 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniG3D: A Unified 3D Object Generation Dataset
Jun 19, 2023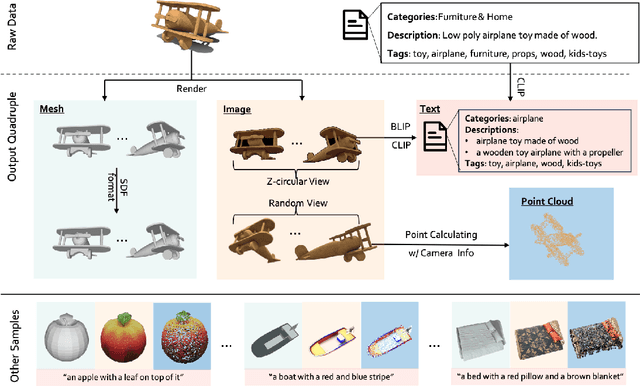
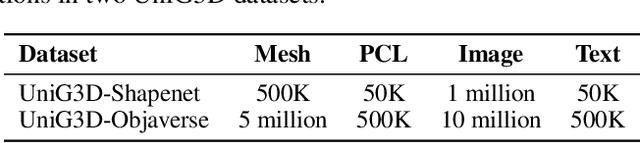
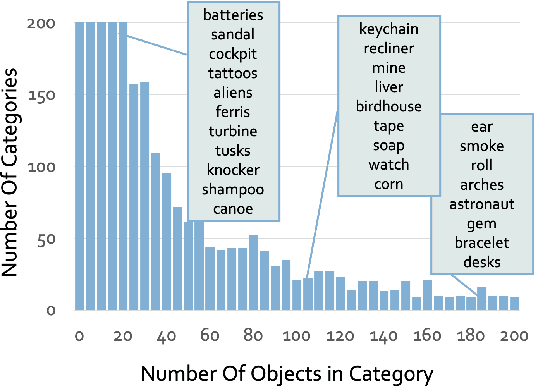
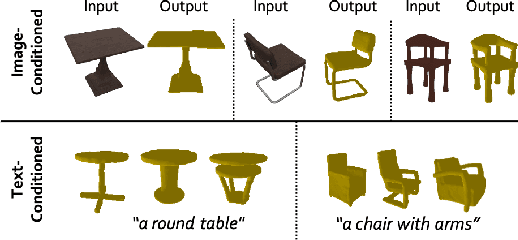
The field of generative AI has a transformative impact on various areas, including virtual reality, autonomous driving, the metaverse, gaming, and robotics. Among these applications, 3D object generation techniques are of utmost importance. This technique has unlocked fresh avenues in the realm of creating, customizing, and exploring 3D objects. However, the quality and diversity of existing 3D object generation methods are constrained by the inadequacies of existing 3D object datasets, including issues related to text quality, the incompleteness of multi-modal data representation encompassing 2D rendered images and 3D assets, as well as the size of the dataset. In order to resolve these issues, we present UniG3D, a unified 3D object generation dataset constructed by employing a universal data transformation pipeline on Objaverse and ShapeNet datasets. This pipeline converts each raw 3D model into comprehensive multi-modal data representation <text, image, point cloud, mesh> by employing rendering engines and multi-modal models. These modules ensure the richness of textual information and the comprehensiveness of data representation. Remarkably, the universality of our pipeline refers to its ability to be applied to any 3D dataset, as it only requires raw 3D data. The selection of data sources for our dataset is based on their scale and quality. Subsequently, we assess the effectiveness of our dataset by employing Point-E and SDFusion, two widely recognized methods for object generation, tailored to the prevalent 3D representations of point clouds and signed distance functions. Our dataset is available at: https://unig3d.github.io.
Latent Distribution Adjusting for Face Anti-Spoofing
May 16, 2023



With the development of deep learning, the field of face anti-spoofing (FAS) has witnessed great progress. FAS is usually considered a classification problem, where each class is assumed to contain a single cluster optimized by softmax loss. In practical deployment, one class can contain several local clusters, and a single-center is insufficient to capture the inherent structure of the FAS data. However, few approaches consider large distribution discrepancies in the field of FAS. In this work, we propose a unified framework called Latent Distribution Adjusting (LDA) with properties of latent, discriminative, adaptive, generic to improve the robustness of the FAS model by adjusting complex data distribution with multiple prototypes. 1) Latent. LDA attempts to model the data of each class as a Gaussian mixture distribution, and acquire a flexible number of centers for each class in the last fully connected layer implicitly. 2) Discriminative. To enhance the intra-class compactness and inter-class discrepancy, we propose a margin-based loss for providing distribution constrains for prototype learning. 3) Adaptive. To make LDA more efficient and decrease redundant parameters, we propose Adaptive Prototype Selection (APS) by selecting the appropriate number of centers adaptively according to different distributions. 4) Generic. Furthermore, LDA can adapt to unseen distribution by utilizing very few training data without re-training. Extensive experiments demonstrate that our framework can 1) make the final representation space both intra-class compact and inter-class separable, 2) outperform the state-of-the-art methods on multiple standard FAS benchmarks.
