 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Out-of-Distribution Generalization in Transformers via Recursive Latent Space Reasoning
Oct 15, 2025Systematic, compositional generalization beyond the training distribution remains a core challenge in machine learning -- and a critical bottleneck for the emergent reasoning abilities of modern language models. This work investigates out-of-distribution (OOD) generalization in Transformer networks using a GSM8K-style modular arithmetic on computational graphs task as a testbed. We introduce and explore a set of four architectural mechanisms aimed at enhancing OOD generalization: (i) input-adaptive recurrence; (ii) algorithmic supervision; (iii) anchored latent representations via a discrete bottleneck; and (iv) an explicit error-correction mechanism. Collectively, these mechanisms yield an architectural approach for native and scalable latent space reasoning in Transformer networks with robust algorithmic generalization capabilities. We complement these empirical results with a detailed mechanistic interpretability analysis that reveals how these mechanisms give rise to robust OOD generalization abilities.
SGS-3D: High-Fidelity 3D Instance Segmentation via Reliable Semantic Mask Splitting and Growing
Sep 05, 2025Accurate 3D instance segmentation is crucial for high-quality scene understanding in the 3D vision domain. However, 3D instance segmentation based on 2D-to-3D lifting approaches struggle to produce precise instance-level segmentation, due to accumulated errors introduced during the lifting process from ambiguous semantic guidance and insufficient depth constraints. To tackle these challenges, we propose splitting and growing reliable semantic mask for high-fidelity 3D instance segmentation (SGS-3D), a novel "split-then-grow" framework that first purifies and splits ambiguous lifted masks using geometric primitives, and then grows them into complete instances within the scene. Unlike existing approaches that directly rely on raw lifted masks and sacrifice segmentation accuracy, SGS-3D serves as a training-free refinement method that jointly fuses semantic and geometric information, enabling effective cooperation between the two levels of representation. Specifically, for semantic guidance, we introduce a mask filtering strategy that leverages the co-occurrence of 3D geometry primitives to identify and remove ambiguous masks, thereby ensuring more reliable semantic consistency with the 3D object instances. For the geometric refinement, we construct fine-grained object instances by exploiting both spatial continuity and high-level features, particularly in the case of semantic ambiguity between distinct objects. Experimental results on ScanNet200, ScanNet++, and KITTI-360 demonstrate that SGS-3D substantially improves segmentation accuracy and robustness against inaccurate masks from pre-trained models, yielding high-fidelity object instances while maintaining strong generalization across diverse indoor and outdoor environments. Code is available in the supplementary materials.
EGS-SLAM: RGB-D Gaussian Splatting SLAM with Events
Aug 09, 2025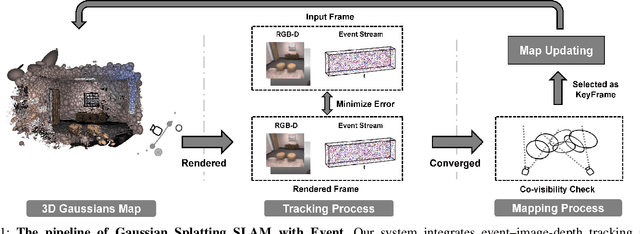
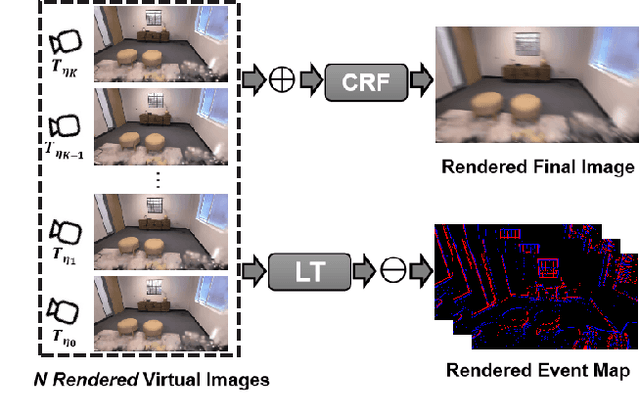


Gaussian Splatting SLAM (GS-SLAM) offers a notable improvement over traditional SLAM methods, enabling photorealistic 3D reconstruction that conventional approaches often struggle to achieve. However, existing GS-SLAM systems perform poorly under persistent and severe motion blur commonly encountered in real-world scenarios, leading to significantly degraded tracking accuracy and compromised 3D reconstruction quality. To address this limitation, we propose EGS-SLAM, a novel GS-SLAM framework that fuses event data with RGB-D inputs to simultaneously reduce motion blur in images and compensate for the sparse and discrete nature of event streams, enabling robust tracking and high-fidelity 3D Gaussian Splatting reconstruction. Specifically, our system explicitly models the camera's continuous trajectory during exposure, supporting event- and blur-aware tracking and mapping on a unified 3D Gaussian Splatting scene. Furthermore, we introduce a learnable camera response function to align the dynamic ranges of events and images, along with a no-event loss to suppress ringing artifacts during reconstruction. We validate our approach on a new dataset comprising synthetic and real-world sequences with significant motion blur. Extensive experimental results demonstrate that EGS-SLAM consistently outperforms existing GS-SLAM systems in both trajectory accuracy and photorealistic 3D Gaussian Splatting reconstruction. The source code will be available at https://github.com/Chensiyu00/EGS-SLAM.
