 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Singular Spectrum for Large Language Model Compression
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable capabilities, yet prohibitive parameter complexity often hinders their deployment. Existing singular value decomposition (SVD) based compression methods simply deem singular values as importance scores of decomposed components. However, this importance ordered by singular values does not necessarily correlate with the performance of a downstream task. In this work, we introduce SoCo (Singular spectrum optimization for large language model Compression), a novel compression framework that learns to rescale the decomposed components of SVD in a data-driven manner. Concretely, we employ a learnable diagonal matrix to assign importance scores for singular spectrum and develop a three-stage training process that progressively refines these scores from initial coarse compression to fine-grained sparsification-thereby striking an effective balance between aggressive model compression and performance preservation. Thanks to the learnable singular spectrum, SoCo adaptively prunes components according to the sparsified importance scores, rather than relying on the fixed order of singular values. More importantly, the remaining components with amplified importance scores can compensate for the loss of the pruned ones. Experimental evaluations across multiple LLMs and benchmarks demonstrate that SoCo surpasses the state-of-the-art methods in model compression.
HiMix: Reducing Computational Complexity in Large Vision-Language Models
Jan 17, 2025Benefiting from recent advancements in large language models and modality alignment techniques, existing Large Vision-Language Models(LVLMs) have achieved prominent performance across a wide range of scenarios. However, the excessive computational complexity limits the widespread use of these models in practical applications. We argue that one main bottleneck in computational complexity is caused by the involvement of redundant vision sequences in model computation. This is inspired by a reassessment of the efficiency of vision and language information transmission in the language decoder of LVLMs. Then, we propose a novel hierarchical vision-language interaction mechanism called Hierarchical Vision injection for Mixture Attention (HiMix). In HiMix, only the language sequence undergoes full forward propagation, while the vision sequence interacts with the language at specific stages within each language decoder layer. It is striking that our approach significantly reduces computational complexity with minimal performance loss. Specifically, HiMix achieves a 10x reduction in the computational cost of the language decoder across multiple LVLM models while maintaining comparable performance. This highlights the advantages of our method, and we hope our research brings new perspectives to the field of vision-language understanding. Project Page: https://xuange923.github.io/HiMix
Manga Generation via Layout-controllable Diffusion
Dec 26, 2024



Generating comics through text is widely studied. However, there are few studies on generating multi-panel Manga (Japanese comics) solely based on plain text. Japanese manga contains multiple panels on a single page, with characteristics such as coherence in storytelling, reasonable and diverse page layouts, consistency in characters, and semantic correspondence between panel drawings and panel scripts. Therefore, generating manga poses a significant challenge. This paper presents the manga generation task and constructs the Manga109Story dataset for studying manga generation solely from plain text. Additionally, we propose MangaDiffusion to facilitate the intra-panel and inter-panel information interaction during the manga generation process. The results show that our method particularly ensures the number of panels, reasonable and diverse page layouts. Based on our approach, there is potential to converting a large amount of textual stories into more engaging manga readings, leading to significant application prospects.
LinVT: Empower Your Image-level Large Language Model to Understand Videos
Dec 06, 2024Large Language Models (LLMs) have been widely used in various tasks, motivating us to develop an LLM-based assistant for videos. Instead of training from scratch, we propose a module to transform arbitrary well-trained image-based LLMs into video-LLMs (after being trained on video data). To better adapt image-LLMs for processing videos, we introduce two design principles: linear transformation to preserve the original visual-language alignment and representative information condensation from redundant video content. Guided by these principles, we propose a plug-and-play Linear Video Tokenizer(LinVT), which enables existing image-LLMs to understand videos. We benchmark LinVT with six recent visual LLMs: Aquila, Blip-3, InternVL2, Mipha, Molmo and Qwen2-VL, showcasing the high compatibility of LinVT. LinVT-based LLMs achieve state-of-the-art performance across various video benchmarks, illustrating the effectiveness of LinVT in multi-modal video understanding.
