 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStyleTTS-ZS: Efficient High-Quality Zero-Shot Text-to-Speech Synthesis with Distilled Time-Varying Style Diffusion
Paper and Code
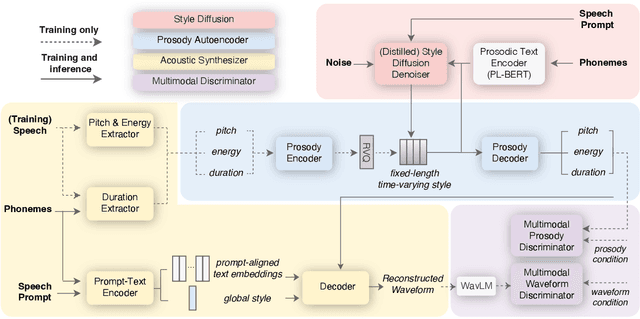
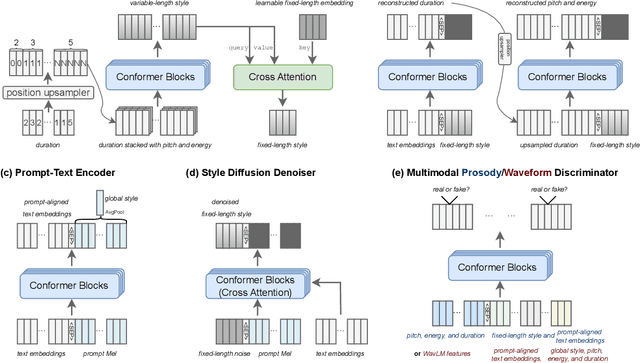


The rapid development of large-scale text-to-speech (TTS) models has led to significant advancements in modeling diverse speaker prosody and voices. However, these models often face issues such as slow inference speeds, reliance on complex pre-trained neural codec representations, and difficulties in achieving naturalness and high similarity to reference speakers. To address these challenges, this work introduces StyleTTS-ZS, an efficient zero-shot TTS model that leverages distilled time-varying style diffusion to capture diverse speaker identities and prosodies. We propose a novel approach that represents human speech using input text and fixed-length time-varying discrete style codes to capture diverse prosodic variations, trained adversarially with multi-modal discriminators. A diffusion model is then built to sample this time-varying style code for efficient latent diffusion. Using classifier-free guidance, StyleTTS-ZS achieves high similarity to the reference speaker in the style diffusion process. Furthermore, to expedite sampling, the style diffusion model is distilled with perceptual loss using only 10k samples, maintaining speech quality and similarity while reducing inference speed by 90%. Our model surpasses previous state-of-the-art large-scale zero-shot TTS models in both naturalness and similarity, offering a 10-20 faster sampling speed, making it an attractive alternative for efficient large-scale zero-shot TTS systems. The audio demo, code and models are available at https://styletts-zs.github.io/.