 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELF-EMO: Emotional Self-Evolution from Recognition to Consistent Expression
Apr 20, 2026Emotion Recognition in Conversation (ERC) has become a fundamental capability for large language models (LLMs) in human-centric interaction. Beyond accurate recognition, coherent emotional expression is also crucial, yet both are limited by the scarcity and static nature of high-quality annotated data. In this work, we propose SELF-EMO, a self-evolution framework grounded in the hypothesis that better emotion prediction leads to more consistent emotional responses. We introduce two auxiliary tasks, emotional understanding and emotional expression, and design a role-based self-play paradigm where the model acts as both an emotion recognizer and a dialogue responder. Through iterative interactions, the model generates diverse conversational trajectories, enabling scalable data generation. To ensure quality, we adopt a data flywheel mechanism that filters candidate predictions and responses using a smoothed IoU-based reward and feeds selected samples back for continuous self-improvement without external supervision. We further develop SELF-GRPO, a reinforcement learning algorithm that stabilizes optimization with multi-label alignment rewards and group-level consistency signals. Experiments on IEMOCAP, MELD, and EmoryNLP show that SELF-EMO achieves state-of-the-art performance, improving accuracy by +6.33% on Qwen3-4B and +8.54% on Qwen3-8B, demonstrating strong effectiveness and generalization.
Language-based Trial and Error Falls Behind in the Era of Experience
Jan 29, 2026While Large Language Models (LLMs) excel in language-based agentic tasks, their applicability to unseen, nonlinguistic environments (e.g., symbolic or spatial tasks) remains limited. Previous work attributes this performance gap to the mismatch between the pretraining distribution and the testing distribution. In this work, we demonstrate the primary bottleneck is the prohibitive cost of exploration: mastering these tasks requires extensive trial-and-error, which is computationally unsustainable for parameter-heavy LLMs operating in a high dimensional semantic space. To address this, we propose SCOUT (Sub-Scale Collaboration On Unseen Tasks), a novel framework that decouples exploration from exploitation. We employ lightweight "scouts" (e.g., small MLPs) to probe environmental dynamics at a speed and scale far exceeding LLMs. The collected trajectories are utilized to bootstrap the LLM via Supervised Fine-Tuning (SFT), followed by multi-turn Reinforcement Learning (RL) to activate its latent world knowledge. Empirically, SCOUT enables a Qwen2.5-3B-Instruct model to achieve an average score of 0.86, significantly outperforming proprietary models, including Gemini-2.5-Pro (0.60), while saving about 60% GPU hours consumption.
Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training
May 11, 2024



In this report, we introduce Piccolo2, an embedding model that surpasses other models in the comprehensive evaluation over 6 tasks on CMTEB benchmark, setting a new state-of-the-art. Piccolo2 primarily leverages an efficient multi-task hybrid loss training approach, effectively harnessing textual data and labels from diverse downstream tasks. In addition, Piccolo2 scales up the embedding dimension and uses MRL training to support more flexible vector dimensions. The latest information of piccolo models can be accessed via: https://huggingface.co/sensenova/
One to Transfer All: A Universal Transfer Framework for Vision Foundation Model with Few Data
Nov 24, 2021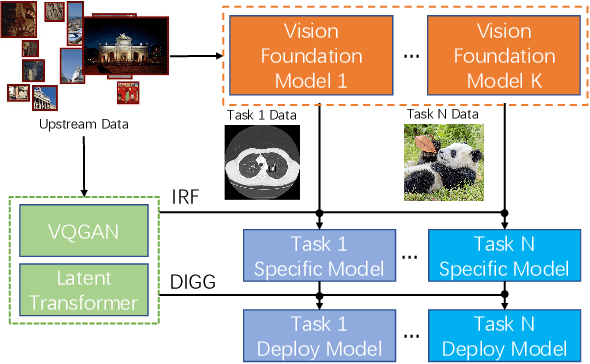
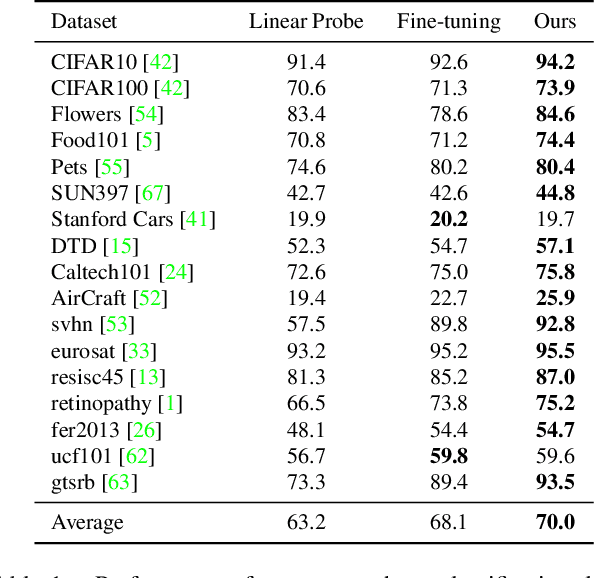
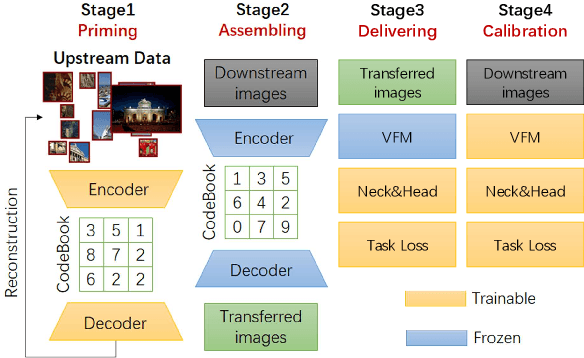

The foundation model is not the last chapter of the model production pipeline. Transferring with few data in a general way to thousands of downstream tasks is becoming a trend of the foundation model's application. In this paper, we proposed a universal transfer framework: One to Transfer All (OTA) to transfer any Vision Foundation Model (VFM) to any downstream tasks with few downstream data. We first transfer a VFM to a task-specific model by Image Re-representation Fine-tuning (IRF) then distilling knowledge from a task-specific model to a deployed model with data produced by Downstream Image-Guided Generation (DIGG). OTA has no dependency on upstream data, VFM, and downstream tasks when transferring. It also provides a way for VFM researchers to release their upstream information for better transferring but not leaking data due to privacy requirements. Massive experiments validate the effectiveness and superiority of our methods in few data setting. Our code will be released.
INTERN: A New Learning Paradigm Towards General Vision
Nov 16, 2021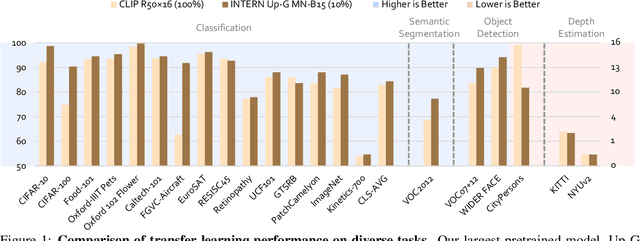
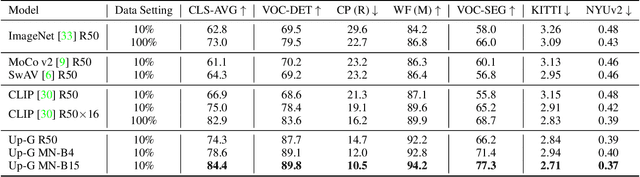
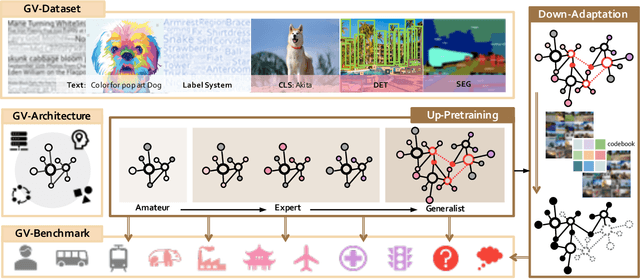
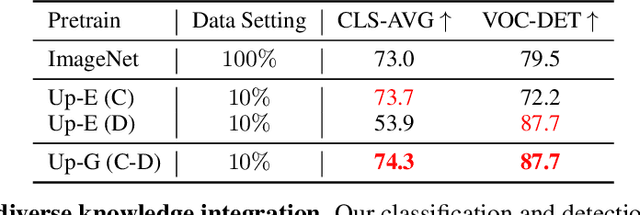
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.