TASR: Timestep-Aware Diffusion Model for Image Super-Resolution
Dec 04, 2024Diffusion models have recently achieved outstanding results in the field of image super-resolution. These methods typically inject low-resolution (LR) images via ControlNet.In this paper, we first explore the temporal dynamics of information infusion through ControlNet, revealing that the input from LR images predominantly influences the initial stages of the denoising process. Leveraging this insight, we introduce a novel timestep-aware diffusion model that adaptively integrates features from both ControlNet and the pre-trained Stable Diffusion (SD). Our method enhances the transmission of LR information in the early stages of diffusion to guarantee image fidelity and stimulates the generation ability of the SD model itself more in the later stages to enhance the detail of generated images. To train this method, we propose a timestep-aware training strategy that adopts distinct losses at varying timesteps and acts on disparate modules. Experiments on benchmark datasets demonstrate the effectiveness of our method. Code: https://github.com/SleepyLin/TASR
RFSR: Improving ISR Diffusion Models via Reward Feedback Learning
Dec 04, 2024Generative diffusion models (DM) have been extensively utilized in image super-resolution (ISR). Most of the existing methods adopt the denoising loss from DDPMs for model optimization. We posit that introducing reward feedback learning to finetune the existing models can further improve the quality of the generated images. In this paper, we propose a timestep-aware training strategy with reward feedback learning. Specifically, in the initial denoising stages of ISR diffusion, we apply low-frequency constraints to super-resolution (SR) images to maintain structural stability. In the later denoising stages, we use reward feedback learning to improve the perceptual and aesthetic quality of the SR images. In addition, we incorporate Gram-KL regularization to alleviate stylization caused by reward hacking. Our method can be integrated into any diffusion-based ISR model in a plug-and-play manner. Experiments show that ISR diffusion models, when fine-tuned with our method, significantly improve the perceptual and aesthetic quality of SR images, achieving excellent subjective results. Code: https://github.com/sxpro/RFSR
Zero-Shot Semantic Segmentation with Decoupled One-Pass Network
Apr 03, 2023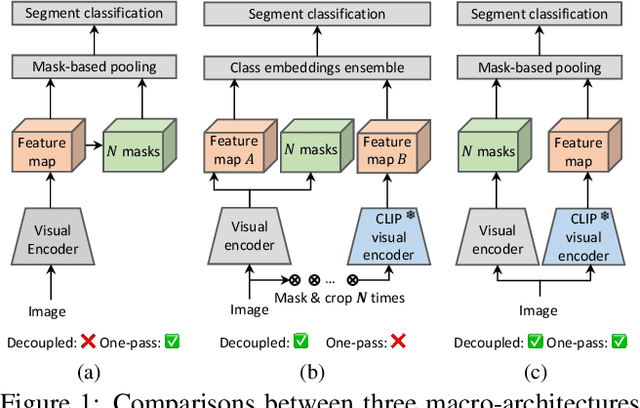
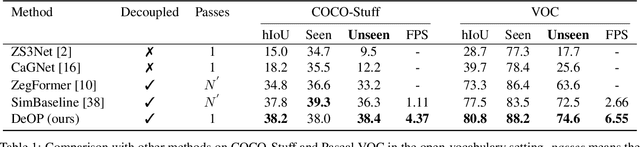


Recently, the zero-shot semantic segmentation problem has attracted increasing attention, and the best performing methods are based on two-stream networks: one stream for proposal mask generation and the other for segment classification using a pre-trained visual-language model. However, existing two-stream methods require passing a great number of (up to a hundred) image crops into the visuallanguage model, which is highly inefficient. To address the problem, we propose a network that only needs a single pass through the visual-language model for each input image. Specifically, we first propose a novel network adaptation approach, termed patch severance, to restrict the harmful interference between the patch embeddings in the pre-trained visual encoder. We then propose classification anchor learning to encourage the network to spatially focus on more discriminative features for classification. Extensive experiments demonstrate that the proposed method achieves outstanding performance, surpassing state-of-theart methods while being 4 to 7 times faster at inference. We release our code at https://github.com/CongHan0808/DeOP.git.
DiP: Learning Discriminative Implicit Parts for Person Re-Identification
Dec 24, 2022



In person re-identification (ReID) tasks, many works explore the learning of part features to improve the performance over global image features. Existing methods extract part features in an explicit manner, by either using a hand-designed image division or keypoints obtained with external visual systems. In this work, we propose to learn Discriminative implicit Parts (DiPs) which are decoupled from explicit body parts. Therefore, DiPs can learn to extract any discriminative features that can benefit in distinguishing identities, which is beyond predefined body parts (such as accessories). Moreover, we propose a novel implicit position to give a geometric interpretation for each DiP. The implicit position can also serve as a learning signal to encourage DiPs to be more position-equivariant with the identity in the image. Lastly, a set of attributes and auxiliary losses are introduced to further improve the learning of DiPs. Extensive experiments show that the proposed method achieves state-of-the-art performance on multiple person ReID benchmarks.
