 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMdoctor: Token-Level Flow-Guided Preference Optimization for Efficient Test-Time Alignment of Large Language Models
Jan 15, 2026Aligning Large Language Models (LLMs) with human preferences is critical, yet traditional fine-tuning methods are computationally expensive and inflexible. While test-time alignment offers a promising alternative, existing approaches often rely on distorted trajectory-level signals or inefficient sampling, fundamentally capping performance and failing to preserve the generative diversity of the base model. This paper introduces LLMdoctor, a novel framework for efficient test-time alignment that operates via a patient-doctor paradigm. It integrates token-level reward acquisition with token-level flow-guided preference optimization (TFPO) to steer a large, frozen patient LLM with a smaller, specialized doctor model. Unlike conventional methods that rely on trajectory-level rewards, LLMdoctor first extracts fine-grained, token-level preference signals from the patient model's behavioral variations. These signals then guide the training of the doctor model via TFPO, which establishes flow consistency across all subtrajectories, enabling precise token-by-token alignment while inherently preserving generation diversity. Extensive experiments demonstrate that LLMdoctor significantly outperforms existing test-time alignment methods and even surpasses the performance of full fine-tuning approaches like DPO.
Real-time Video Prediction With Fast Video Interpolation Model and Prediction Training
Mar 29, 2025Transmission latency significantly affects users' quality of experience in real-time interaction and actuation. As latency is principally inevitable, video prediction can be utilized to mitigate the latency and ultimately enable zero-latency transmission. However, most of the existing video prediction methods are computationally expensive and impractical for real-time applications. In this work, we therefore propose real-time video prediction towards the zero-latency interaction over networks, called IFRVP (Intermediate Feature Refinement Video Prediction). Firstly, we propose three training methods for video prediction that extend frame interpolation models, where we utilize a simple convolution-only frame interpolation network based on IFRNet. Secondly, we introduce ELAN-based residual blocks into the prediction models to improve both inference speed and accuracy. Our evaluations show that our proposed models perform efficiently and achieve the best trade-off between prediction accuracy and computational speed among the existing video prediction methods. A demonstration movie is also provided at http://bit.ly/IFRVPDemo.
Semantics Disentanglement and Composition for Versatile Codec toward both Human-eye Perception and Machine Vision Task
Dec 24, 2024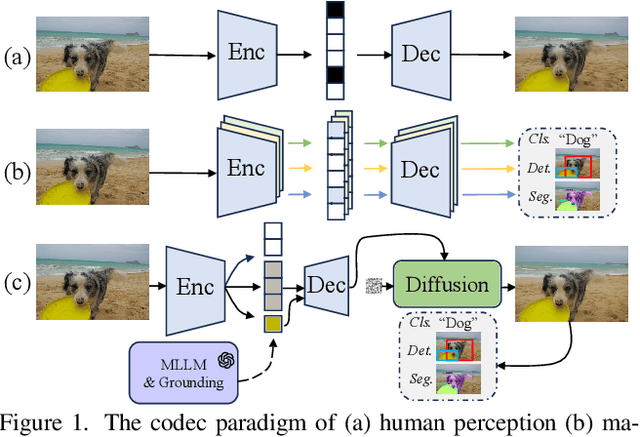



While learned image compression methods have achieved impressive results in either human visual perception or machine vision tasks, they are often specialized only for one domain. This drawback limits their versatility and generalizability across scenarios and also requires retraining to adapt to new applications-a process that adds significant complexity and cost in real-world scenarios. In this study, we introduce an innovative semantics DISentanglement and COmposition VERsatile codec (DISCOVER) to simultaneously enhance human-eye perception and machine vision tasks. The approach derives a set of labels per task through multimodal large models, which grounding models are then applied for precise localization, enabling a comprehensive understanding and disentanglement of image components at the encoder side. At the decoding stage, a comprehensive reconstruction of the image is achieved by leveraging these encoded components alongside priors from generative models, thereby optimizing performance for both human visual perception and machine-based analytical tasks. Extensive experimental evaluations substantiate the robustness and effectiveness of DISCOVER, demonstrating superior performance in fulfilling the dual objectives of human and machine vision requirements.
Lightweight Stochastic Video Prediction via Hybrid Warping
Dec 04, 2024