ICM-Fusion: In-Context Meta-Optimized LoRA Fusion for Multi-Task Adaptation
Aug 06, 2025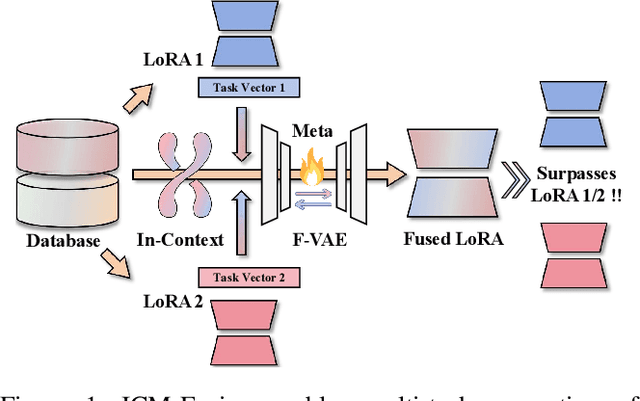
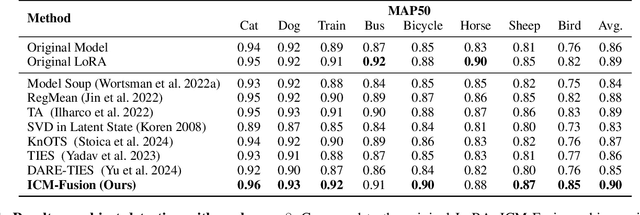
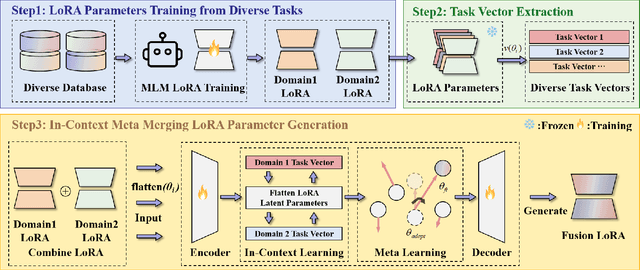
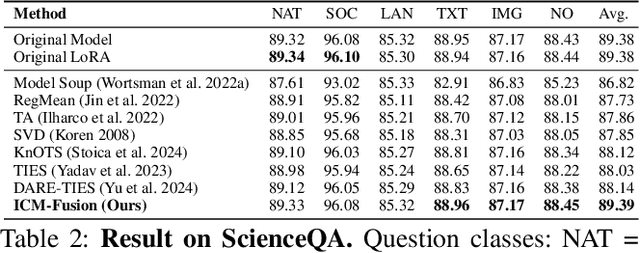
Enabling multi-task adaptation in pre-trained Low-Rank Adaptation (LoRA) models is crucial for enhancing their generalization capabilities. Most existing pre-trained LoRA fusion methods decompose weight matrices, sharing similar parameters while merging divergent ones. However, this paradigm inevitably induces inter-weight conflicts and leads to catastrophic domain forgetting. While incremental learning enables adaptation to multiple tasks, it struggles to achieve generalization in few-shot scenarios. Consequently, when the weight data follows a long-tailed distribution, it can lead to forgetting in the fused weights. To address this issue, we propose In-Context Meta LoRA Fusion (ICM-Fusion), a novel framework that synergizes meta-learning with in-context adaptation. The key innovation lies in our task vector arithmetic, which dynamically balances conflicting optimization directions across domains through learned manifold projections. ICM-Fusion obtains the optimal task vector orientation for the fused model in the latent space by adjusting the orientation of the task vectors. Subsequently, the fused LoRA is reconstructed by a self-designed Fusion VAE (F-VAE) to realize multi-task LoRA generation. We have conducted extensive experiments on visual and linguistic tasks, and the experimental results demonstrate that ICM-Fusion can be adapted to a wide range of architectural models and applied to various tasks. Compared to the current pre-trained LoRA fusion method, ICM-Fusion fused LoRA can significantly reduce the multi-tasking loss and can even achieve task enhancement in few-shot scenarios.