SoccerNet 2022 Challenges Results
Oct 05, 2022



The SoccerNet 2022 challenges were the second annual video understanding challenges organized by the SoccerNet team. In 2022, the challenges were composed of 6 vision-based tasks: (1) action spotting, focusing on retrieving action timestamps in long untrimmed videos, (2) replay grounding, focusing on retrieving the live moment of an action shown in a replay, (3) pitch localization, focusing on detecting line and goal part elements, (4) camera calibration, dedicated to retrieving the intrinsic and extrinsic camera parameters, (5) player re-identification, focusing on retrieving the same players across multiple views, and (6) multiple object tracking, focusing on tracking players and the ball through unedited video streams. Compared to last year's challenges, tasks (1-2) had their evaluation metrics redefined to consider tighter temporal accuracies, and tasks (3-6) were novel, including their underlying data and annotations. More information on the tasks, challenges and leaderboards are available on https://www.soccer-net.org. Baselines and development kits are available on https://github.com/SoccerNet.
Video Temporal Relationship Mining for Data-Efficient Person Re-identification
Oct 01, 2021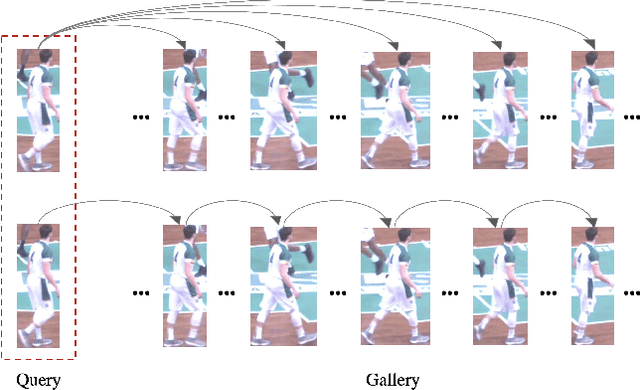
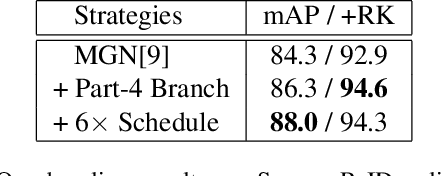
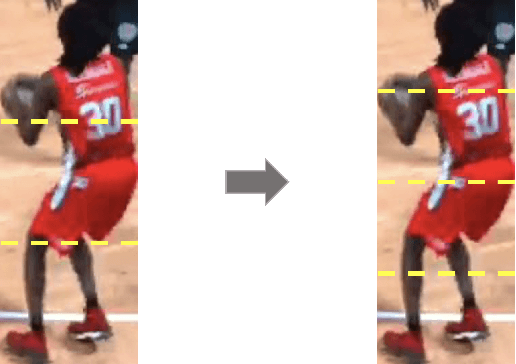
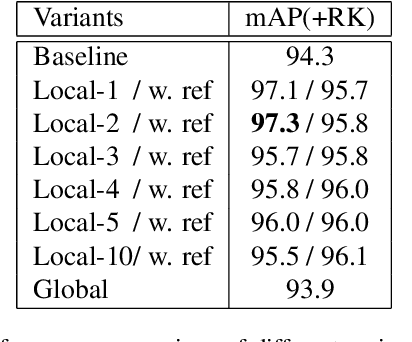
This paper is a technical report to our submission to the ICCV 2021 VIPriors Re-identification Challenge. In order to make full use of the visual inductive priors of the data, we treat the query and gallery images of the same identity as continuous frames in a video sequence. And we propose one novel post-processing strategy for video temporal relationship mining, which not only calculates the distance matrix between query and gallery images, but also the matrix between gallery images. The initial query image is used to retrieve the most similar image from the gallery, then the retrieved image is treated as a new query to retrieve its most similar image from the gallery. By iteratively searching for the closest image, we can achieve accurate image retrieval and finally obtain a robust retrieval sequence.