 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChartE$^{3}$: A Comprehensive Benchmark for End-to-End Chart Editing
Jan 29, 2026Charts are a fundamental visualization format for structured data analysis. Enabling end-to-end chart editing according to user intent is of great practical value, yet remains challenging due to the need for both fine-grained control and global structural consistency. Most existing approaches adopt pipeline-based designs, where natural language or code serves as an intermediate representation, limiting their ability to faithfully execute complex edits. We introduce ChartE$^{3}$, an End-to-End Chart Editing benchmark that directly evaluates models without relying on intermediate natural language programs or code-level supervision. ChartE$^{3}$ focuses on two complementary editing dimensions: local editing, which involves fine-grained appearance changes such as font or color adjustments, and global editing, which requires holistic, data-centric transformations including data filtering and trend line addition. ChartE$^{3}$ contains over 1,200 high-quality samples constructed via a well-designed data pipeline with human curation. Each sample is provided as a triplet of a chart image, its underlying code, and a multimodal editing instruction, enabling evaluation from both objective and subjective perspectives. Extensive benchmarking of state-of-the-art multimodal large language models reveals substantial performance gaps, particularly on global editing tasks, highlighting critical limitations in current end-to-end chart editing capabilities.
RouteMoA: Dynamic Routing without Pre-Inference Boosts Efficient Mixture-of-Agents
Jan 26, 2026Mixture-of-Agents (MoA) improves LLM performance through layered collaboration, but its dense topology raises costs and latency. Existing methods employ LLM judges to filter responses, yet still require all models to perform inference before judging, failing to cut costs effectively. They also lack model selection criteria and struggle with large model pools, where full inference is costly and can exceed context limits. To address this, we propose RouteMoA, an efficient mixture-of-agents framework with dynamic routing. It employs a lightweight scorer to perform initial screening by predicting coarse-grained performance from the query, narrowing candidates to a high-potential subset without inference. A mixture of judges then refines these scores through lightweight self- and cross-assessment based on existing model outputs, providing posterior correction without additional inference. Finally, a model ranking mechanism selects models by balancing performance, cost, and latency. RouteMoA outperforms MoA across varying tasks and model pool sizes, reducing cost by 89.8% and latency by 63.6% in the large-scale model pool.
Object-level Correlation for Few-Shot Segmentation
Sep 09, 2025Few-shot semantic segmentation (FSS) aims to segment objects of novel categories in the query images given only a few annotated support samples. Existing methods primarily build the image-level correlation between the support target object and the entire query image. However, this correlation contains the hard pixel noise, \textit{i.e.}, irrelevant background objects, that is intractable to trace and suppress, leading to the overfitting of the background. To address the limitation of this correlation, we imitate the biological vision process to identify novel objects in the object-level information. Target identification in the general objects is more valid than in the entire image, especially in the low-data regime. Inspired by this, we design an Object-level Correlation Network (OCNet) by establishing the object-level correlation between the support target object and query general objects, which is mainly composed of the General Object Mining Module (GOMM) and Correlation Construction Module (CCM). Specifically, GOMM constructs the query general object feature by learning saliency and high-level similarity cues, where the general objects include the irrelevant background objects and the target foreground object. Then, CCM establishes the object-level correlation by allocating the target prototypes to match the general object feature. The generated object-level correlation can mine the query target feature and suppress the hard pixel noise for the final prediction. Extensive experiments on PASCAL-${5}^{i}$ and COCO-${20}^{i}$ show that our model achieves the state-of-the-art performance.
High-Density EEG Enables the Fastest Visual Brain-Computer Interfaces
Jul 23, 2025Brain-computer interface (BCI) technology establishes a direct communication pathway between the brain and external devices. Current visual BCI systems suffer from insufficient information transfer rates (ITRs) for practical use. Spatial information, a critical component of visual perception, remains underexploited in existing systems because the limited spatial resolution of recording methods hinders the capture of the rich spatiotemporal dynamics of brain signals. This study proposed a frequency-phase-space fusion encoding method, integrated with 256-channel high-density electroencephalogram (EEG) recordings, to develop high-speed BCI systems. In the classical frequency-phase encoding 40-target BCI paradigm, the 256-66, 128-32, and 64-21 electrode configurations brought theoretical ITR increases of 83.66%, 79.99%, and 55.50% over the traditional 64-9 setup. In the proposed frequency-phase-space encoding 200-target BCI paradigm, these increases climbed to 195.56%, 153.08%, and 103.07%. The online BCI system achieved an average actual ITR of 472.7 bpm. This study demonstrates the essential role and immense potential of high-density EEG in decoding the spatiotemporal information of visual stimuli.