Fixing the Teacher-Student Knowledge Discrepancy in Distillation
Mar 31, 2021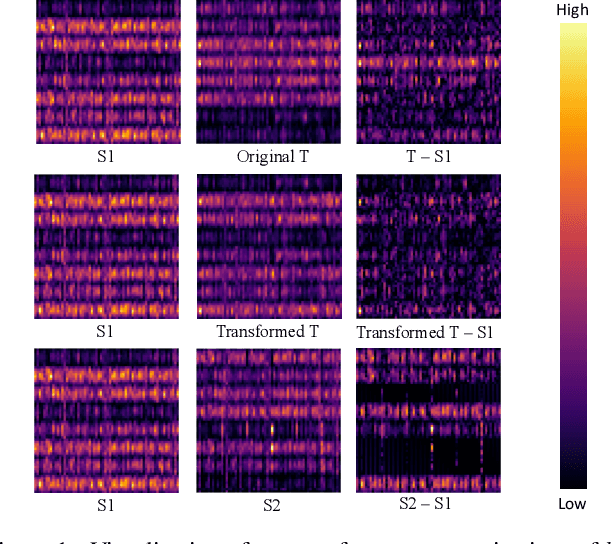



Training a small student network with the guidance of a larger teacher network is an effective way to promote the performance of the student. Despite the different types, the guided knowledge used to distill is always kept unchanged for different teacher and student pairs in previous knowledge distillation methods. However, we find that teacher and student models with different networks or trained from different initialization could have distinct feature representations among different channels. (e.g. the high activated channel for different categories). We name this incongruous representation of channels as teacher-student knowledge discrepancy in the distillation process. Ignoring the knowledge discrepancy problem of teacher and student models will make the learning of student from teacher more difficult. To solve this problem, in this paper, we propose a novel student-dependent distillation method, knowledge consistent distillation, which makes teacher's knowledge more consistent with the student and provides the best suitable knowledge to different student networks for distillation. Extensive experiments on different datasets (CIFAR100, ImageNet, COCO) and tasks (image classification, object detection) reveal the widely existing knowledge discrepancy problem between teachers and students and demonstrate the effectiveness of our proposed method. Our method is very flexible that can be easily combined with other state-of-the-art approaches.
Residual Knowledge Distillation
Feb 21, 2020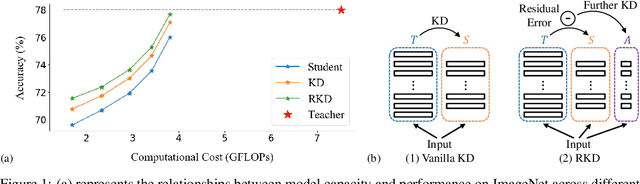
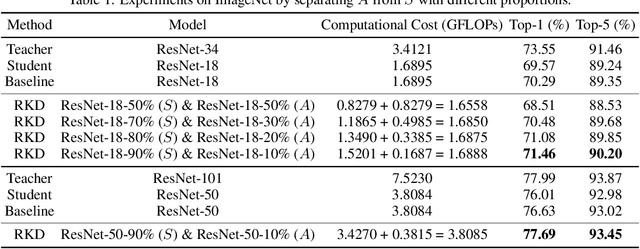
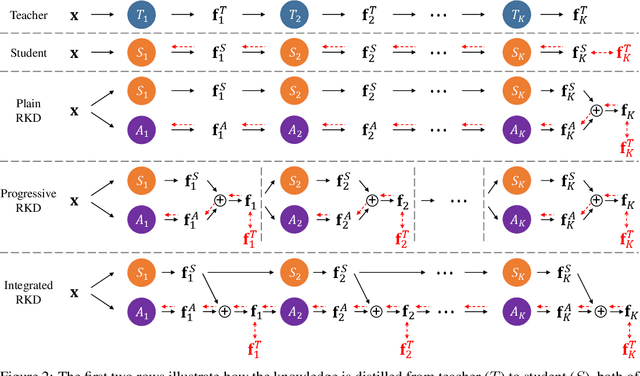
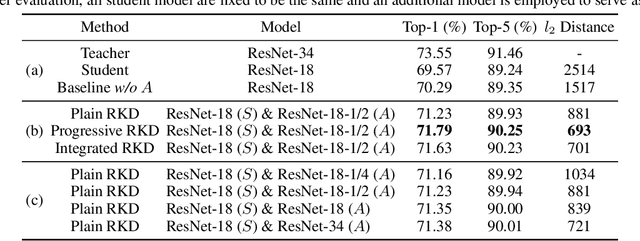
Knowledge distillation (KD) is one of the most potent ways for model compression. The key idea is to transfer the knowledge from a deep teacher model (T) to a shallower student (S). However, existing methods suffer from performance degradation due to the substantial gap between the learning capacities of S and T. To remedy this problem, this work proposes Residual Knowledge Distillation (RKD), which further distills the knowledge by introducing an assistant (A). Specifically, S is trained to mimic the feature maps of T, and A aids this process by learning the residual error between them. In this way, S and A complement with each other to get better knowledge from T. Furthermore, we devise an effective method to derive S and A from a given model without increasing the total computational cost. Extensive experiments show that our approach achieves appealing results on popular classification datasets, CIFAR-100 and ImageNet, surpassing state-of-the-art methods.
