 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-time Video Prediction With Fast Video Interpolation Model and Prediction Training
Mar 29, 2025Transmission latency significantly affects users' quality of experience in real-time interaction and actuation. As latency is principally inevitable, video prediction can be utilized to mitigate the latency and ultimately enable zero-latency transmission. However, most of the existing video prediction methods are computationally expensive and impractical for real-time applications. In this work, we therefore propose real-time video prediction towards the zero-latency interaction over networks, called IFRVP (Intermediate Feature Refinement Video Prediction). Firstly, we propose three training methods for video prediction that extend frame interpolation models, where we utilize a simple convolution-only frame interpolation network based on IFRNet. Secondly, we introduce ELAN-based residual blocks into the prediction models to improve both inference speed and accuracy. Our evaluations show that our proposed models perform efficiently and achieve the best trade-off between prediction accuracy and computational speed among the existing video prediction methods. A demonstration movie is also provided at http://bit.ly/IFRVPDemo.
Continual-learning-based framework for structural damage recognition
Aug 28, 2024Multi-damage is common in reinforced concrete structures and leads to the requirement of large number of neural networks, parameters and data storage, if convolutional neural network (CNN) is used for damage recognition. In addition, conventional CNN experiences catastrophic forgetting and training inefficiency as the number of tasks increases during continual learning, leading to large accuracy decrease of previous learned tasks. To address these problems, this study proposes a continuallearning-based damage recognition model (CLDRM) which integrates the learning without forgetting continual learning method into the ResNet-34 architecture for the recognition of damages in RC structures as well as relevant structural components. Three experiments for four recognition tasks were designed to validate the feasibility and effectiveness of the CLDRM framework. In this way, it reduces both the prediction time and data storage by about 75% in four tasks of continuous learning. Three experiments for four recognition tasks were designed to validate the feasibility and effectiveness of the CLDRM framework. By gradual feature fusion, CLDRM outperformed other methods by managed to achieve high accuracy in the damage recognition and classification. As the number of recognition tasks increased, CLDRM also experienced smaller decrease of the previous learned tasks. Results indicate that the CLDRM framework successfully performs damage recognition and classification with reasonable accuracy and effectiveness.
Multistage Spatial Context Models for Learned Image Compression
Feb 18, 2023Recent state-of-the-art Learned Image Compression methods feature spatial context models, achieving great rate-distortion improvements over hyperprior methods. However, the autoregressive context model requires serial decoding, limiting runtime performance. The Checkerboard context model allows parallel decoding at a cost of reduced RD performance. We present a series of multistage spatial context models allowing both fast decoding and better RD performance. We split the latent space into square patches and decode serially within each patch while different patches are decoded in parallel. The proposed method features a comparable decoding speed to Checkerboard while reaching the RD performance of Autoregressive and even also outperforming Autoregressive. Inside each patch, the decoding order must be carefully decided as a bad order negatively impacts performance; therefore, we also propose a decoding order optimization algorithm.
A comparative study of attention mechanism and generative adversarial network in facade damage segmentation
Sep 27, 2022
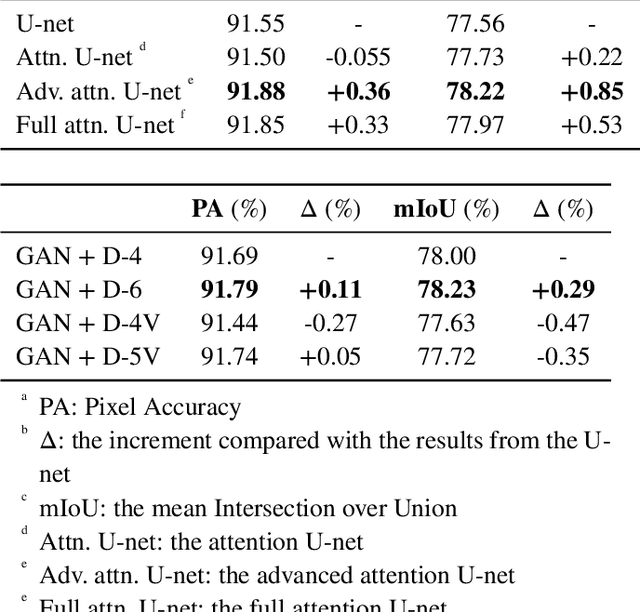
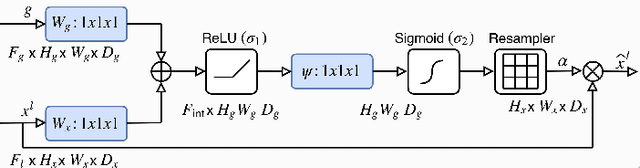

Semantic segmentation profits from deep learning and has shown its possibilities in handling the graphical data from the on-site inspection. As a result, visual damage in the facade images should be detected. Attention mechanism and generative adversarial networks are two of the most popular strategies to improve the quality of semantic segmentation. With specific focuses on these two strategies, this paper adopts U-net, a representative convolutional neural network, as the primary network and presents a comparative study in two steps. First, cell images are utilized to respectively determine the most effective networks among the U-nets with attention mechanism or generative adversarial networks. Subsequently, selected networks from the first test and their combination are applied for facade damage segmentation to investigate the performances of these networks. Besides, the combined effect of the attention mechanism and the generative adversarial network is discovered and discussed.
Streaming-capable High-performance Architecture of Learned Image Compression Codecs
Aug 02, 2022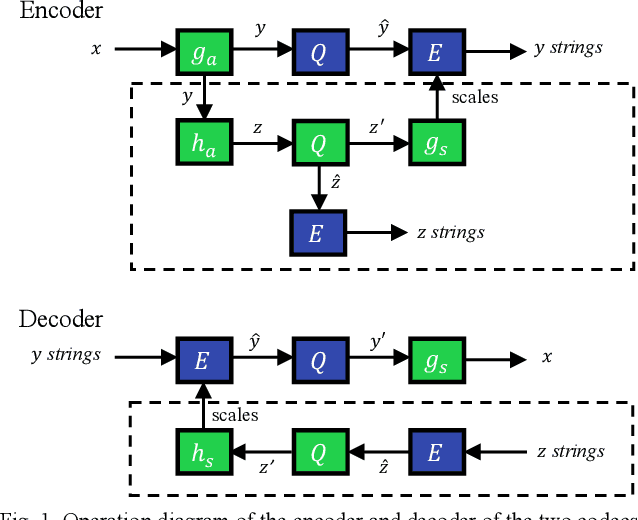