Restoring Real-World Images with an Internal Detail Enhancement Diffusion Model
May 24, 2025Restoring real-world degraded images, such as old photographs or low-resolution images, presents a significant challenge due to the complex, mixed degradations they exhibit, such as scratches, color fading, and noise. Recent data-driven approaches have struggled with two main challenges: achieving high-fidelity restoration and providing object-level control over colorization. While diffusion models have shown promise in generating high-quality images with specific controls, they often fail to fully preserve image details during restoration. In this work, we propose an internal detail-preserving diffusion model for high-fidelity restoration of real-world degraded images. Our method utilizes a pre-trained Stable Diffusion model as a generative prior, eliminating the need to train a model from scratch. Central to our approach is the Internal Image Detail Enhancement (IIDE) technique, which directs the diffusion model to preserve essential structural and textural information while mitigating degradation effects. The process starts by mapping the input image into a latent space, where we inject the diffusion denoising process with degradation operations that simulate the effects of various degradation factors. Extensive experiments demonstrate that our method significantly outperforms state-of-the-art models in both qualitative assessments and perceptual quantitative evaluations. Additionally, our approach supports text-guided restoration, enabling object-level colorization control that mimics the expertise of professional photo editing.
RemoteSAM: Towards Segment Anything for Earth Observation
May 23, 2025
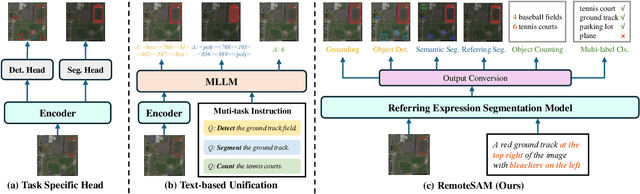
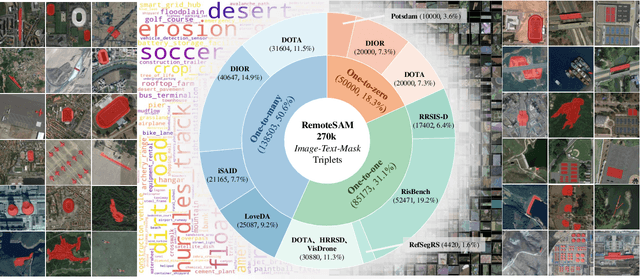
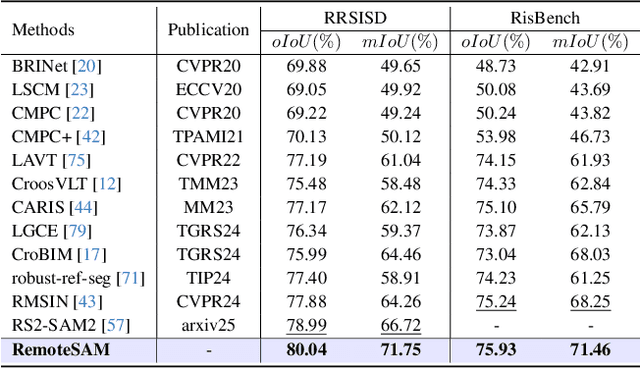
We aim to develop a robust yet flexible visual foundation model for Earth observation. It should possess strong capabilities in recognizing and localizing diverse visual targets while providing compatibility with various input-output interfaces required across different task scenarios. Current systems cannot meet these requirements, as they typically utilize task-specific architecture trained on narrow data domains with limited semantic coverage. Our study addresses these limitations from two aspects: data and modeling. We first introduce an automatic data engine that enjoys significantly better scalability compared to previous human annotation or rule-based approaches. It has enabled us to create the largest dataset of its kind to date, comprising 270K image-text-mask triplets covering an unprecedented range of diverse semantic categories and attribute specifications. Based on this data foundation, we further propose a task unification paradigm that centers around referring expression segmentation. It effectively handles a wide range of vision-centric perception tasks, including classification, detection, segmentation, grounding, etc, using a single model without any task-specific heads. Combining these innovations on data and modeling, we present RemoteSAM, a foundation model that establishes new SoTA on several earth observation perception benchmarks, outperforming other foundation models such as Falcon, GeoChat, and LHRS-Bot with significantly higher efficiency. Models and data are publicly available at https://github.com/1e12Leon/RemoteSAM.
