 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADACS: Towards Higher-Order Reasoning using Action Recognition in Autonomous Vehicles
Sep 28, 2022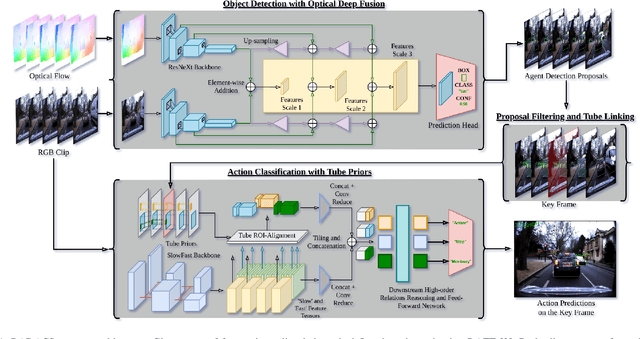
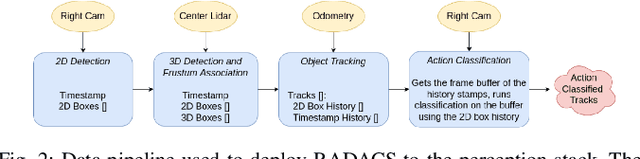


When applied to autonomous vehicle settings, action recognition can help enrich an environment model's understanding of the world and improve plans for future action. Towards these improvements in autonomous vehicle decision-making, we propose in this work a novel two-stage online action recognition system, termed RADACS. RADACS formulates the problem of active agent detection and adapts ideas about actor-context relations from human activity recognition in a straightforward two-stage pipeline for action detection and classification. We show that our proposed scheme can outperform the baseline on the ICCV2021 Road Challenge dataset and by deploying it on a real vehicle platform, we demonstrate how a higher-order understanding of agent actions in an environment can improve decisions on a real autonomous vehicle.
RefineMask: Towards High-Quality Instance Segmentation with Fine-Grained Features
Apr 17, 2021
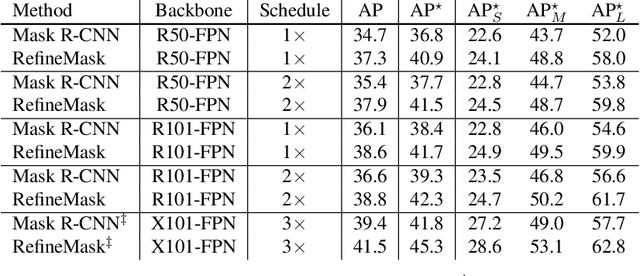
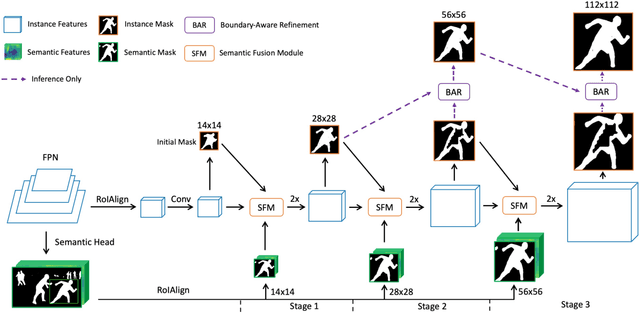
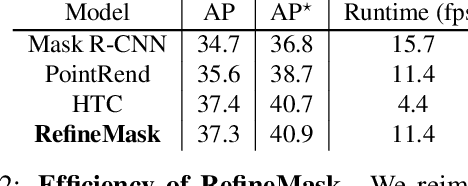
The two-stage methods for instance segmentation, e.g. Mask R-CNN, have achieved excellent performance recently. However, the segmented masks are still very coarse due to the downsampling operations in both the feature pyramid and the instance-wise pooling process, especially for large objects. In this work, we propose a new method called RefineMask for high-quality instance segmentation of objects and scenes, which incorporates fine-grained features during the instance-wise segmenting process in a multi-stage manner. Through fusing more detailed information stage by stage, RefineMask is able to refine high-quality masks consistently. RefineMask succeeds in segmenting hard cases such as bent parts of objects that are over-smoothed by most previous methods and outputs accurate boundaries. Without bells and whistles, RefineMask yields significant gains of 2.6, 3.4, 3.8 AP over Mask R-CNN on COCO, LVIS, and Cityscapes benchmarks respectively at a small amount of additional computational cost. Furthermore, our single-model result outperforms the winner of the LVIS Challenge 2020 by 1.3 points on the LVIS test-dev set and establishes a new state-of-the-art. Code will be available at https://github.com/zhanggang001/RefineMask.
