recent object detection and instance segmentation tasks mainly focus on datasets with a relatively small set of categories, e.g. Pascal VOC with 20 classes and COCO with 80 classes. The new large vocabulary dataset LVIS brings new challenges to conventional methods. In this work, we propose an equalization loss to solve the long tail of rare categories problem. Combined with exploiting the data from detection datasets to alleviate the effect of missing-annotation problems during the training, our method achieves 5.1\% overall AP gain and 11.4\% AP gain of rare categories on LVIS benchmark without any bells and whistles compared to Mask R-CNN baseline. Finally we achieve 28.9 mask AP on the test-set of the LVIS and rank 1st place in LVIS Challenge 2019.