 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond Attention Magnitude: Leveraging Inter-layer Rank Consistency for Efficient Vision-Language-Action Models
Mar 26, 2026Vision-Language-Action (VLA) models excel in robotic manipulation but suffer from significant inference latency due to processing dense visual tokens. Existing token reduction methods predominantly rely on attention magnitude as a static selection. In this work, we challenge this assumption, revealing that high-attention tokens are task-dependent and can even degrade policy performance. To address this, we introduce \textbf{TIES} (\textbf{T}au-guided \textbf{I}nter-layer \textbf{E}fficient \textbf{S}election), a dynamic framework guided by inter-layer token ranking consistency. By adaptively balancing attention magnitude with ranking consistency, TIES ensures robust token selection without requiring additional training. On the CogACT + SIMPLER benchmark, TIES improves average success rates by 6\% while reducing token usage by 78\%, and demonstrate strong generalization across diverse decoders and benchmarks.
Compression Tells Intelligence: Visual Coding, Visual Token Technology, and the Unification
Jan 28, 2026"Compression Tells Intelligence", is supported by research in artificial intelligence, particularly concerning (multimodal) large language models (LLMs/MLLMs), where compression efficiency often correlates with improved model performance and capabilities. For compression, classical visual coding based on traditional information theory has developed over decades, achieving great success with numerous international industrial standards widely applied in multimedia (e.g., image/video) systems. Except that, the recent emergingvisual token technology of generative multi-modal large models also shares a similar fundamental objective like visual coding: maximizing semantic information fidelity during the representation learning while minimizing computational cost. Therefore, this paper provides a comprehensive overview of two dominant technique families first -- Visual Coding and Vision Token Technology -- then we further unify them from the aspect of optimization, discussing the essence of compression efficiency and model performance trade-off behind. Next, based on the proposed unified formulation bridging visual coding andvisual token technology, we synthesize bidirectional insights of themselves and forecast the next-gen visual codec and token techniques. Last but not least, we experimentally show a large potential of the task-oriented token developments in the more practical tasks like multimodal LLMs (MLLMs), AI-generated content (AIGC), and embodied AI, as well as shedding light on the future possibility of standardizing a general token technology like the traditional codecs (e.g., H.264/265) with high efficiency for a wide range of intelligent tasks in a unified and effective manner.
Speak While Watching: Unleashing TRUE Real-Time Video Understanding Capability of Multimodal Large Language Models
Jan 11, 2026Multimodal Large Language Models (MLLMs) have achieved strong performance across many tasks, yet most systems remain limited to offline inference, requiring complete inputs before generating outputs. Recent streaming methods reduce latency by interleaving perception and generation, but still enforce a sequential perception-generation cycle, limiting real-time interaction. In this work, we target a fundamental bottleneck that arises when extending MLLMs to real-time video understanding: the global positional continuity constraint imposed by standard positional encoding schemes. While natural in offline inference, this constraint tightly couples perception and generation, preventing effective input-output parallelism. To address this limitation, we propose a parallel streaming framework that relaxes positional continuity through three designs: Overlapped, Group-Decoupled, and Gap-Isolated. These designs enable simultaneous perception and generation, allowing the model to process incoming inputs while producing responses in real time. Extensive experiments reveal that Group-Decoupled achieves the best efficiency-performance balance, maintaining high fluency and accuracy while significantly reducing latency. We further show that the proposed framework yields up to 2x acceleration under balanced perception-generation workloads, establishing a principled pathway toward speak-while-watching real-time systems. We make all our code publicly available: https://github.com/EIT-NLP/Speak-While-Watching.
