 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Constrained Diffusion Image Compression for Operational Rate-Distortion-Perception Optimization
Jun 11, 2026The rate-distortion-perception (RDP) trade-off extends classical rate--distortion theory by imposing a distributional constraint on reconstructions, providing a unified framework for neural image compression that jointly governs fidelity and perceptual realism. While prior work achieves near-optimal rate--perception trade-offs, practical frameworks explicitly realizing the full RDP surface remain scarce, primarily due to the difficulty of introducing common randomness at the decoder. We propose DCIC (Dual-Constrained Diffusion Image Compression), which integrates a learned codec with a diffusion-based decoder governed by joint distortion and idempotence constraints. The distortion constraint bounds reconstruction fidelity relative to the base codec output; the idempotence constraint -- requiring that re-encoding the restored image recovers the base codec reconstruction -- serves as a tractable surrogate for the distributional perception requirement. Together, they steer the reverse denoising process via iterative optimization with consistent noise injection, realizing common randomness without additional rate overhead. At fixed rate, dual attenuation factors $(K_D, K_P)$ jointly navigate the Pareto frontier of the distortion-perception plane, enabling continuously adjustable fidelity-realism trade-offs from a single bitstream. DCIC$_{RD}$ ($K_P{=}0$) and DCIC$_{RP}$ ($K_D{=}0$) arise as boundary curves, with DCIC$_{RDP}$ ($K_D = K_P=1$) realizing the optimal interior operating point. Experiments on CelebA-HQ, CLIC2020, and ImageNet-1K across CNN, Transformer, and hybrid architectures confirm that DCIC$_{RDP}$ achieves superior BD-PSNR over all perceptual codecs, while DCIC$_{RP}$ matches dedicated perception-oriented methods in BD-FID, validating the practical value of full RDP surface navigation.
Real-time Video Prediction With Fast Video Interpolation Model and Prediction Training
Mar 29, 2025Transmission latency significantly affects users' quality of experience in real-time interaction and actuation. As latency is principally inevitable, video prediction can be utilized to mitigate the latency and ultimately enable zero-latency transmission. However, most of the existing video prediction methods are computationally expensive and impractical for real-time applications. In this work, we therefore propose real-time video prediction towards the zero-latency interaction over networks, called IFRVP (Intermediate Feature Refinement Video Prediction). Firstly, we propose three training methods for video prediction that extend frame interpolation models, where we utilize a simple convolution-only frame interpolation network based on IFRNet. Secondly, we introduce ELAN-based residual blocks into the prediction models to improve both inference speed and accuracy. Our evaluations show that our proposed models perform efficiently and achieve the best trade-off between prediction accuracy and computational speed among the existing video prediction methods. A demonstration movie is also provided at http://bit.ly/IFRVPDemo.
Performance Analysis of 5G FR2 (mmWave) Downlink 256QAM on Commercial 5G Networks
Feb 05, 2025