Bamboo: Building Mega-Scale Vision Dataset Continually with Human-Machine Synergy
Mar 15, 2022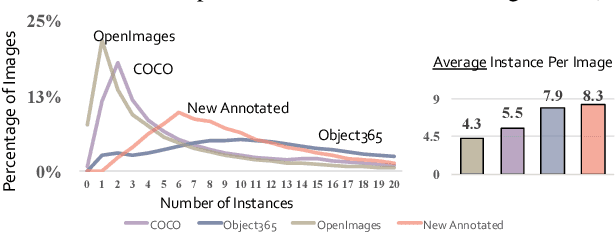

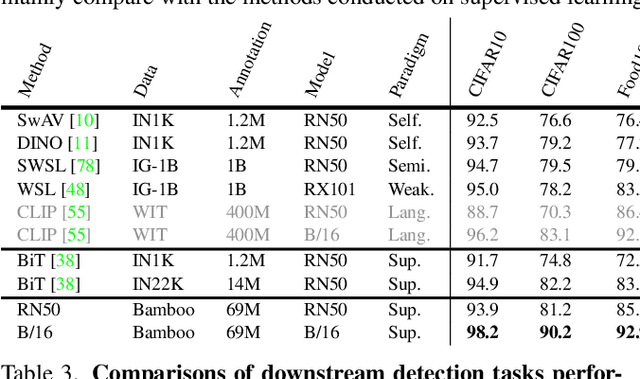
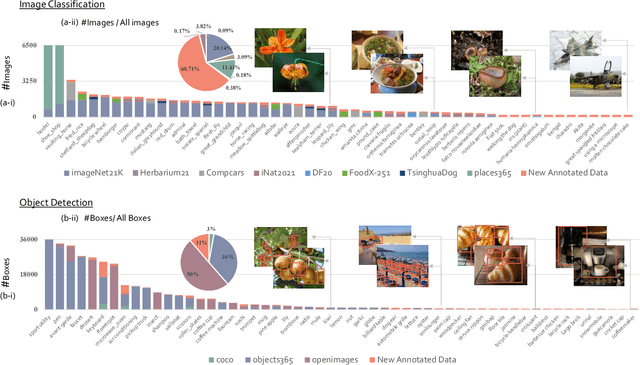
Large-scale datasets play a vital role in computer vision. Existing datasets are either collected according to heuristic label systems or annotated blindly without differentiation to samples, making them inefficient and unscalable. How to systematically collect, annotate and build a mega-scale dataset remains an open question. In this work, we advocate building a high-quality vision dataset actively and continually on a comprehensive label system. Specifically, we contribute Bamboo Dataset, a mega-scale and information-dense dataset for both classification and detection. Bamboo aims to populate the comprehensive categories with 69M image classification annotations and 170,586 object bounding box annotations. Compared to ImageNet22K and Objects365, models pre-trained on Bamboo achieve superior performance among various downstream tasks (6.2% gains on classification and 2.1% gains on detection). In addition, we provide valuable observations regarding large-scale pre-training from over 1,000 experiments. Due to its scalable nature on both label system and annotation pipeline, Bamboo will continue to grow and benefit from the collective efforts of the community, which we hope would pave the way for more general vision models.
INTERN: A New Learning Paradigm Towards General Vision
Nov 16, 2021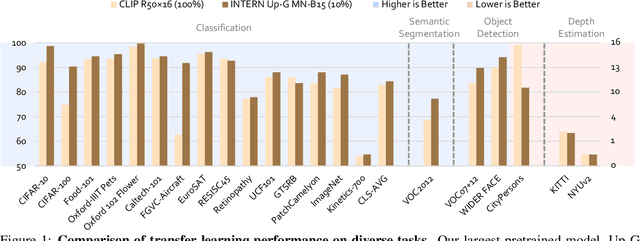
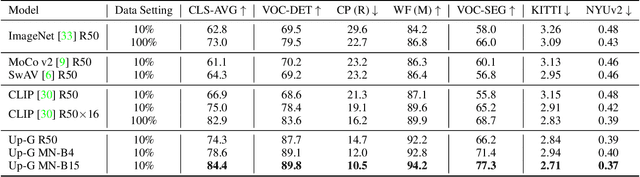
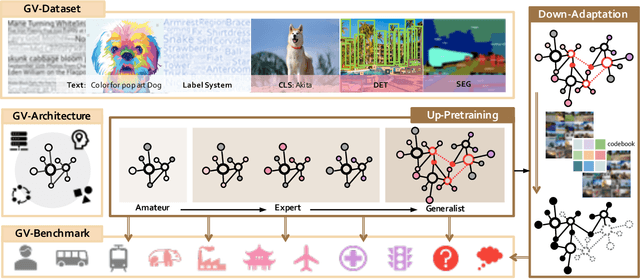
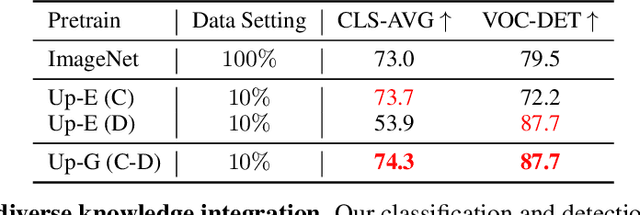
Enormous waves of technological innovations over the past several years, marked by the advances in AI technologies, are profoundly reshaping the industry and the society. However, down the road, a key challenge awaits us, that is, our capability of meeting rapidly-growing scenario-specific demands is severely limited by the cost of acquiring a commensurate amount of training data. This difficult situation is in essence due to limitations of the mainstream learning paradigm: we need to train a new model for each new scenario, based on a large quantity of well-annotated data and commonly from scratch. In tackling this fundamental problem, we move beyond and develop a new learning paradigm named INTERN. By learning with supervisory signals from multiple sources in multiple stages, the model being trained will develop strong generalizability. We evaluate our model on 26 well-known datasets that cover four categories of tasks in computer vision. In most cases, our models, adapted with only 10% of the training data in the target domain, outperform the counterparts trained with the full set of data, often by a significant margin. This is an important step towards a promising prospect where such a model with general vision capability can dramatically reduce our reliance on data, thus expediting the adoption of AI technologies. Furthermore, revolving around our new paradigm, we also introduce a new data system, a new architecture, and a new benchmark, which, together, form a general vision ecosystem to support its future development in an open and inclusive manner.