 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAVMeme Exam: A Multimodal Multilingual Multicultural Benchmark for LLMs' Contextual and Cultural Knowledge and Thinking
Jan 25, 2026Internet audio-visual clips convey meaning through time-varying sound and motion, which extend beyond what text alone can represent. To examine whether AI models can understand such signals in human cultural contexts, we introduce AVMeme Exam, a human-curated benchmark of over one thousand iconic Internet sounds and videos spanning speech, songs, music, and sound effects. Each meme is paired with a unique Q&A assessing levels of understanding from surface content to context and emotion to usage and world knowledge, along with metadata such as original year, transcript, summary, and sensitivity. We systematically evaluate state-of-the-art multimodal large language models (MLLMs) alongside human participants using this benchmark. Our results reveal a consistent limitation: current models perform poorly on textless music and sound effects, and struggle to think in context and in culture compared to surface content. These findings highlight a key gap in human-aligned multimodal intelligence and call for models that can perceive contextually and culturally beyond the surface of what they hear and see. Project page: avmemeexam.github.io/public
UniGlyph: Unified Segmentation-Conditioned Diffusion for Precise Visual Text Synthesis
Jul 02, 2025Text-to-image generation has greatly advanced content creation, yet accurately rendering visual text remains a key challenge due to blurred glyphs, semantic drift, and limited style control. Existing methods often rely on pre-rendered glyph images as conditions, but these struggle to retain original font styles and color cues, necessitating complex multi-branch designs that increase model overhead and reduce flexibility. To address these issues, we propose a segmentation-guided framework that uses pixel-level visual text masks -- rich in glyph shape, color, and spatial detail -- as unified conditional inputs. Our method introduces two core components: (1) a fine-tuned bilingual segmentation model for precise text mask extraction, and (2) a streamlined diffusion model augmented with adaptive glyph conditioning and a region-specific loss to preserve textual fidelity in both content and style. Our approach achieves state-of-the-art performance on the AnyText benchmark, significantly surpassing prior methods in both Chinese and English settings. To enable more rigorous evaluation, we also introduce two new benchmarks: GlyphMM-benchmark for testing layout and glyph consistency in complex typesetting, and MiniText-benchmark for assessing generation quality in small-scale text regions. Experimental results show that our model outperforms existing methods by a large margin in both scenarios, particularly excelling at small text rendering and complex layout preservation, validating its strong generalization and deployment readiness.
StyleTTS-ZS: Efficient High-Quality Zero-Shot Text-to-Speech Synthesis with Distilled Time-Varying Style Diffusion
Sep 16, 2024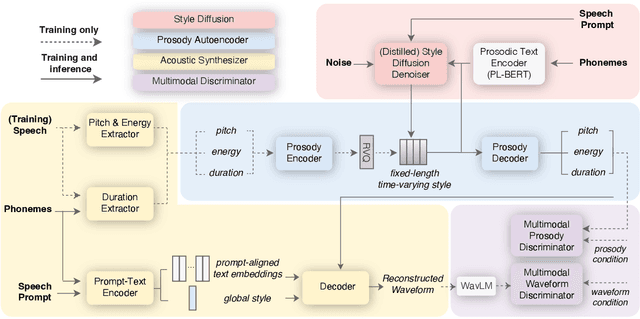
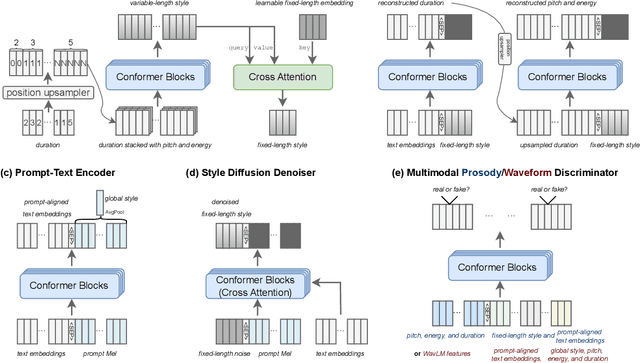