Fixing the Teacher-Student Knowledge Discrepancy in Distillation
Mar 31, 2021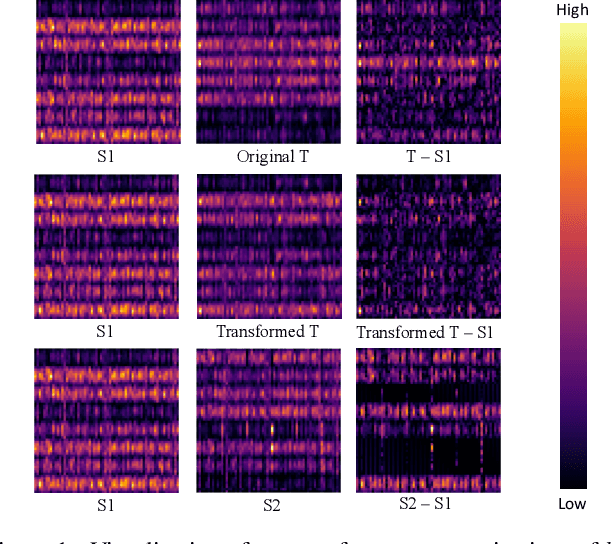



Training a small student network with the guidance of a larger teacher network is an effective way to promote the performance of the student. Despite the different types, the guided knowledge used to distill is always kept unchanged for different teacher and student pairs in previous knowledge distillation methods. However, we find that teacher and student models with different networks or trained from different initialization could have distinct feature representations among different channels. (e.g. the high activated channel for different categories). We name this incongruous representation of channels as teacher-student knowledge discrepancy in the distillation process. Ignoring the knowledge discrepancy problem of teacher and student models will make the learning of student from teacher more difficult. To solve this problem, in this paper, we propose a novel student-dependent distillation method, knowledge consistent distillation, which makes teacher's knowledge more consistent with the student and provides the best suitable knowledge to different student networks for distillation. Extensive experiments on different datasets (CIFAR100, ImageNet, COCO) and tasks (image classification, object detection) reveal the widely existing knowledge discrepancy problem between teachers and students and demonstrate the effectiveness of our proposed method. Our method is very flexible that can be easily combined with other state-of-the-art approaches.
Differentiable Network Adaption with Elastic Search Space
Mar 30, 2021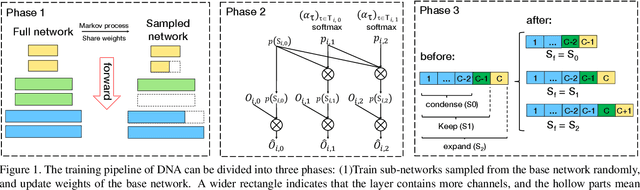
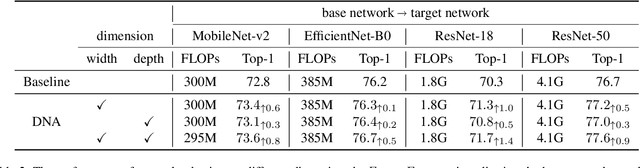
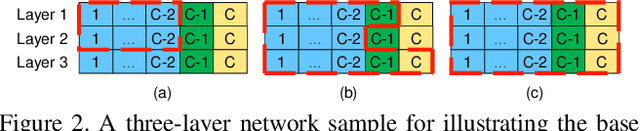
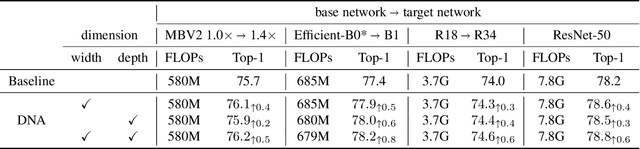
In this paper we propose a novel network adaption method called Differentiable Network Adaption (DNA), which can adapt an existing network to a specific computation budget by adjusting the width and depth in a differentiable manner. The gradient-based optimization allows DNA to achieve an automatic optimization of width and depth rather than previous heuristic methods that heavily rely on human priors. Moreover, we propose a new elastic search space that can flexibly condense or expand during the optimization process, allowing the network optimization of width and depth in a bi-direction manner. By DNA, we successfully achieve network architecture optimization by condensing and expanding in both width and depth dimensions. Extensive experiments on ImageNet demonstrate that DNA can adapt the existing network to meet different targeted computation requirements with better performance than previous methods. What's more, DNA can further improve the performance of high-accuracy networks obtained by state-of-the-art neural architecture search methods such as EfficientNet and MobileNet-v3.