Step-Audio 2 Technical Report
Jul 24, 2025



This paper presents Step-Audio 2, an end-to-end multi-modal large language model designed for industry-strength audio understanding and speech conversation. By integrating a latent audio encoder and reasoning-centric reinforcement learning (RL), Step-Audio 2 achieves promising performance in automatic speech recognition (ASR) and audio understanding. To facilitate genuine end-to-end speech conversation, Step-Audio 2 incorporates the generation of discrete audio tokens into language modeling, significantly enhancing its responsiveness to paralinguistic information such as speaking styles and emotions. To effectively leverage the rich textual and acoustic knowledge in real-world data, Step-Audio 2 integrates retrieval-augmented generation (RAG) and is able to call external tools such as web search to mitigate hallucination and audio search to switch timbres. Trained on millions of hours of speech and audio data, Step-Audio 2 delivers intelligence and expressiveness across diverse conversational scenarios. Evaluation results demonstrate that Step-Audio 2 achieves state-of-the-art performance on various audio understanding and conversational benchmarks compared to other open-source and commercial solutions. Please visit https://github.com/stepfun-ai/Step-Audio2 for more information.
A Neural Representation Framework with LLM-Driven Spatial Reasoning for Open-Vocabulary 3D Visual Grounding
Jul 09, 2025



Open-vocabulary 3D visual grounding aims to localize target objects based on free-form language queries, which is crucial for embodied AI applications such as autonomous navigation, robotics, and augmented reality. Learning 3D language fields through neural representations enables accurate understanding of 3D scenes from limited viewpoints and facilitates the localization of target objects in complex environments. However, existing language field methods struggle to accurately localize instances using spatial relations in language queries, such as ``the book on the chair.'' This limitation mainly arises from inadequate reasoning about spatial relations in both language queries and 3D scenes. In this work, we propose SpatialReasoner, a novel neural representation-based framework with large language model (LLM)-driven spatial reasoning that constructs a visual properties-enhanced hierarchical feature field for open-vocabulary 3D visual grounding. To enable spatial reasoning in language queries, SpatialReasoner fine-tunes an LLM to capture spatial relations and explicitly infer instructions for the target, anchor, and spatial relation. To enable spatial reasoning in 3D scenes, SpatialReasoner incorporates visual properties (opacity and color) to construct a hierarchical feature field. This field represents language and instance features using distilled CLIP features and masks extracted via the Segment Anything Model (SAM). The field is then queried using the inferred instructions in a hierarchical manner to localize the target 3D instance based on the spatial relation in the language query. Extensive experiments show that our framework can be seamlessly integrated into different neural representations, outperforming baseline models in 3D visual grounding while empowering their spatial reasoning capability.
Leveraging Depth and Language for Open-Vocabulary Domain-Generalized Semantic Segmentation
Jun 11, 2025Open-Vocabulary semantic segmentation (OVSS) and domain generalization in semantic segmentation (DGSS) highlight a subtle complementarity that motivates Open-Vocabulary Domain-Generalized Semantic Segmentation (OV-DGSS). OV-DGSS aims to generate pixel-level masks for unseen categories while maintaining robustness across unseen domains, a critical capability for real-world scenarios such as autonomous driving in adverse conditions. We introduce Vireo, a novel single-stage framework for OV-DGSS that unifies the strengths of OVSS and DGSS for the first time. Vireo builds upon the frozen Visual Foundation Models (VFMs) and incorporates scene geometry via Depth VFMs to extract domain-invariant structural features. To bridge the gap between visual and textual modalities under domain shift, we propose three key components: (1) GeoText Prompts, which align geometric features with language cues and progressively refine VFM encoder representations; (2) Coarse Mask Prior Embedding (CMPE) for enhancing gradient flow for faster convergence and stronger textual influence; and (3) the Domain-Open-Vocabulary Vector Embedding Head (DOV-VEH), which fuses refined structural and semantic features for robust prediction. Comprehensive evaluation on these components demonstrates the effectiveness of our designs. Our proposed Vireo achieves the state-of-the-art performance and surpasses existing methods by a large margin in both domain generalization and open-vocabulary recognition, offering a unified and scalable solution for robust visual understanding in diverse and dynamic environments. Code is available at https://github.com/anonymouse-9c53tp182bvz/Vireo.