P2SGrad: Refined Gradients for Optimizing Deep Face Models
May 07, 2019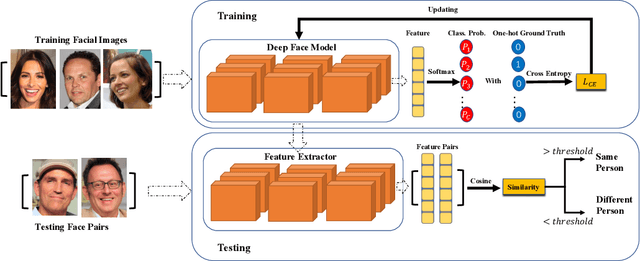
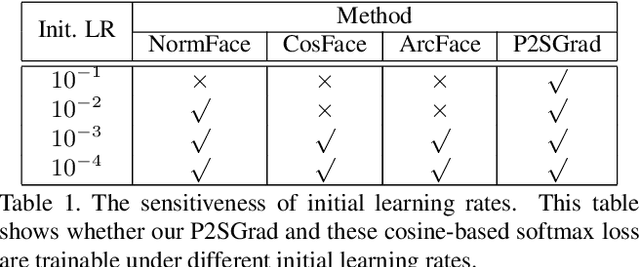
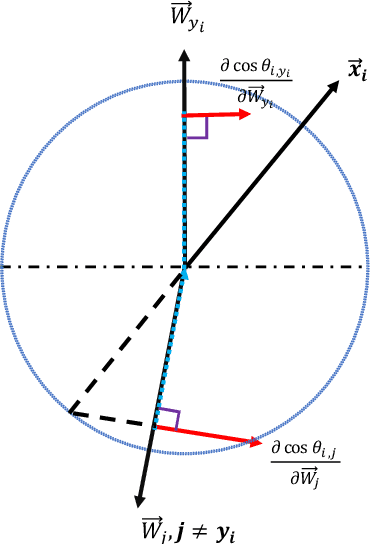
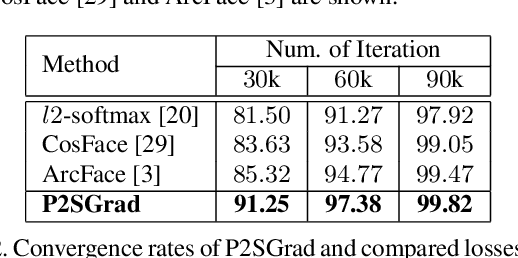
Cosine-based softmax losses significantly improve the performance of deep face recognition networks. However, these losses always include sensitive hyper-parameters which can make training process unstable, and it is very tricky to set suitable hyper parameters for a specific dataset. This paper addresses this challenge by directly designing the gradients for adaptively training deep neural networks. We first investigate and unify previous cosine softmax losses by analyzing their gradients. This unified view inspires us to propose a novel gradient called P2SGrad (Probability-to-Similarity Gradient), which leverages a cosine similarity instead of classification probability to directly update the testing metrics for updating neural network parameters. P2SGrad is adaptive and hyper-parameter free, which makes the training process more efficient and faster. We evaluate our P2SGrad on three face recognition benchmarks, LFW, MegaFace, and IJB-C. The results show that P2SGrad is stable in training, robust to noise, and achieves state-of-the-art performance on all the three benchmarks.
