 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniGlyph: Unified Segmentation-Conditioned Diffusion for Precise Visual Text Synthesis
Jul 02, 2025Text-to-image generation has greatly advanced content creation, yet accurately rendering visual text remains a key challenge due to blurred glyphs, semantic drift, and limited style control. Existing methods often rely on pre-rendered glyph images as conditions, but these struggle to retain original font styles and color cues, necessitating complex multi-branch designs that increase model overhead and reduce flexibility. To address these issues, we propose a segmentation-guided framework that uses pixel-level visual text masks -- rich in glyph shape, color, and spatial detail -- as unified conditional inputs. Our method introduces two core components: (1) a fine-tuned bilingual segmentation model for precise text mask extraction, and (2) a streamlined diffusion model augmented with adaptive glyph conditioning and a region-specific loss to preserve textual fidelity in both content and style. Our approach achieves state-of-the-art performance on the AnyText benchmark, significantly surpassing prior methods in both Chinese and English settings. To enable more rigorous evaluation, we also introduce two new benchmarks: GlyphMM-benchmark for testing layout and glyph consistency in complex typesetting, and MiniText-benchmark for assessing generation quality in small-scale text regions. Experimental results show that our model outperforms existing methods by a large margin in both scenarios, particularly excelling at small text rendering and complex layout preservation, validating its strong generalization and deployment readiness.
KGExplainer: Towards Exploring Connected Subgraph Explanations for Knowledge Graph Completion
Apr 05, 2024


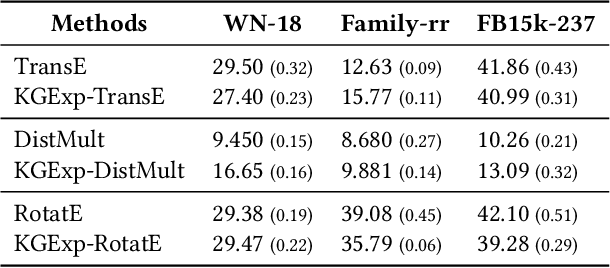
Knowledge graph completion (KGC) aims to alleviate the inherent incompleteness of knowledge graphs (KGs), which is a critical task for various applications, such as recommendations on the web. Although knowledge graph embedding (KGE) models have demonstrated superior predictive performance on KGC tasks, these models infer missing links in a black-box manner that lacks transparency and accountability, preventing researchers from developing accountable models. Existing KGE-based explanation methods focus on exploring key paths or isolated edges as explanations, which is information-less to reason target prediction. Additionally, the missing ground truth leads to these explanation methods being ineffective in quantitatively evaluating explored explanations. To overcome these limitations, we propose KGExplainer, a model-agnostic method that identifies connected subgraph explanations and distills an evaluator to assess them quantitatively. KGExplainer employs a perturbation-based greedy search algorithm to find key connected subgraphs as explanations within the local structure of target predictions. To evaluate the quality of the explored explanations, KGExplainer distills an evaluator from the target KGE model. By forwarding the explanations to the evaluator, our method can examine the fidelity of them. Extensive experiments on benchmark datasets demonstrate that KGExplainer yields promising improvement and achieves an optimal ratio of 83.3% in human evaluation.
Learning to Denoise Unreliable Interactions for Link Prediction on Biomedical Knowledge Graph
Dec 09, 2023