Semantics Disentanglement and Composition for Versatile Codec toward both Human-eye Perception and Machine Vision Task
Dec 24, 2024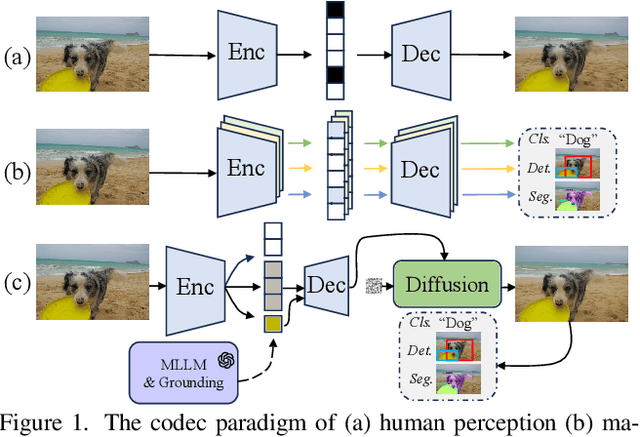



While learned image compression methods have achieved impressive results in either human visual perception or machine vision tasks, they are often specialized only for one domain. This drawback limits their versatility and generalizability across scenarios and also requires retraining to adapt to new applications-a process that adds significant complexity and cost in real-world scenarios. In this study, we introduce an innovative semantics DISentanglement and COmposition VERsatile codec (DISCOVER) to simultaneously enhance human-eye perception and machine vision tasks. The approach derives a set of labels per task through multimodal large models, which grounding models are then applied for precise localization, enabling a comprehensive understanding and disentanglement of image components at the encoder side. At the decoding stage, a comprehensive reconstruction of the image is achieved by leveraging these encoded components alongside priors from generative models, thereby optimizing performance for both human visual perception and machine-based analytical tasks. Extensive experimental evaluations substantiate the robustness and effectiveness of DISCOVER, demonstrating superior performance in fulfilling the dual objectives of human and machine vision requirements.
Tell Codec What Worth Compressing: Semantically Disentangled Image Coding for Machine with LMMs
Aug 16, 2024



We present a new image compression paradigm to achieve ``intelligently coding for machine'' by cleverly leveraging the common sense of Large Multimodal Models (LMMs). We are motivated by the evidence that large language/multimodal models are powerful general-purpose semantics predictors for understanding the real world. Different from traditional image compression typically optimized for human eyes, the image coding for machines (ICM) framework we focus on requires the compressed bitstream to more comply with different downstream intelligent analysis tasks. To this end, we employ LMM to \textcolor{red}{tell codec what to compress}: 1) first utilize the powerful semantic understanding capability of LMMs w.r.t object grounding, identification, and importance ranking via prompts, to disentangle image content before compression, 2) and then based on these semantic priors we accordingly encode and transmit objects of the image in order with a structured bitstream. In this way, diverse vision benchmarks including image classification, object detection, instance segmentation, etc., can be well supported with such a semantically structured bitstream. We dub our method ``\textit{SDComp}'' for ``\textit{S}emantically \textit{D}isentangled \textit{Comp}ression'', and compare it with state-of-the-art codecs on a wide variety of different vision tasks. SDComp codec leads to more flexible reconstruction results, promised decoded visual quality, and a more generic/satisfactory intelligent task-supporting ability.
Rate-Distortion-Cognition Controllable Versatile Neural Image Compression
Jul 16, 2024Recently, the field of Image Coding for Machines (ICM) has garnered heightened interest and significant advances thanks to the rapid progress of learning-based techniques for image compression and analysis. Previous studies often require training separate codecs to support various bitrate levels, machine tasks, and networks, thus lacking both flexibility and practicality. To address these challenges, we propose a rate-distortion-cognition controllable versatile image compression, which method allows the users to adjust the bitrate (i.e., Rate), image reconstruction quality (i.e., Distortion), and machine task accuracy (i.e., Cognition) with a single neural model, achieving ultra-controllability. Specifically, we first introduce a cognition-oriented loss in the primary compression branch to train a codec for diverse machine tasks. This branch attains variable bitrate by regulating quantization degree through the latent code channels. To further enhance the quality of the reconstructed images, we employ an auxiliary branch to supplement residual information with a scalable bitstream. Ultimately, two branches use a `$\beta x + (1 - \beta) y$' interpolation strategy to achieve a balanced cognition-distortion trade-off. Extensive experiments demonstrate that our method yields satisfactory ICM performance and flexible Rate-Distortion-Cognition controlling.