Feature Matters: A Stage-by-Stage Approach for Knowledge Transfer
Dec 05, 2018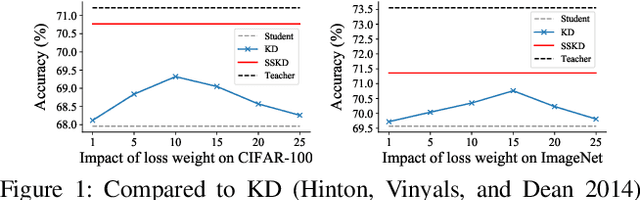

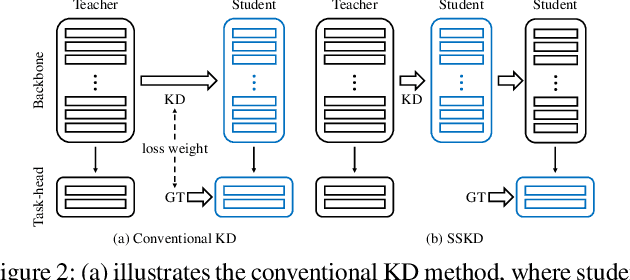
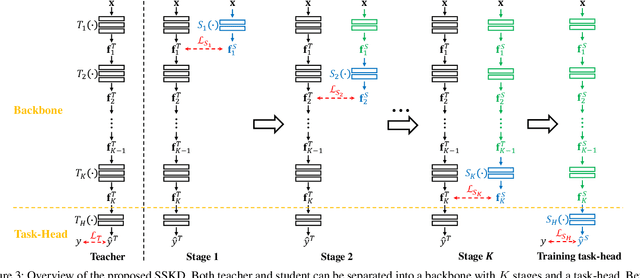
Convolutional Neural Networks (CNNs) become deeper and deeper in recent years, making the study of model acceleration imperative. It is a common practice to employ a shallow network, called student, to learn from a deep one, which is termed as teacher. Prior work made many attempts to transfer different types of knowledge from teacher to student, however, there are two problems remaining unsolved. Firstly, the knowledge used by existing methods is usually manually defined, which may not be consistent with the information learned by the original model. Secondly, there lacks an effective training scheme for the transfer process, leading to degradation of performance. In this work, we argue that feature is the most important knowledge from teacher. It is sufficient for student to achieve appealing performance by just learning similar features as teacher without any processing. Based on this discovery, we further present an efficient learning strategy, which is to make student mimic features of teacher stage by stage. Extensive experiments suggest that the proposed approach significantly narrows down the gap between student and teacher, and shows strong stability on various tasks, ie classification and detection, outperforming the state-of-the-art methods.
A Novel Hybrid Machine Learning Model for Auto-Classification of Retinal Diseases
Jun 17, 2018
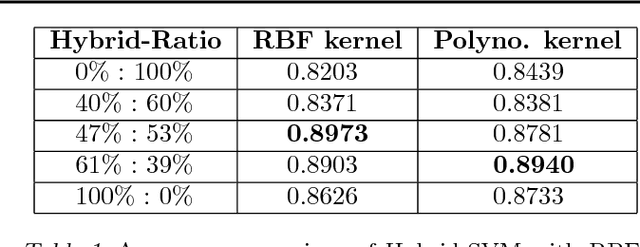
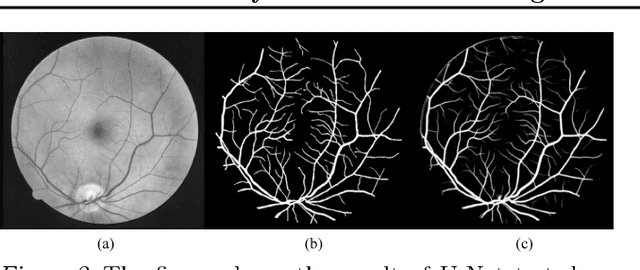
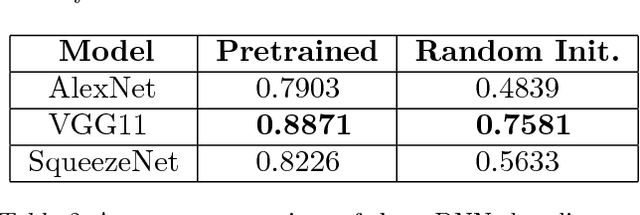
Automatic clinical diagnosis of retinal diseases has emerged as a promising approach to facilitate discovery in areas with limited access to specialists. We propose a novel visual-assisted diagnosis hybrid model based on the support vector machine (SVM) and deep neural networks (DNNs). The model incorporates complementary strengths of DNNs and SVM. Furthermore, we present a new clinical retina label collection for ophthalmology incorporating 32 retina diseases classes. Using EyeNet, our model achieves 89.73% diagnosis accuracy and the model performance is comparable to the professional ophthalmologists.
* Accepted at the Joint ICML and IJCAI Workshop on Computational Biology (ICML-IJCAI WCB) to be held in Stockholm SWEDEN, 2018. Referring to https://sites.google.com/view/wcb2018/accepted-papers?authuser=0