Equalization Loss v2: A New Gradient Balance Approach for Long-tailed Object Detection
Dec 15, 2020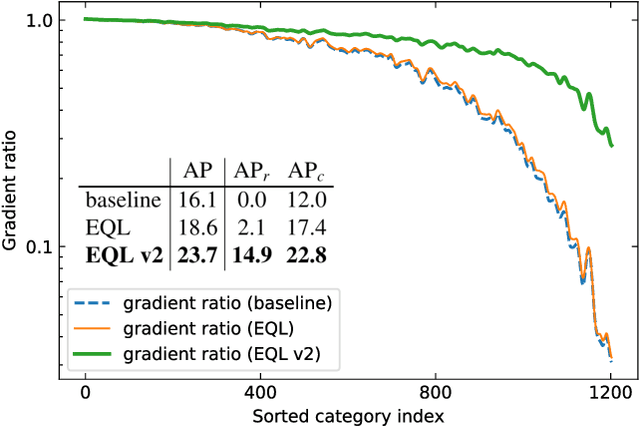

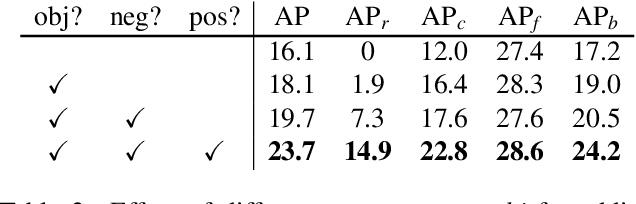
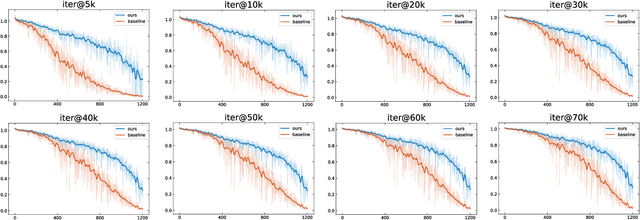
Recently proposed decoupled training methods emerge as a dominant paradigm for long-tailed object detection. But they require an extra fine-tuning stage, and the disjointed optimization of representation and classifier might lead to suboptimal results. However, end-to-end training methods, like equalization loss (EQL), still perform worse than decoupled training methods. In this paper, we reveal the main issue in long-tailed object detection is the imbalanced gradients between positives and negatives, and find that EQL does not solve it well. To address the problem of imbalanced gradients, we introduce a new version of equalization loss, called equalization loss v2 (EQL v2), a novel gradient guided reweighing mechanism that re-balances the training process for each category independently and equally. Extensive experiments are performed on the challenging LVIS benchmark. EQL v2 outperforms origin EQL by about 4 points overall AP with 14-18 points improvements on the rare categories. More importantly, It also surpasses decoupled training methods. Without further tuning for the Open Images dataset, EQL v2 improves EQL by 6.3 points AP, showing strong generalization ability. Codes will be released at https://github.com/tztztztztz/eqlv2
Dynamic Graph: Learning Instance-aware Connectivity for Neural Networks
Oct 02, 2020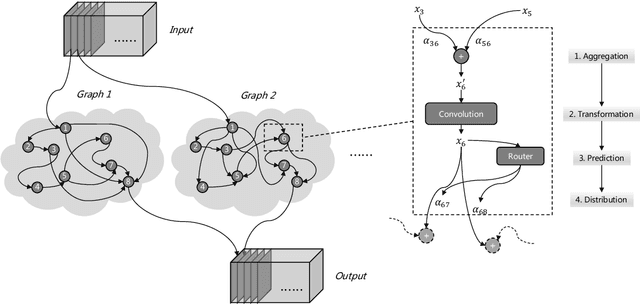
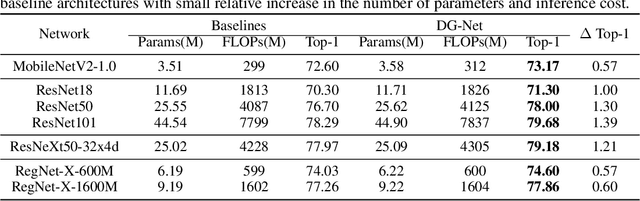
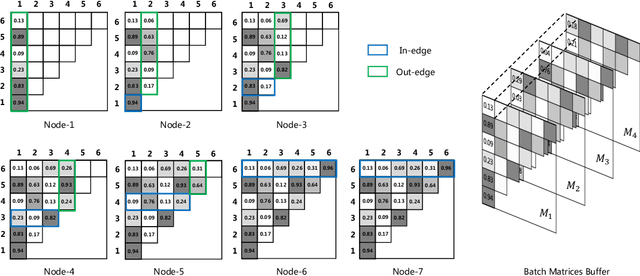
One practice of employing deep neural networks is to apply the same architecture to all the input instances. However, a fixed architecture may not be representative enough for data with high diversity. To promote the model capacity, existing approaches usually employ larger convolutional kernels or deeper network structure, which may increase the computational cost. In this paper, we address this issue by raising the Dynamic Graph Network (DG-Net). The network learns the instance-aware connectivity, which creates different forward paths for different instances. Specifically, the network is initialized as a complete directed acyclic graph, where the nodes represent convolutional blocks and the edges represent the connection paths. We generate edge weights by a learnable module \textit{router} and