 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFixing the Teacher-Student Knowledge Discrepancy in Distillation
Mar 31, 2021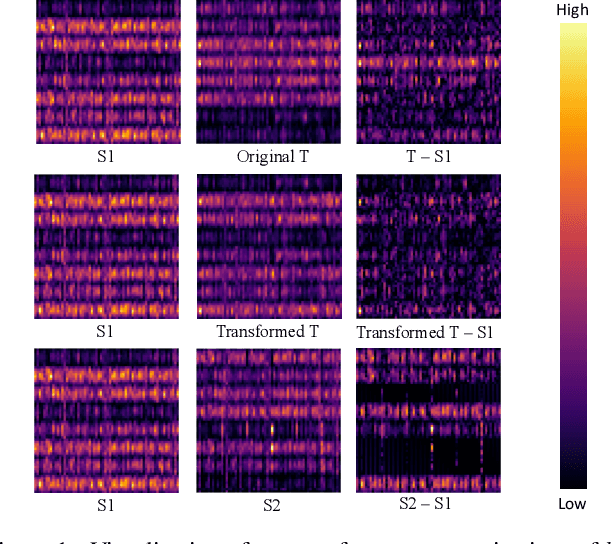



Training a small student network with the guidance of a larger teacher network is an effective way to promote the performance of the student. Despite the different types, the guided knowledge used to distill is always kept unchanged for different teacher and student pairs in previous knowledge distillation methods. However, we find that teacher and student models with different networks or trained from different initialization could have distinct feature representations among different channels. (e.g. the high activated channel for different categories). We name this incongruous representation of channels as teacher-student knowledge discrepancy in the distillation process. Ignoring the knowledge discrepancy problem of teacher and student models will make the learning of student from teacher more difficult. To solve this problem, in this paper, we propose a novel student-dependent distillation method, knowledge consistent distillation, which makes teacher's knowledge more consistent with the student and provides the best suitable knowledge to different student networks for distillation. Extensive experiments on different datasets (CIFAR100, ImageNet, COCO) and tasks (image classification, object detection) reveal the widely existing knowledge discrepancy problem between teachers and students and demonstrate the effectiveness of our proposed method. Our method is very flexible that can be easily combined with other state-of-the-art approaches.
Deep Self-Learning From Noisy Labels
Aug 20, 2019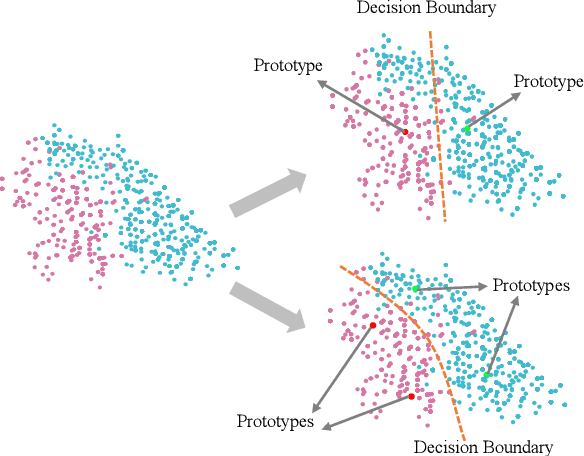
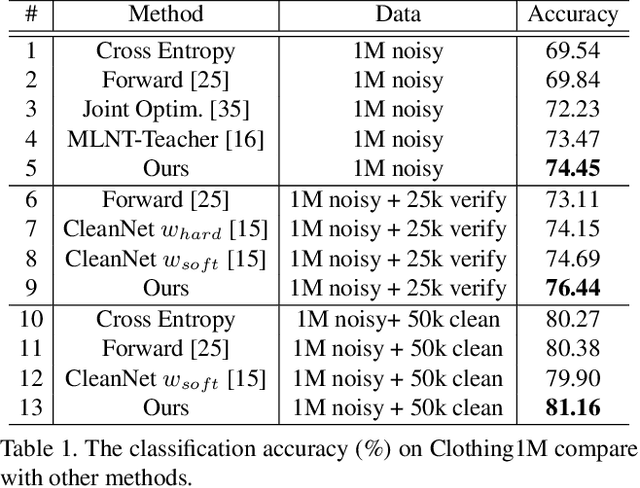
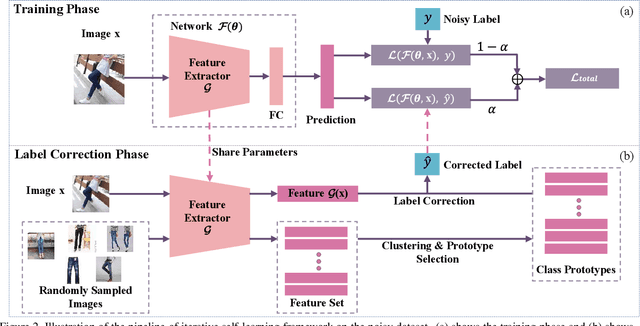
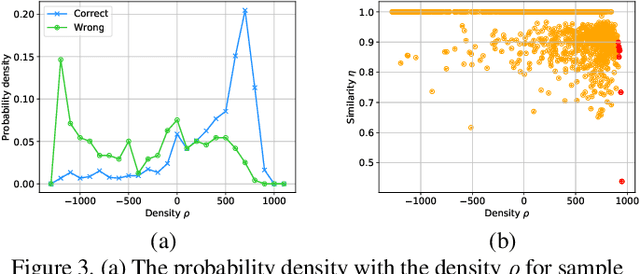
ConvNets achieve good results when training from clean data, but learning from noisy labels significantly degrades performances and remains challenging. Unlike previous works constrained by many conditions, making them infeasible to real noisy cases, this work presents a novel deep self-learning framework to train a robust network on the real noisy