Quantile-Optimal Policy Learning under Unmeasured Confounding
Jun 08, 2025We study quantile-optimal policy learning where the goal is to find a policy whose reward distribution has the largest $\alpha$-quantile for some $\alpha \in (0, 1)$. We focus on the offline setting whose generating process involves unobserved confounders. Such a problem suffers from three main challenges: (i) nonlinearity of the quantile objective as a functional of the reward distribution, (ii) unobserved confounding issue, and (iii) insufficient coverage of the offline dataset. To address these challenges, we propose a suite of causal-assisted policy learning methods that provably enjoy strong theoretical guarantees under mild conditions. In particular, to address (i) and (ii), using causal inference tools such as instrumental variables and negative controls, we propose to estimate the quantile objectives by solving nonlinear functional integral equations. Then we adopt a minimax estimation approach with nonparametric models to solve these integral equations, and propose to construct conservative policy estimates that address (iii). The final policy is the one that maximizes these pessimistic estimates. In addition, we propose a novel regularized policy learning method that is more amenable to computation. Finally, we prove that the policies learned by these methods are $\tilde{\mathscr{O}}(n^{-1/2})$ quantile-optimal under a mild coverage assumption on the offline dataset. Here, $\tilde{\mathscr{O}}(\cdot)$ omits poly-logarithmic factors. To the best of our knowledge, we propose the first sample-efficient policy learning algorithms for estimating the quantile-optimal policy when there exist unmeasured confounding.
An Optimized Franz-Parisi Criterion and its Equivalence with SQ Lower Bounds
Jun 06, 2025Bandeira et al. (2022) introduced the Franz-Parisi (FP) criterion for characterizing the computational hard phases in statistical detection problems. The FP criterion, based on an annealed version of the celebrated Franz-Parisi potential from statistical physics, was shown to be equivalent to low-degree polynomial (LDP) lower bounds for Gaussian additive models, thereby connecting two distinct approaches to understanding the computational hardness in statistical inference. In this paper, we propose a refined FP criterion that aims to better capture the geometric ``overlap" structure of statistical models. Our main result establishes that this optimized FP criterion is equivalent to Statistical Query (SQ) lower bounds -- another foundational framework in computational complexity of statistical inference. Crucially, this equivalence holds under a mild, verifiable assumption satisfied by a broad class of statistical models, including Gaussian additive models, planted sparse models, as well as non-Gaussian component analysis (NGCA), single-index (SI) models, and convex truncation detection settings. For instance, in the case of convex truncation tasks, the assumption is equivalent with the Gaussian correlation inequality (Royen, 2014) from convex geometry. In addition to the above, our equivalence not only unifies and simplifies the derivation of several known SQ lower bounds -- such as for the NGCA model (Diakonikolas et al., 2017) and the SI model (Damian et al., 2024) -- but also yields new SQ lower bounds of independent interest, including for the computational gaps in mixed sparse linear regression (Arpino et al., 2023) and convex truncation (De et al., 2023).
Depth Anything with Any Prior
May 15, 2025This work presents Prior Depth Anything, a framework that combines incomplete but precise metric information in depth measurement with relative but complete geometric structures in depth prediction, generating accurate, dense, and detailed metric depth maps for any scene. To this end, we design a coarse-to-fine pipeline to progressively integrate the two complementary depth sources. First, we introduce pixel-level metric alignment and distance-aware weighting to pre-fill diverse metric priors by explicitly using depth prediction. It effectively narrows the domain gap between prior patterns, enhancing generalization across varying scenarios. Second, we develop a conditioned monocular depth estimation (MDE) model to refine the inherent noise of depth priors. By conditioning on the normalized pre-filled prior and prediction, the model further implicitly merges the two complementary depth sources. Our model showcases impressive zero-shot generalization across depth completion, super-resolution, and inpainting over 7 real-world datasets, matching or even surpassing previous task-specific methods. More importantly, it performs well on challenging, unseen mixed priors and enables test-time improvements by switching prediction models, providing a flexible accuracy-efficiency trade-off while evolving with advancements in MDE models.