The rapid development of large-scale text-to-speech (TTS) models has led to significant advancements in modeling diverse speaker prosody and voices. However, these models often face issues such as slow inference speeds, reliance on complex pre-trained neural codec representations, and difficulties in achieving naturalness and high similarity to reference speakers. To address these challenges, this work introduces StyleTTS-ZS, an efficient zero-shot TTS model that leverages distilled time-varying style diffusion to capture diverse speaker identities and prosodies. We propose a novel approach that represents human speech using input text and fixed-length time-varying discrete style codes to capture diverse prosodic variations, trained adversarially with multi-modal discriminators. A diffusion model is then built to sample this time-varying style code for efficient latent diffusion. Using classifier-free guidance, StyleTTS-ZS achieves high similarity to the reference speaker in the style diffusion process. Furthermore, to expedite sampling, the style diffusion model is distilled with perceptual loss using only 10k samples, maintaining speech quality and similarity while reducing inference speed by 90%. Our model surpasses previous state-of-the-art large-scale zero-shot TTS models in both naturalness and similarity, offering a 10-20 faster sampling speed, making it an attractive alternative for efficient large-scale zero-shot TTS systems. The audio demo, code and models are available at https://styletts-zs.github.io/.
Speech Slytherin: Examining the Performance and Efficiency of Mamba for Speech Separation, Recognition, and Synthesis
Jul 13, 2024It is too early to conclude that Mamba is a better alternative to transformers for speech before comparing Mamba with transformers in terms of both performance and efficiency in multiple speech-related tasks. To reach this conclusion, we propose and evaluate three models for three tasks: Mamba-TasNet for speech separation, ConMamba for speech recognition, and VALL-M for speech synthesis. We compare them with transformers of similar sizes in performance, memory, and speed. Our Mamba or Mamba-transformer hybrid models show comparable or higher performance than their transformer counterparts: Sepformer, Conformer, and VALL-E. They are more efficient than transformers in memory and speed for speech longer than a threshold duration, inversely related to the resolution of a speech token. Mamba for separation is the most efficient, and Mamba for recognition is the least. Further, we show that Mamba is not more efficient than transformer for speech shorter than the threshold duration and performs worse in models that require joint modeling of text and speech, such as cross or masked attention of two inputs. Therefore, we argue that the superiority of Mamba or transformer depends on particular problems and models. Code available at https://github.com/xi-j/Mamba-TasNet and https://github.com/xi-j/Mamba-ASR.
Dual-path Mamba: Short and Long-term Bidirectional Selective Structured State Space Models for Speech Separation
Mar 27, 2024



Transformers have been the most successful architecture for various speech modeling tasks, including speech separation. However, the self-attention mechanism in transformers with quadratic complexity is inefficient in computation and memory. Recent models incorporate new layers and modules along with transformers for better performance but also introduce extra model complexity. In this work, we replace transformers with Mamba, a selective state space model, for speech separation. We propose dual-path Mamba, which models short-term and long-term forward and backward dependency of speech signals using selective state spaces. Our experimental results on the WSJ0-2mix data show that our dual-path Mamba models match or outperform dual-path transformer models Sepformer with only 60% of its parameters, and the QDPN with only 30% of its parameters. Our large model also reaches a new state-of-the-art SI-SNRi of 24.4 dB.
Listen, Chat, and Edit: Text-Guided Soundscape Modification for Enhanced Auditory Experience
Feb 06, 2024



In daily life, we encounter a variety of sounds, both desirable and undesirable, with limited control over their presence and volume. Our work introduces "Listen, Chat, and Edit" (LCE), a novel multimodal sound mixture editor that modifies each sound source in a mixture based on user-provided text instructions. LCE distinguishes itself with a user-friendly chat interface and its unique ability to edit multiple sound sources simultaneously within a mixture, without needing to separate them. Users input open-vocabulary text prompts, which are interpreted by a large language model to create a semantic filter for editing the sound mixture. The system then decomposes the mixture into its components, applies the semantic filter, and reassembles it into the desired output. We developed a 160-hour dataset with over 100k mixtures, including speech and various audio sources, along with text prompts for diverse editing tasks like extraction, removal, and volume control. Our experiments demonstrate significant improvements in signal quality across all editing tasks and robust performance in zero-shot scenarios with varying numbers and types of sound sources.
Exploring Self-Supervised Contrastive Learning of Spatial Sound Event Representation
Sep 27, 2023