datasets without extra supervision. The proposed approach has several appealing benefits. (1) Different from most existing work, it does not rely on any assumption on the distribution of the noisy labels, making it robust to real noises. (2) It does not need extra clean supervision or accessorial network to help training. (3) A self-learning framework is proposed to train the network in an iterative end-to-end manner, which is effective and efficient. Extensive experiments in challenging benchmarks such as Clothing1M and Food101-N show that our approach outperforms its counterparts in all empirical settings.
Once a MAN: Towards Multi-Target Attack via Learning Multi-Target Adversarial Network Once
Aug 14, 2019
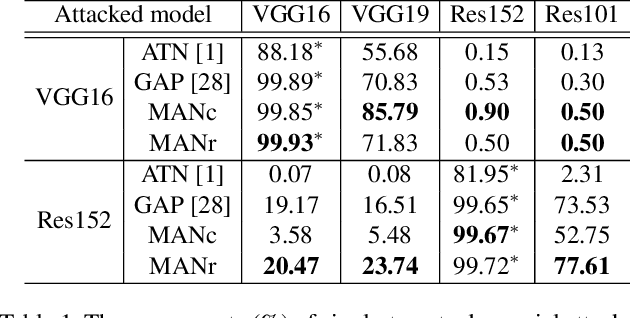


Modern deep neural networks are often vulnerable to adversarial samples. Based on the first optimization-based attacking method, many following methods are proposed to improve the attacking performance and speed. Recently, generation-based methods have received much attention since they directly use feed-forward networks to generate the adversarial samples, which avoid the time-consuming iterative attacking procedure in optimization-based and gradient-based methods. However, current generation-based methods are only able to attack one specific target (category) within one model, thus making them not applicable to real classification systems that often have hundreds/thousands of categories. In this paper, we propose the first Multi-target Adversarial Network (MAN), which can generate multi-target adversarial samples with a single model. By incorporating the specified category information into the intermediate features, it can attack any category of the target classification model during runtime. Experiments show that the proposed MAN can produce stronger attack results and also have better transferability than previous state-of-the-art methods in both multi-target attack task and single-target attack task. We further use the adversarial samples generated by our MAN to improve the robustness of the classification model. It can also achieve better classification accuracy than other methods when attacked by various methods.