Closed-Loop Unsupervised Representation Disentanglement with $β$-VAE Distillation and Diffusion Probabilistic Feedback
Feb 04, 2024Representation disentanglement may help AI fundamentally understand the real world and thus benefit both discrimination and generation tasks. It currently has at least three unresolved core issues: (i) heavy reliance on label annotation and synthetic data -- causing poor generalization on natural scenarios; (ii) heuristic/hand-craft disentangling constraints make it hard to adaptively achieve an optimal training trade-off; (iii) lacking reasonable evaluation metric, especially for the real label-free data. To address these challenges, we propose a \textbf{C}losed-\textbf{L}oop unsupervised representation \textbf{Dis}entanglement approach dubbed \textbf{CL-Dis}. Specifically, we use diffusion-based autoencoder (Diff-AE) as a backbone while resorting to $\beta$-VAE as a co-pilot to extract semantically disentangled representations. The strong generation ability of diffusion model and the good disentanglement ability of VAE model are complementary. To strengthen disentangling, VAE-latent distillation and diffusion-wise feedback are interconnected in a closed-loop system for a further mutual promotion. Then, a self-supervised \textbf{Navigation} strategy is introduced to identify interpretable semantic directions in the disentangled latent space. Finally, a new metric based on content tracking is designed to evaluate the disentanglement effect. Experiments demonstrate the superiority of CL-Dis on applications like real image manipulation and visual analysis.
One at A Time: Multi-step Volumetric Probability Distribution Diffusion for Depth Estimation
Jul 07, 2023Recent works have explored the fundamental role of depth estimation in multi-view stereo (MVS) and semantic scene completion (SSC). They generally construct 3D cost volumes to explore geometric correspondence in depth, and estimate such volumes in a single step relying directly on the ground truth approximation. However, such problem cannot be thoroughly handled in one step due to complex empirical distributions, especially in challenging regions like occlusions, reflections, etc. In this paper, we formulate the depth estimation task as a multi-step distribution approximation process, and introduce a new paradigm of modeling the Volumetric Probability Distribution progressively (step-by-step) following a Markov chain with Diffusion models (VPDD). Specifically, to constrain the multi-step generation of volume in VPDD, we construct a meta volume guidance and a confidence-aware contextual guidance as conditional geometry priors to facilitate the distribution approximation. For the sampling process, we further investigate an online filtering strategy to maintain consistency in volume representations for stable training. Experiments demonstrate that our plug-and-play VPDD outperforms the state-of-the-arts for tasks of MVS and SSC, and can also be easily extended to different baselines to get improvement. It is worth mentioning that we are the first camera-based work that surpasses LiDAR-based methods on the SemanticKITTI dataset.