Accurate video prediction by deep neural networks, especially for dynamic regions, is a challenging task in computer vision for critical applications such as autonomous driving, remote working, and telemedicine. Due to inherent uncertainties, existing prediction models often struggle with the complexity of motion dynamics and occlusions. In this paper, we propose a novel stochastic long-term video prediction model that focuses on dynamic regions by employing a hybrid warping strategy. By integrating frames generated through forward and backward warpings, our approach effectively compensates for the weaknesses of each technique, improving the prediction accuracy and realism of moving regions in videos while also addressing uncertainty by making stochastic predictions that account for various motions. Furthermore, considering real-time predictions, we introduce a MobileNet-based lightweight architecture into our model. Our model, called SVPHW, achieves state-of-the-art performance on two benchmark datasets.
LMM-driven Semantic Image-Text Coding for Ultra Low-bitrate Learned Image Compression
Nov 20, 2024



Supported by powerful generative models, low-bitrate learned image compression (LIC) models utilizing perceptual metrics have become feasible. Some of the most advanced models achieve high compression rates and superior perceptual quality by using image captions as sub-information. This paper demonstrates that using a large multi-modal model (LMM), it is possible to generate captions and compress them within a single model. We also propose a novel semantic-perceptual-oriented fine-tuning method applicable to any LIC network, resulting in a 41.58\% improvement in LPIPS BD-rate compared to existing methods. Our implementation and pre-trained weights are available at https://github.com/tokkiwa/ImageTextCoding.
Multi-diseases detection with memristive system on chip
Oct 18, 2024



This study presents the first implementation of multilayer neural networks on a memristor/CMOS integrated system on chip (SoC) to simultaneously detect multiple diseases. To overcome limitations in medical data, generative AI techniques are used to enhance the dataset, improving the classifier's robustness and diversity. The system achieves notable performance with low latency, high accuracy (91.82%), and energy efficiency, facilitated by end-to-end execution on a memristor-based SoC with ten 256x256 crossbar arrays and an integrated on-chip processor. This research showcases the transformative potential of memristive in-memory computing hardware in accelerating machine learning applications for medical diagnostics.
Tell Codec What Worth Compressing: Semantically Disentangled Image Coding for Machine with LMMs
Aug 16, 2024



We present a new image compression paradigm to achieve ``intelligently coding for machine'' by cleverly leveraging the common sense of Large Multimodal Models (LMMs). We are motivated by the evidence that large language/multimodal models are powerful general-purpose semantics predictors for understanding the real world. Different from traditional image compression typically optimized for human eyes, the image coding for machines (ICM) framework we focus on requires the compressed bitstream to more comply with different downstream intelligent analysis tasks. To this end, we employ LMM to \textcolor{red}{tell codec what to compress}: 1) first utilize the powerful semantic understanding capability of LMMs w.r.t object grounding, identification, and importance ranking via prompts, to disentangle image content before compression, 2) and then based on these semantic priors we accordingly encode and transmit objects of the image in order with a structured bitstream. In this way, diverse vision benchmarks including image classification, object detection, instance segmentation, etc., can be well supported with such a semantically structured bitstream. We dub our method ``\textit{SDComp}'' for ``\textit{S}emantically \textit{D}isentangled \textit{Comp}ression'', and compare it with state-of-the-art codecs on a wide variety of different vision tasks. SDComp codec leads to more flexible reconstruction results, promised decoded visual quality, and a more generic/satisfactory intelligent task-supporting ability.
Survey on Visual Signal Coding and Processing with Generative Models: Technologies, Standards and Optimization
May 23, 2024
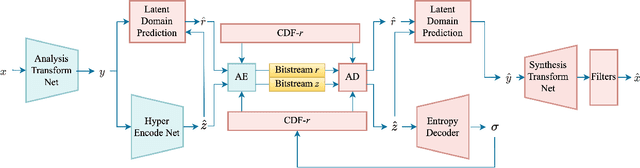
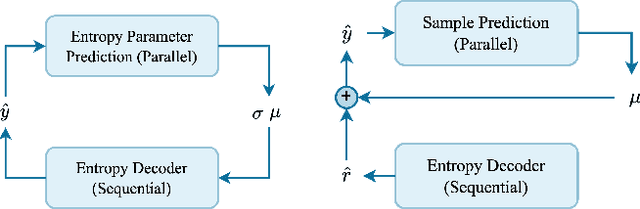
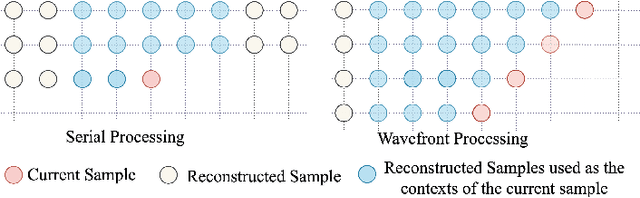
This paper provides a survey of the latest developments in visual signal coding and processing with generative models. Specifically, our focus is on presenting the advancement of generative models and their influence on research in the domain of visual signal coding and processing. This survey study begins with a brief introduction of well-established generative models, including the Variational Autoencoder (VAE) models, Generative Adversarial Network (GAN) models, Autoregressive (AR) models, Normalizing Flows and Diffusion models. The subsequent section of the paper explores the advancements in visual signal coding based on generative models, as well as the ongoing international standardization activities. In the realm of visual signal processing, our focus lies on the application and development of various generative models in the research of visual signal restoration. We also present the latest developments in generative visual signal synthesis and editing, along with visual signal quality assessment using generative models and quality assessment for generative models. The practical implementation of these studies is closely linked to the investigation of fast optimization. This paper additionally presents the latest advancements in fast optimization on visual signal coding and processing with generative models. We hope to advance this field by providing researchers and practitioners a comprehensive literature review on the topic of visual signal coding and processing with generative models.
Attack and Defense Analysis of Learned Image Compression
Jan 18, 2024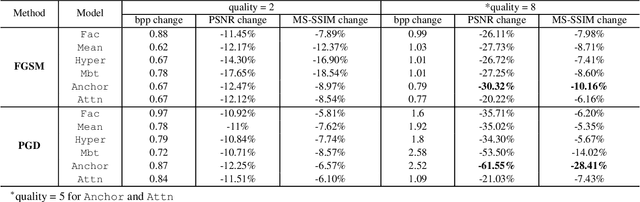