In this study, we present a simple multi-channel framework for contrastive learning (MC-SimCLR) to encode 'what' and 'where' of spatial audios. MC-SimCLR learns joint spectral and spatial representations from unlabeled spatial audios, thereby enhancing both event classification and sound localization in downstream tasks. At its core, we propose a multi-level data augmentation pipeline that augments different levels of audio features, including waveforms, Mel spectrograms, and generalized cross-correlation (GCC) features. In addition, we introduce simple yet effective channel-wise augmentation methods to randomly swap the order of the microphones and mask Mel and GCC channels. By using these augmentations, we find that linear layers on top of the learned representation significantly outperform supervised models in terms of both event classification accuracy and localization error. We also perform a comprehensive analysis of the effect of each augmentation method and a comparison of the fine-tuning performance using different amounts of labeled data.
HiFTNet: A Fast High-Quality Neural Vocoder with Harmonic-plus-Noise Filter and Inverse Short Time Fourier Transform
Sep 18, 2023


Recent advancements in speech synthesis have leveraged GAN-based networks like HiFi-GAN and BigVGAN to produce high-fidelity waveforms from mel-spectrograms. However, these networks are computationally expensive and parameter-heavy. iSTFTNet addresses these limitations by integrating inverse short-time Fourier transform (iSTFT) into the network, achieving both speed and parameter efficiency. In this paper, we introduce an extension to iSTFTNet, termed HiFTNet, which incorporates a harmonic-plus-noise source filter in the time-frequency domain that uses a sinusoidal source from the fundamental frequency (F0) inferred via a pre-trained F0 estimation network for fast inference speed. Subjective evaluations on LJSpeech show that our model significantly outperforms both iSTFTNet and HiFi-GAN, achieving ground-truth-level performance. HiFTNet also outperforms BigVGAN-base on LibriTTS for unseen speakers and achieves comparable performance to BigVGAN while being four times faster with only $1/6$ of the parameters. Our work sets a new benchmark for efficient, high-quality neural vocoding, paving the way for real-time applications that demand high quality speech synthesis.
SLMGAN: Exploiting Speech Language Model Representations for Unsupervised Zero-Shot Voice Conversion in GANs
Jul 18, 2023



In recent years, large-scale pre-trained speech language models (SLMs) have demonstrated remarkable advancements in various generative speech modeling applications, such as text-to-speech synthesis, voice conversion, and speech enhancement. These applications typically involve mapping text or speech inputs to pre-trained SLM representations, from which target speech is decoded. This paper introduces a new approach, SLMGAN, to leverage SLM representations for discriminative tasks within the generative adversarial network (GAN) framework, specifically for voice conversion. Building upon StarGANv2-VC, we add our novel SLM-based WavLM discriminators on top of the mel-based discriminators along with our newly designed SLM feature matching loss function, resulting in an unsupervised zero-shot voice conversion system that does not require text labels during training. Subjective evaluation results show that SLMGAN outperforms existing state-of-the-art zero-shot voice conversion models in terms of naturalness and achieves comparable similarity, highlighting the potential of SLM-based discriminators for related applications.
StyleTTS 2: Towards Human-Level Text-to-Speech through Style Diffusion and Adversarial Training with Large Speech Language Models
Jun 13, 2023



In this paper, we present StyleTTS 2, a text-to-speech (TTS) model that leverages style diffusion and adversarial training with large speech language models (SLMs) to achieve human-level TTS synthesis. StyleTTS 2 differs from its predecessor by modeling styles as a latent random variable through diffusion models to generate the most suitable style for the text without requiring reference speech, achieving efficient latent diffusion while benefiting from the diverse speech synthesis offered by diffusion models. Furthermore, we employ large pre-trained SLMs, such as WavLM, as discriminators with our novel differentiable duration modeling for end-to-end training, resulting in improved speech naturalness. StyleTTS 2 surpasses human recordings on the single-speaker LJSpeech dataset and matches it on the multispeaker VCTK dataset as judged by native English speakers. Moreover, when trained on the LibriTTS dataset, our model outperforms previous publicly available models for zero-shot speaker adaptation. This work achieves the first human-level TTS on both single and multispeaker datasets, showcasing the potential of style diffusion and adversarial training with large SLMs. The audio demos and source code are available at https://styletts2.github.io/.