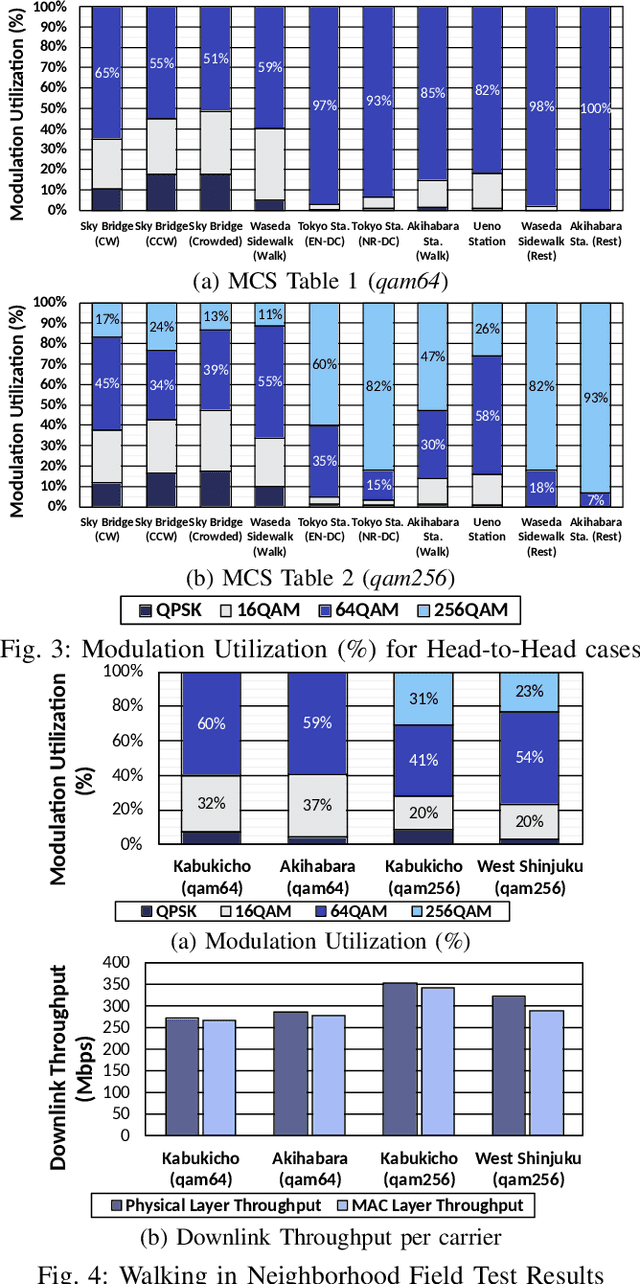

The 5G New Radio (NR) standard introduces new frequency bands allocated in Frequency Range 2 (FR2) to support enhanced Mobile Broadband (eMBB) in congested environments and enables new use cases such as Ultra-Reliable Low Latency Communication (URLLC). The 3GPP introduced 256QAM support for FR2 frequency bands to further enhance downlink capacity. However, sustaining 256QAM on FR2 in practical environments is challenging due to strong path loss and susceptibility to distortion. While 256QAM can improve theoretical throughput by 33%, compared to 64QAM, and is widely adopted in FR1, its real-world impact when utilized in FR2 is questionable, given the significant path loss and distortions experienced in the FR2 range. Additionally, using higher modulation correlates to higher BLER, increased instability, and retransmission. Moreover, 256QAM also utilizes a different MCS table defining the modulation and code rate at different Channel Quality Indexes (CQI), affecting the UE's link adaptation behavior. This paper investigates the real-world performance of 256QAM utilization on FR2 bands in two countries, across three RAN manufacturers, and in both NSA (EN-DC) and SA (NR-DC) configurations, under various scenarios, including open-air plazas, city centers, footbridges, train station platforms, and stationary environments. The results show that 256QAM provides a reasonable throughput gain when stationary but marginal improvements when there is UE mobility while increasing the probability of NACK responses, increasing BLER, and the number of retransmissions. Finally, MATLAB simulations are run to validate the findings as well as explore the effect of the recently introduced 1024QAM on FR2.
Lightweight Stochastic Video Prediction via Hybrid Warping
Dec 04, 2024



Accurate video prediction by deep neural networks, especially for dynamic regions, is a challenging task in computer vision for critical applications such as autonomous driving, remote working, and telemedicine. Due to inherent uncertainties, existing prediction models often struggle with the complexity of motion dynamics and occlusions. In this paper, we propose a novel stochastic long-term video prediction model that focuses on dynamic regions by employing a hybrid warping strategy. By integrating frames generated through forward and backward warpings, our approach effectively compensates for the weaknesses of each technique, improving the prediction accuracy and realism of moving regions in videos while also addressing uncertainty by making stochastic predictions that account for various motions. Furthermore, considering real-time predictions, we introduce a MobileNet-based lightweight architecture into our model. Our model, called SVPHW, achieves state-of-the-art performance on two benchmark datasets.
LMM-driven Semantic Image-Text Coding for Ultra Low-bitrate Learned Image Compression
Nov 20, 2024