Link prediction in biomedical knowledge graphs (KGs) aims at predicting unknown interactions between entities, including drug-target interaction (DTI) and drug-drug interaction (DDI), which is critical for drug discovery and therapeutics. Previous methods prefer to utilize the rich semantic relations and topological structure of the KG to predict missing links, yielding promising outcomes. However, all these works only focus on improving the predictive performance without considering the inevitable noise and unreliable interactions existing in the KGs, which limits the development of KG-based computational methods. To address these limitations, we propose a Denoised Link Prediction framework, called DenoisedLP. DenoisedLP obtains reliable interactions based on the local subgraph by denoising noisy links in a learnable way, providing a universal module for mining underlying task-relevant relations. To collaborate with the smoothed semantic information, DenoisedLP introduces the semantic subgraph by blurring conflict relations around the predicted link. By maximizing the mutual information between the reliable structure and smoothed semantic relations, DenoisedLP emphasizes the informative interactions for predicting relation-specific links. Experimental results on real-world datasets demonstrate that DenoisedLP outperforms state-of-the-art methods on DTI and DDI prediction tasks, and verify the effectiveness and robustness of denoising unreliable interactions on the contaminated KGs.
Deep neural network based sparse measurement matrix for image compressed sensing
Jun 19, 2018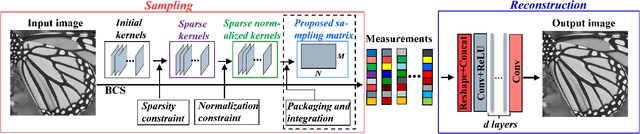
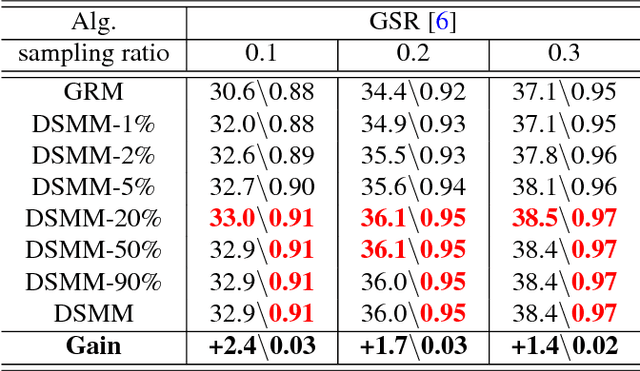

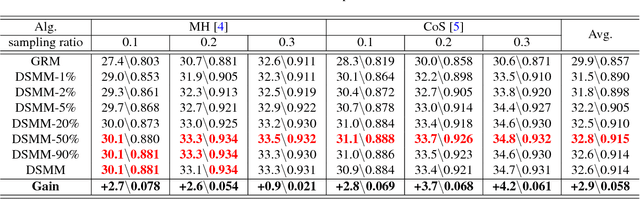
Gaussian random matrix (GRM) has been widely used to generate linear measurements in compressed sensing (CS) of natural images. However, there actually exist two disadvantages with GRM in practice. One is that GRM has large memory requirement and high computational complexity, which restrict the applications of CS. Another is that the CS measurements randomly obtained by GRM cannot provide sufficient reconstruction performances. In this paper, a Deep neural network based Sparse Measurement Matrix (DSMM) is learned by the proposed convolutional network to reduce the sampling computational complexity and improve the CS reconstruction performance. Two sub networks are included in the proposed network, which are the sampling sub-network and the reconstruction sub-network. In the sampling sub-network, the sparsity and the normalization are both considered by the limitation of the storage and the computational complexity. In order to improve the CS reconstruction performance, a reconstruction sub-network are introduced to help enhance the sampling sub-network. So by the offline iterative training of the proposed end-to-end network, the DSMM is generated for accurate measurement and excellent reconstruction. Experimental results demonstrate that the proposed DSMM outperforms GRM greatly on representative CS reconstruction methods
An End-to-End Compression Framework Based on Convolutional Neural Networks
Aug 02, 2017Deep learning, e.g., convolutional neural networks (CNNs), has achieved great success in image processing and computer vision especially in high level vision applications such as recognition and understanding. However, it is rarely used to solve low-level vision problems such as image compression studied in this paper. Here, we move forward a step and propose a novel compression framework based on CNNs. To achieve high-quality image compression at low bit rates, two CNNs are seamlessly integrated into an end-to-end compression framework. The first CNN, named compact convolutional neural network (ComCNN), learns an optimal compact representation from an input image, which preserves the structural information and is then encoded using an image codec (e.g., JPEG, JPEG2000 or BPG). The second CNN, named reconstruction convolutional neural network (RecCNN), is used to reconstruct the decoded image with high-quality in the decoding end. To make two CNNs effectively collaborate, we develop a unified end-to-end learning algorithm to simultaneously learn ComCNN and RecCNN, which facilitates the accurate reconstruction of the decoded image using RecCNN. Such a design also makes the proposed compression framework compatible with existing image coding standards. Experimental results validate that the proposed compression framework greatly outperforms several compression frameworks that use existing image coding standards with state-of-the-art deblocking or denoising post-processing methods.