select the edges whose weights are larger than a threshold, to adjust the connectivity of the neural network structure. Instead of using the same path of the network, DG-Net aggregates features dynamically in each node, which allows the network to have more representation ability. To facilitate the training, we represent the network connectivity of each sample in an adjacency matrix. The matrix is updated to aggregate features in the forward pass, cached in the memory, and used for gradient computing in the backward pass. We verify the effectiveness of our method with several static architectures, including MobileNetV2, ResNet, ResNeXt, and RegNet. Extensive experiments are performed on ImageNet classification and COCO object detection, which shows the effectiveness and generalization ability of our approach.
MimicDet: Bridging the Gap Between One-Stage and Two-Stage Object Detection
Sep 24, 2020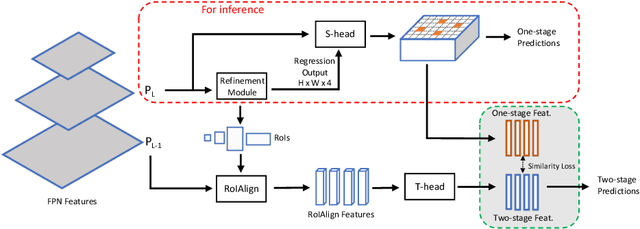
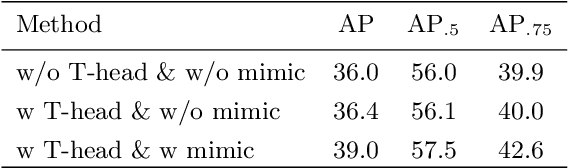
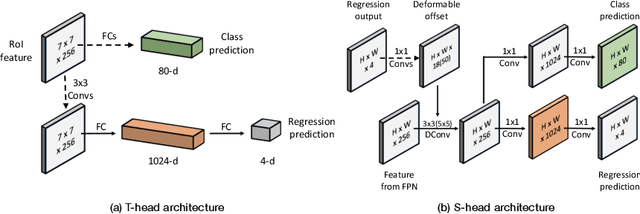
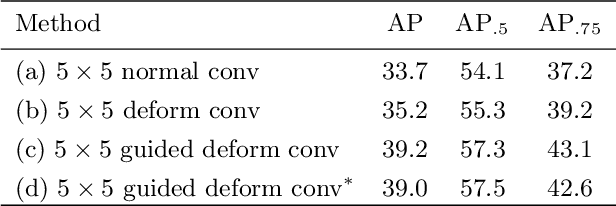
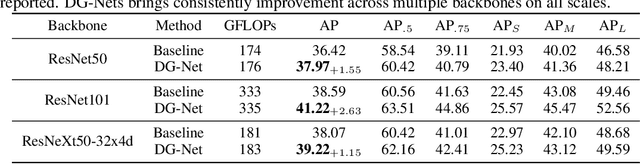
Modern object detection methods can be divided into one-stage approaches and two-stage ones. One-stage detectors are more efficient owing to straightforward architectures, but the two-stage detectors still take the lead in accuracy. Although recent work try to improve the one-stage detectors by imitating the structural design of the two-stage ones, the accuracy gap is still significant. In this paper, we propose MimicDet, a novel and efficient framework to train a one-stage detector by directly mimic the two-stage features, aiming to bridge the accuracy gap between one-stage and two-stage detectors. Unlike conventional mimic methods, MimicDet has a shared backbone for one-stage and two-stage detectors, then it branches into two heads which are well designed to have compatible features for mimicking. Thus MimicDet can be end-to-end trained without the pre-train of the teacher network. And the cost does not increase much, which makes it practical to adopt large networks as backbones. We also make several specialized designs such as dual-path mimicking and staggered feature pyramid to facilitate the mimicking process. Experiments on the challenging COCO detection benchmark demonstrate the effectiveness of MimicDet. It achieves 46.1 mAP with ResNeXt-101 backbone on the COCO test-dev set, which significantly surpasses current state-of-the-art methods.