Supported by powerful generative models, low-bitrate learned image compression (LIC) models utilizing perceptual metrics have become feasible. Some of the most advanced models achieve high compression rates and superior perceptual quality by using image captions as sub-information. This paper demonstrates that using a large multi-modal model (LMM), it is possible to generate captions and compress them within a single model. We also propose a novel semantic-perceptual-oriented fine-tuning method applicable to any LIC network, resulting in a 41.58\% improvement in LPIPS BD-rate compared to existing methods. Our implementation and pre-trained weights are available at https://github.com/tokkiwa/ImageTextCoding.
SCP: Spherical-Coordinate-based Learned Point Cloud Compression
Aug 24, 2023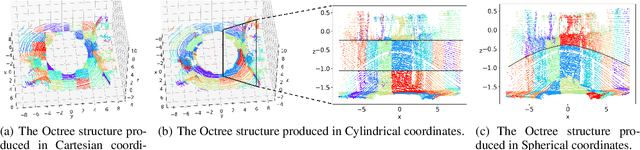
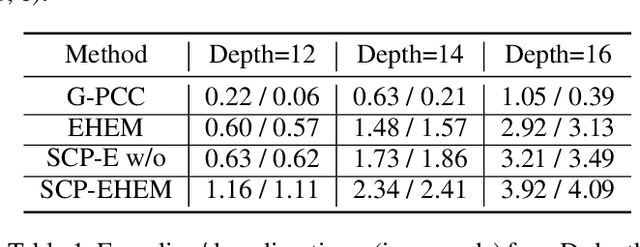
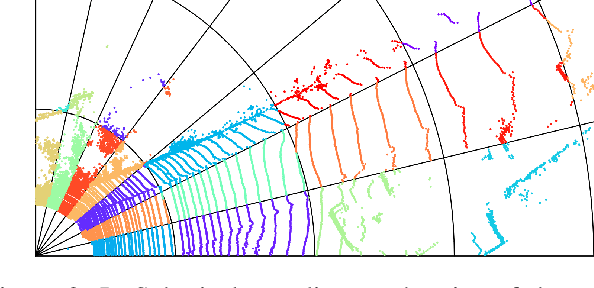
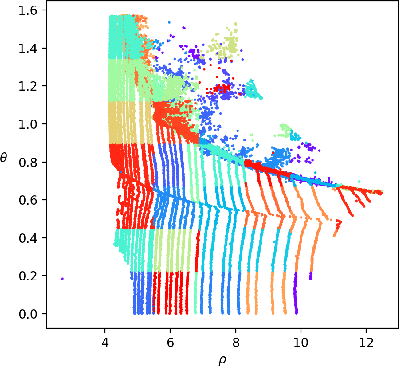
In recent years, the task of learned point cloud compression has gained prominence. An important type of point cloud, the spinning LiDAR point cloud, is generated by spinning LiDAR on vehicles. This process results in numerous circular shapes and azimuthal angle invariance features within the point clouds. However, these two features have been largely overlooked by previous methodologies. In this paper, we introduce a model-agnostic method called Spherical-Coordinate-based learned Point cloud compression (SCP), designed to leverage the aforementioned features fully. Additionally, we propose a multi-level Octree for SCP to mitigate the reconstruction error for distant areas within the Spherical-coordinate-based Octree. SCP exhibits excellent universality, making it applicable to various learned point cloud compression techniques. Experimental results demonstrate that SCP surpasses previous state-of-the-art methods by up to 29.14% in point-to-point PSNR BD-Rate.
Practical Commercial 5G Standalone (SA) Uplink Throughput Prediction
Jul 23, 2023