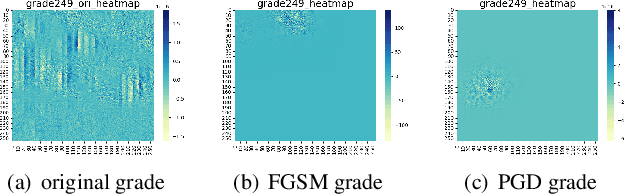
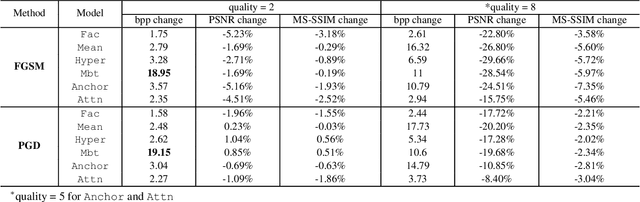
Learned image compression (LIC) is becoming more and more popular these years with its high efficiency and outstanding compression quality. Still, the practicality against modified inputs added with specific noise could not be ignored. White-box attacks such as FGSM and PGD use only gradient to compute adversarial images that mislead LIC models to output unexpected results. Our experiments compare the effects of different dimensions such as attack methods, models, qualities, and targets, concluding that in the worst case, there is a 61.55% decrease in PSNR or a 19.15 times increase in bit rate under the PGD attack. To improve their robustness, we conduct adversarial training by adding adversarial images into the training datasets, which obtains a 95.52% decrease in the R-D cost of the most vulnerable LIC model. We further test the robustness of H.266, whose better performance on reconstruction quality extends its possibility to defend one-step or iterative adversarial attacks.
Accelerating Learnt Video Codecs with Gradient Decay and Layer-wise Distillation
Dec 05, 2023



In recent years, end-to-end learnt video codecs have demonstrated their potential to compete with conventional coding algorithms in term of compression efficiency. However, most learning-based video compression models are associated with high computational complexity and latency, in particular at the decoder side, which limits their deployment in practical applications. In this paper, we present a novel model-agnostic pruning scheme based on gradient decay and adaptive layer-wise distillation. Gradient decay enhances parameter exploration during sparsification whilst preventing runaway sparsity and is superior to the standard Straight-Through Estimation. The adaptive layer-wise distillation regulates the sparse training in various stages based on the distortion of intermediate features. This stage-wise design efficiently updates parameters with minimal computational overhead. The proposed approach has been applied to three popular end-to-end learnt video codecs, FVC, DCVC, and DCVC-HEM. Results confirm that our method yields up to 65% reduction in MACs and 2x speed-up with less than 0.3dB drop in BD-PSNR. Supporting code and supplementary material can be downloaded from: https://jasminepp.github.io/lightweightdvc/