1st Place Solution of LVIS Challenge 2020: A Good Box is not a Guarantee of a Good Mask
Sep 03, 2020This article introduces the solutions of the team lvisTraveler for LVIS Challenge 2020. In this work, two characteristics of LVIS dataset are mainly considered: the long-tailed distribution and high quality instance segmentation mask. We adopt a two-stage training pipeline. In the first stage, we incorporate EQL and self-training to learn generalized representation. In the second stage, we utilize Balanced GroupSoftmax to promote the classifier, and propose a novel proposal assignment strategy and a new balanced mask loss for mask head to get more precise mask predictions. Finally, we achieve 41.5 and 41.2 AP on LVIS v1.0 val and test-dev splits respectively, outperforming the baseline based on X101-FPN-MaskRCNN by a large margin.
Learning Connectivity of Neural Networks from a Topological Perspective
Aug 19, 2020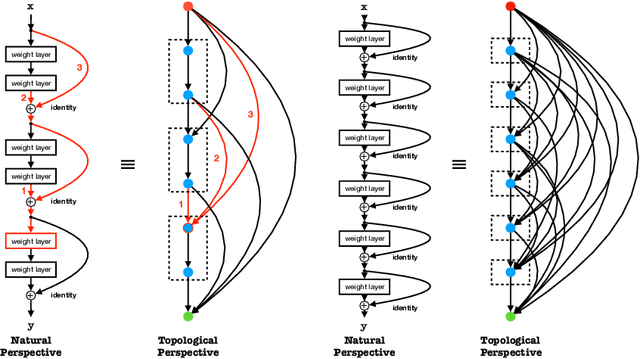
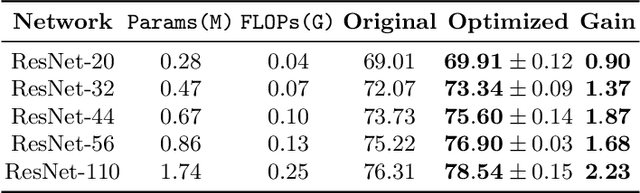
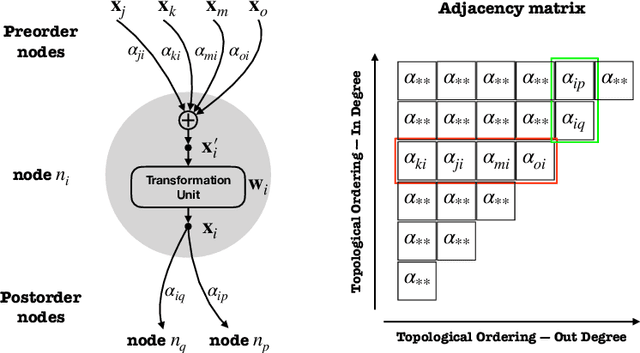
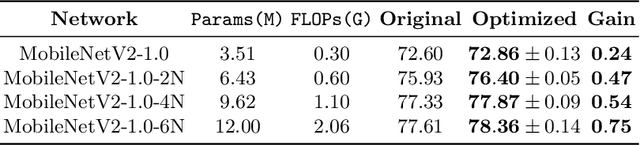
Seeking effective neural networks is a critical and practical field in deep learning. Besides designing the depth, type of convolution, normalization, and nonlinearities, the topological connectivity of neural networks is also important. Previous principles of rule-based modular design simplify the difficulty of building an effective architecture, but constrain the possible topologies in limited spaces. In this paper, we attempt to optimize the connectivity in neural networks. We propose a topological perspective to represent a network into a complete graph for analysis, where nodes carry out aggregation and transformation of features, and edges determine the flow of information. By assigning learnable parameters to the edges which reflect the magnitude of connections, the learning process can be performed in a differentiable manner. We further attach auxiliary sparsity constraint to the distribution of connectedness, which promotes the learned topology focus on critical connections. This learning process is compatible with existing networks and owns adaptability to larger search spaces and different tasks. Quantitative results of experiments reflect the learned connectivity is superior to traditional rule-based ones, such as random, residual, and complete. In addition, it obtains significant improvements in image classification and object detection without introducing excessive computation burden.