While the 5G New Radio (NR) network promises a huge uplift of the uplink throughput, the improvement can only be seen when the User Equipment (UE) is connected to the high-frequency millimeter wave (mmWave) band. With the rise of uplink-intensive smartphone applications such as the real-time transmission of UHD 4K/8K videos, and Virtual Reality (VR)/Augmented Reality (AR) contents, uplink throughput prediction plays a huge role in maximizing the users' quality of experience (QoE). In this paper, we propose using a ConvLSTM-based neural network to predict the future uplink throughput based on past uplink throughput and RF parameters. The network is trained using the data from real-world drive tests on commercial 5G SA networks while riding commuter trains, which accounted for various frequency bands, handover, and blind spots. To make sure our model can be practically implemented, we then limited our model to only use the information available via Android API, then evaluate our model using the data from both commuter trains and other methods of transportation. The results show that our model reaches an average prediction accuracy of 98.9\% with an average RMSE of 1.80 Mbps across all unseen evaluation scenarios.
Learned Image Compression with Mixed Transformer-CNN Architectures
Mar 27, 2023



Learned image compression (LIC) methods have exhibited promising progress and superior rate-distortion performance compared with classical image compression standards. Most existing LIC methods are Convolutional Neural Networks-based (CNN-based) or Transformer-based, which have different advantages. Exploiting both advantages is a point worth exploring, which has two challenges: 1) how to effectively fuse the two methods? 2) how to achieve higher performance with a suitable complexity? In this paper, we propose an efficient parallel Transformer-CNN Mixture (TCM) block with a controllable complexity to incorporate the local modeling ability of CNN and the non-local modeling ability of transformers to improve the overall architecture of image compression models. Besides, inspired by the recent progress of entropy estimation models and attention modules, we propose a channel-wise entropy model with parameter-efficient swin-transformer-based attention (SWAtten) modules by using channel squeezing. Experimental results demonstrate our proposed method achieves state-of-the-art rate-distortion performances on three different resolution datasets (i.e., Kodak, Tecnick, CLIC Professional Validation) compared to existing LIC methods. The code is at https://github.com/jmliu206/LIC_TCM.
Multistage Spatial Context Models for Learned Image Compression
Feb 18, 2023Recent state-of-the-art Learned Image Compression methods feature spatial context models, achieving great rate-distortion improvements over hyperprior methods. However, the autoregressive context model requires serial decoding, limiting runtime performance. The Checkerboard context model allows parallel decoding at a cost of reduced RD performance. We present a series of multistage spatial context models allowing both fast decoding and better RD performance. We split the latent space into square patches and decode serially within each patch while different patches are decoded in parallel. The proposed method features a comparable decoding speed to Checkerboard while reaching the RD performance of Autoregressive and even also outperforming Autoregressive. Inside each patch, the decoding order must be carefully decided as a bad order negatively impacts performance; therefore, we also propose a decoding order optimization algorithm.
Pensieve 5G: Implementation of RL-based ABR Algorithm for UHD 4K/8K Content Delivery on Commercial 5G SA/NR-DC Network
Dec 29, 2022



While the rollout of the fifth-generation mobile network (5G) is underway across the globe with the intention to deliver 4K/8K UHD videos, Augmented Reality (AR), and Virtual Reality (VR) content to the mass amounts of users, the coverage and throughput are still one of the most significant issues, especially in the rural areas, where only 5G in the low-frequency band are being deployed. This called for a high-performance adaptive bitrate (ABR) algorithm that can maximize the user quality of experience given 5G network characteristics and data rate of UHD contents. Recently, many of the newly proposed ABR techniques were machine-learning based. Among that, Pensieve is one of the state-of-the-art techniques, which utilized reinforcement-learning to generate an ABR algorithm based on observation of past decision performance. By incorporating the context of the 5G network and UHD content, Pensieve has been optimized into Pensieve 5G. New QoE metrics that more accurately represent the QoE of UHD video streaming on the different types of devices were proposed and used to evaluate Pensieve 5G against other ABR techniques including the original Pensieve. The results from the simulation based on the real 5G Standalone (SA) network throughput shows that Pensieve 5G outperforms both conventional algorithms and Pensieve with the average QoE improvement of 8.8% and 14.2%, respectively. Additionally, Pensieve 5G also performed well on the commercial 5G NR-NR Dual Connectivity (NR-DC) Network, despite the training being done solely using the data from the 5G Standalone (SA) network.