HARDMath2: A Benchmark for Applied Mathematics Built by Students as Part of a Graduate Class
May 17, 2025Large language models (LLMs) have shown remarkable progress in mathematical problem-solving, but evaluation has largely focused on problems that have exact analytical solutions or involve formal proofs, often overlooking approximation-based problems ubiquitous in applied science and engineering. To fill this gap, we build on prior work and present HARDMath2, a dataset of 211 original problems covering the core topics in an introductory graduate applied math class, including boundary-layer analysis, WKB methods, asymptotic solutions of nonlinear partial differential equations, and the asymptotics of oscillatory integrals. This dataset was designed and verified by the students and instructors of a core graduate applied mathematics course at Harvard. We build the dataset through a novel collaborative environment that challenges students to write and refine difficult problems consistent with the class syllabus, peer-validate solutions, test different models, and automatically check LLM-generated solutions against their own answers and numerical ground truths. Evaluation results show that leading frontier models still struggle with many of the problems in the dataset, highlighting a gap in the mathematical reasoning skills of current LLMs. Importantly, students identified strategies to create increasingly difficult problems by interacting with the models and exploiting common failure modes. This back-and-forth with the models not only resulted in a richer and more challenging benchmark but also led to qualitative improvements in the students' understanding of the course material, which is increasingly important as we enter an age where state-of-the-art language models can solve many challenging problems across a wide domain of fields.
MedGUIDE: Benchmarking Clinical Decision-Making in Large Language Models
May 16, 2025



Clinical guidelines, typically structured as decision trees, are central to evidence-based medical practice and critical for ensuring safe and accurate diagnostic decision-making. However, it remains unclear whether Large Language Models (LLMs) can reliably follow such structured protocols. In this work, we introduce MedGUIDE, a new benchmark for evaluating LLMs on their ability to make guideline-consistent clinical decisions. MedGUIDE is constructed from 55 curated NCCN decision trees across 17 cancer types and uses clinical scenarios generated by LLMs to create a large pool of multiple-choice diagnostic questions. We apply a two-stage quality selection process, combining expert-labeled reward models and LLM-as-a-judge ensembles across ten clinical and linguistic criteria, to select 7,747 high-quality samples. We evaluate 25 LLMs spanning general-purpose, open-source, and medically specialized models, and find that even domain-specific LLMs often underperform on tasks requiring structured guideline adherence. We also test whether performance can be improved via in-context guideline inclusion or continued pretraining. Our findings underscore the importance of MedGUIDE in assessing whether LLMs can operate safely within the procedural frameworks expected in real-world clinical settings.