DMCP: Differentiable Markov Channel Pruning for Neural Networks
May 08, 2020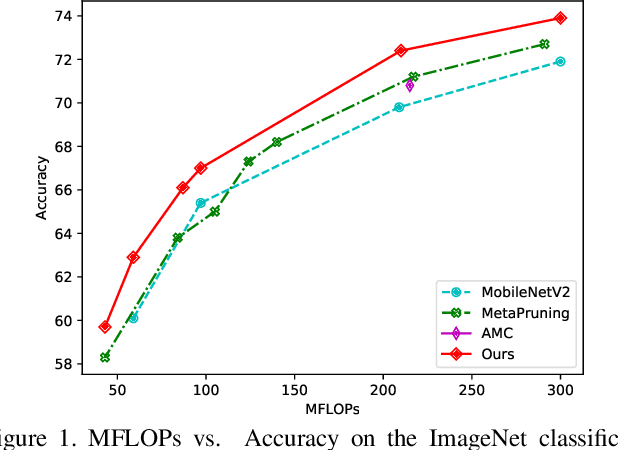
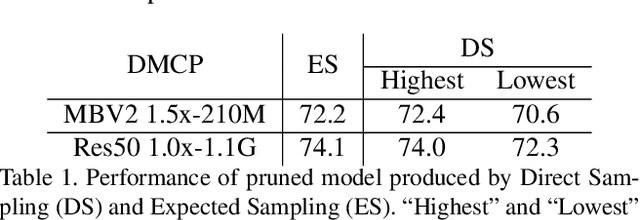
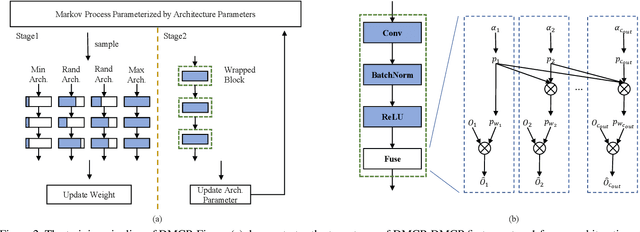
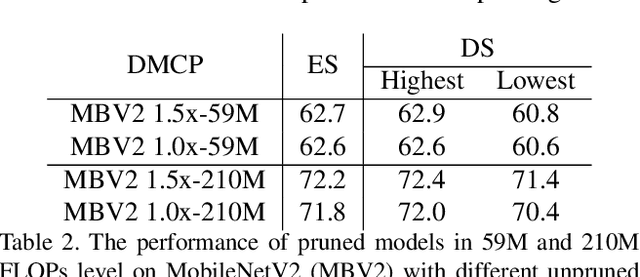
Recent works imply that the channel pruning can be regarded as searching optimal sub-structure from unpruned networks. However, existing works based on this observation require training and evaluating a large number of structures, which limits their application. In this paper, we propose a novel differentiable method for channel pruning, named Differentiable Markov Channel Pruning (DMCP), to efficiently search the optimal sub-structure. Our method is differentiable and can be directly optimized by gradient descent with respect to standard task loss and budget regularization (e.g. FLOPs constraint). In DMCP, we model the channel pruning as a Markov process, in which each state represents for retaining the corresponding channel during pruning, and transitions between states denote the pruning process. In the end, our method is able to implicitly select the proper number of channels in each layer by the Markov process with optimized transitions. To validate the effectiveness of our method, we perform extensive experiments on Imagenet with ResNet and MobilenetV2. Results show our method can achieve consistent improvement than state-of-the-art pruning methods in various FLOPs settings. The code is available at https://github.com/zx55/dmcp