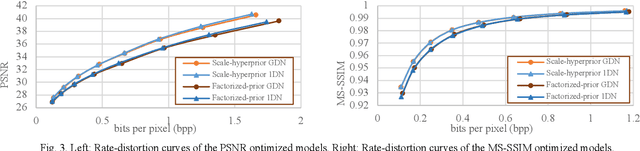
Learned image compression allows achieving state-of-the-art accuracy and compression ratios, but their relatively slow runtime performance limits their usage. While previous attempts on optimizing learned image codecs focused more on the neural model and entropy coding, we present an alternative method to improving the runtime performance of various learned image compression models. We introduce multi-threaded pipelining and an optimized memory model to enable GPU and CPU workloads asynchronous execution, fully taking advantage of computational resources. Our architecture alone already produces excellent performance without any change to the neural model itself. We also demonstrate that combining our architecture with previous tweaks to the neural models can further improve runtime performance. We show that our implementations excel in throughput and latency compared to the baseline and demonstrate the performance of our implementations by creating a real-time video streaming encoder-decoder sample application, with the encoder running on an embedded device.
Fast Crack Detection Using Convolutional Neural Network
May 23, 2021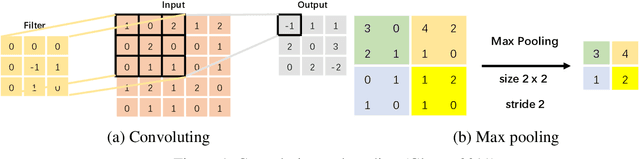
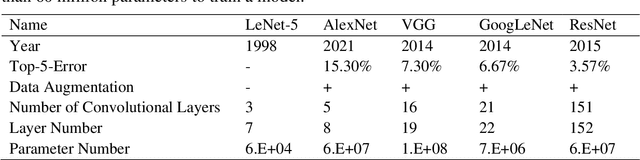
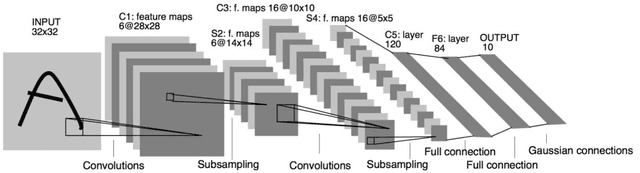

To improve the efficiency and reduce the labour cost of the renovation process, this study presents a lightweight Convolutional Neural Network (CNN)-based architecture to extract crack-like features, such as cracks and joints. Moreover, Transfer Learning (TF) method was used to save training time while offering comparable prediction results. For three different objectives: 1) Detection of the concrete cracks; 2) Detection of natural stone cracks; 3) Differentiation between joints and cracks in natural stone; We built a natural stone dataset with joints and cracks information as complementary for the concrete benchmark dataset. As the results show, our model is demonstrated as an effective tool for industry use.
Crack Semantic Segmentation using the U-Net with Full Attention Strategy
Apr 29, 2021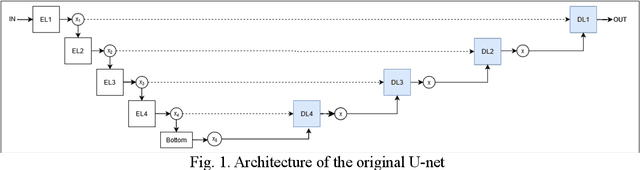
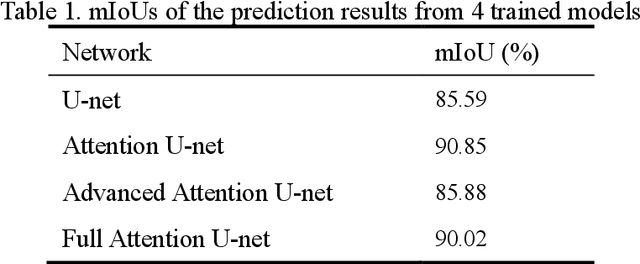


Structures suffer from the emergence of cracks, therefore, crack detection is always an issue with much concern in structural health monitoring. Along with the rapid progress of deep learning technology, image semantic segmentation, an active research field, offers another solution, which is more effective and intelligent, to crack detection Through numerous artificial neural networks have been developed to address the preceding issue, corresponding explorations are never stopped improving the quality of crack detection. This paper presents a novel artificial neural network architecture named Full Attention U-net for image semantic segmentation. The proposed architecture leverages the U-net as the backbone and adopts the Full Attention Strategy, which is a synthesis of the attention mechanism and the outputs from each encoding layer in skip connection. Subject to the hardware in training, the experiments are composed of verification and validation. In verification, 4 networks including U-net, Attention U-net, Advanced Attention U-net, and Full Attention U-net are tested through cell images for a competitive study. With respect to mean intersection-over-unions and clarity of edge identification, the Full Attention U-net performs best in verification, and is hence applied for crack semantic segmentation in validation to demonstrate its effectiveness.