Dome-DETR: DETR with Density-Oriented Feature-Query Manipulation for Efficient Tiny Object Detection
May 09, 2025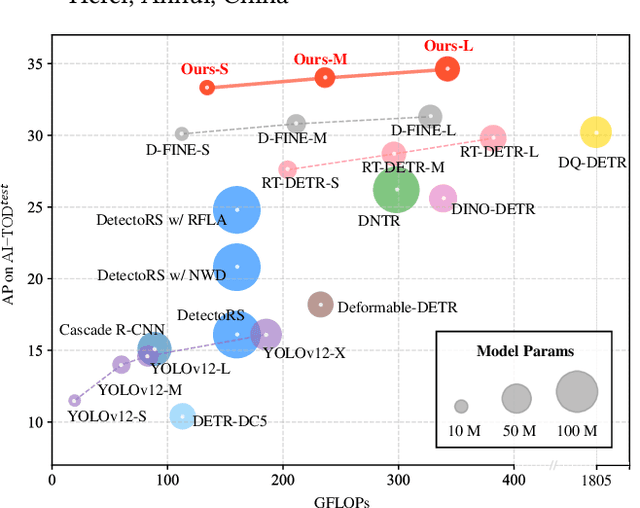
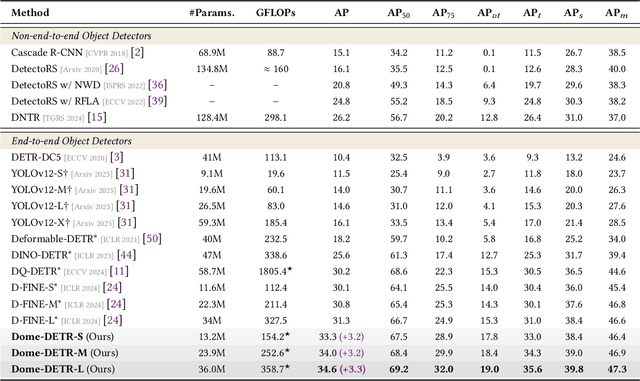
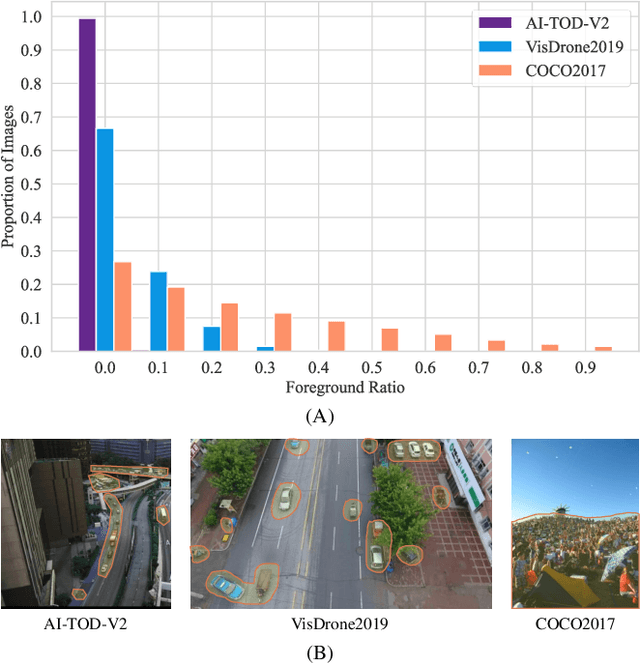
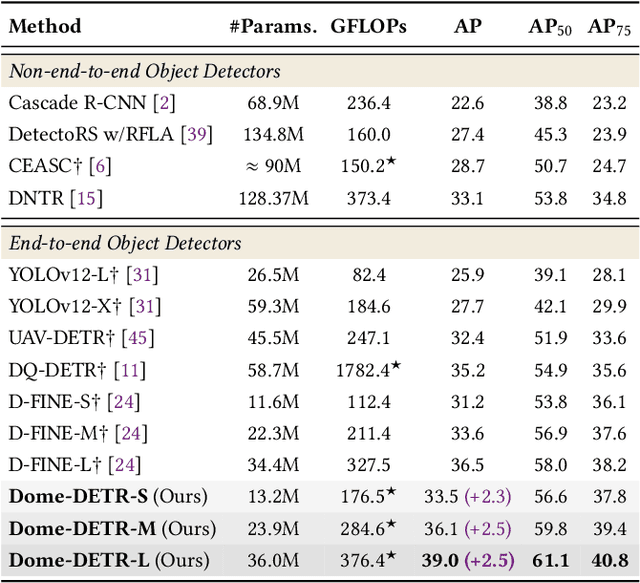
Tiny object detection plays a vital role in drone surveillance, remote sensing, and autonomous systems, enabling the identification of small targets across vast landscapes. However, existing methods suffer from inefficient feature leverage and high computational costs due to redundant feature processing and rigid query allocation. To address these challenges, we propose Dome-DETR, a novel framework with Density-Oriented Feature-Query Manipulation for Efficient Tiny Object Detection. To reduce feature redundancies, we introduce a lightweight Density-Focal Extractor (DeFE) to produce clustered compact foreground masks. Leveraging these masks, we incorporate Masked Window Attention Sparsification (MWAS) to focus computational resources on the most informative regions via sparse attention. Besides, we propose Progressive Adaptive Query Initialization (PAQI), which adaptively modulates query density across spatial areas for better query allocation. Extensive experiments demonstrate that Dome-DETR achieves state-of-the-art performance (+3.3 AP on AI-TOD-V2 and +2.5 AP on VisDrone) while maintaining low computational complexity and a compact model size. Code will be released upon acceptance.
SelaFD:Seamless Adaptation of Vision Transformer Fine-tuning for Radar-based Human Activity
Feb 07, 2025



Human Activity Recognition (HAR) such as fall detection has become increasingly critical due to the aging population, necessitating effective monitoring systems to prevent serious injuries and fatalities associated with falls. This study focuses on fine-tuning the Vision Transformer (ViT) model specifically for HAR using radar-based Time-Doppler signatures. Unlike traditional image datasets, these signals present unique challenges due to their non-visual nature and the high degree of similarity among various activities. Directly fine-tuning the ViT with all parameters proves suboptimal for this application. To address this challenge, we propose a novel approach that employs Low-Rank Adaptation (LoRA) fine-tuning in the weight space to facilitate knowledge transfer from pre-trained ViT models. Additionally, to extract fine-grained features, we enhance feature representation through the integration of a serial-parallel adapter in the feature space. Our innovative joint fine-tuning method, tailored for radar-based Time-Doppler signatures, significantly improves HAR accuracy, surpassing existing state-of-the-art methodologies in this domain. Our code is released at https://github.com/wangyijunlyy/SelaFD.