EMoG: Synthesizing Emotive Co-speech 3D Gesture with Diffusion Model
Jun 20, 2023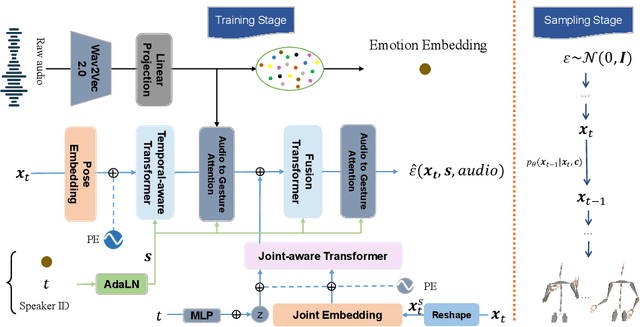
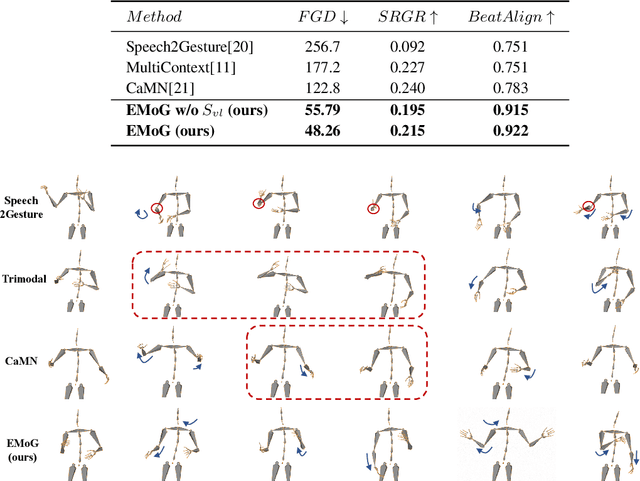
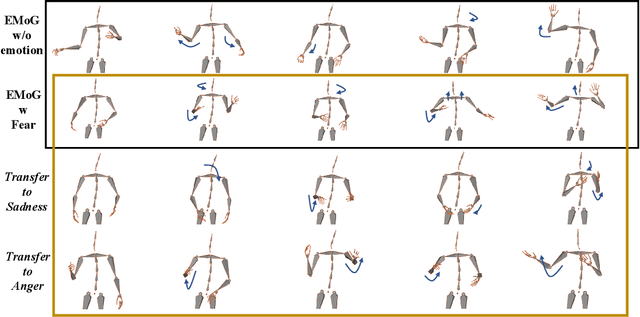
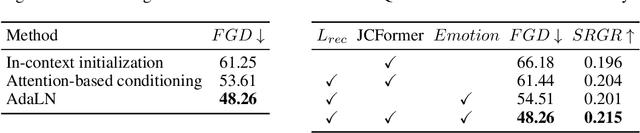
Although previous co-speech gesture generation methods are able to synthesize motions in line with speech content, it is still not enough to handle diverse and complicated motion distribution. The key challenges are: 1) the one-to-many nature between the speech content and gestures; 2) the correlation modeling between the body joints. In this paper, we present a novel framework (EMoG) to tackle the above challenges with denoising diffusion models: 1) To alleviate the one-to-many problem, we incorporate emotion clues to guide the generation process, making the generation much easier; 2) To model joint correlation, we propose to decompose the difficult gesture generation into two sub-problems: joint correlation modeling and temporal dynamics modeling. Then, the two sub-problems are explicitly tackled with our proposed Joint Correlation-aware transFormer (JCFormer). Through extensive evaluations, we demonstrate that our proposed method surpasses previous state-of-the-art approaches, offering substantial superiority in gesture synthesis.
Prompt-ICM: A Unified Framework towards Image Coding for Machines with Task-driven Prompts
May 04, 2023Image coding for machines (ICM) aims to compress images to support downstream AI analysis instead of human perception. For ICM, developing a unified codec to reduce information redundancy while empowering the compressed features to support various vision tasks is very important, which inevitably faces two core challenges: 1) How should the compression strategy be adjusted based on the downstream tasks? 2) How to well adapt the compressed features to different downstream tasks? Inspired by recent advances in transferring large-scale pre-trained models to downstream tasks via prompting, in this work, we explore a new ICM framework, termed Prompt-ICM. To address both challenges by carefully learning task-driven prompts to coordinate well the compression process and downstream analysis. Specifically, our method is composed of two core designs: a) compression prompts, which are implemented as importance maps predicted by an information selector, and used to achieve different content-weighted bit allocations during compression according to different downstream tasks; b) task-adaptive prompts, which are instantiated as a few learnable parameters specifically for tuning compressed features for the specific intelligent task. Extensive experiments demonstrate that with a single feature codec and a few extra parameters, our proposed framework could efficiently support different kinds of intelligent tasks with much higher coding efficiency.