 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink-as-You-See: Streaming Chain-of-Thought Reasoning for Large Vision-Language Models
Mar 03, 2026Large Vision Language Models (LVLMs) exhibit strong Chain-of-Thought (CoT) capabilities, yet most existing paradigms assume full-video availability before inference, a batch-style process misaligned with real-world video streams where information arrives sequentially. Motivated by the streaming nature of video data, we investigate two streaming reasoning paradigms for LVLMs. The first, an interleaved paradigm, alternates between receiving frames and producing partial reasoning but remains constrained by strictly ordered cache updates. To better match streaming inputs, we propose \textbf{Think-as-You-See (TaYS)}, a unified framework enabling true concurrent reasoning. TaYS integrates parallelized CoT generation, stream-constrained training, and stream-parallel inference. It further employs temporally aligned reasoning units, streaming attention masks and positional encodings, and a dual KV-cache that decouples visual encoding from textual reasoning. We evaluate all paradigms on the Qwen2.5-VL family across representative video CoT tasks, including event dynamics analysis, causal reasoning, and thematic understanding. Experiments show that TaYS consistently outperforms both batch and interleaved baselines, improving reasoning performance while substantially reducing time-to-first-token (TTFT) and overall reasoning delay. These results demonstrate the effectiveness of data-aligned streaming reasoning in enabling efficient and responsive video understanding for LVLMs. We release our code at \href{https://github.com/EIT-NLP/StreamingLLM/tree/main/TaYS}{this repository.}
UTPTrack: Towards Simple and Unified Token Pruning for Visual Tracking
Feb 27, 2026One-stream Transformer-based trackers achieve advanced performance in visual object tracking but suffer from significant computational overhead that hinders real-time deployment. While token pruning offers a path to efficiency, existing methods are fragmented. They typically prune the search region, dynamic template, and static template in isolation, overlooking critical inter-component dependencies, which yields suboptimal pruning and degraded accuracy. To address this, we introduce UTPTrack, a simple and Unified Token Pruning framework that, for the first time, jointly compresses all three components. UTPTrack employs an attention-guided, token type-aware strategy to holistically model redundancy, a design that seamlessly supports unified tracking across multimodal and language-guided tasks within a single model. Extensive evaluations on 10 benchmarks demonstrate that UTPTrack achieves a new state-of-the-art in the accuracy-efficiency trade-off for pruning-based trackers, pruning 65.4% of vision tokens in RGB-based tracking and 67.5% in unified tracking while preserving 99.7% and 100.5% of baseline performance, respectively. This strong performance across both RGB and multimodal scenarios underlines its potential as a robust foundation for future research in efficient visual tracking. Code will be released at https://github.com/EIT-NLP/UTPTrack.
Compression Tells Intelligence: Visual Coding, Visual Token Technology, and the Unification
Jan 28, 2026"Compression Tells Intelligence", is supported by research in artificial intelligence, particularly concerning (multimodal) large language models (LLMs/MLLMs), where compression efficiency often correlates with improved model performance and capabilities. For compression, classical visual coding based on traditional information theory has developed over decades, achieving great success with numerous international industrial standards widely applied in multimedia (e.g., image/video) systems. Except that, the recent emergingvisual token technology of generative multi-modal large models also shares a similar fundamental objective like visual coding: maximizing semantic information fidelity during the representation learning while minimizing computational cost. Therefore, this paper provides a comprehensive overview of two dominant technique families first -- Visual Coding and Vision Token Technology -- then we further unify them from the aspect of optimization, discussing the essence of compression efficiency and model performance trade-off behind. Next, based on the proposed unified formulation bridging visual coding andvisual token technology, we synthesize bidirectional insights of themselves and forecast the next-gen visual codec and token techniques. Last but not least, we experimentally show a large potential of the task-oriented token developments in the more practical tasks like multimodal LLMs (MLLMs), AI-generated content (AIGC), and embodied AI, as well as shedding light on the future possibility of standardizing a general token technology like the traditional codecs (e.g., H.264/265) with high efficiency for a wide range of intelligent tasks in a unified and effective manner.
Speak While Watching: Unleashing TRUE Real-Time Video Understanding Capability of Multimodal Large Language Models
Jan 11, 2026Multimodal Large Language Models (MLLMs) have achieved strong performance across many tasks, yet most systems remain limited to offline inference, requiring complete inputs before generating outputs. Recent streaming methods reduce latency by interleaving perception and generation, but still enforce a sequential perception-generation cycle, limiting real-time interaction. In this work, we target a fundamental bottleneck that arises when extending MLLMs to real-time video understanding: the global positional continuity constraint imposed by standard positional encoding schemes. While natural in offline inference, this constraint tightly couples perception and generation, preventing effective input-output parallelism. To address this limitation, we propose a parallel streaming framework that relaxes positional continuity through three designs: Overlapped, Group-Decoupled, and Gap-Isolated. These designs enable simultaneous perception and generation, allowing the model to process incoming inputs while producing responses in real time. Extensive experiments reveal that Group-Decoupled achieves the best efficiency-performance balance, maintaining high fluency and accuracy while significantly reducing latency. We further show that the proposed framework yields up to 2x acceleration under balanced perception-generation workloads, establishing a principled pathway toward speak-while-watching real-time systems. We make all our code publicly available: https://github.com/EIT-NLP/Speak-While-Watching.
Rethinking Visual Layer Selection in Multimodal LLMs
Apr 30, 2025Multimodal large language models (MLLMs) have achieved impressive performance across a wide range of tasks, typically using CLIP-ViT as their visual encoder due to its strong text-image alignment capabilities. While prior studies suggest that different CLIP-ViT layers capture different types of information, with shallower layers focusing on fine visual details and deeper layers aligning more closely with textual semantics, most MLLMs still select visual features based on empirical heuristics rather than systematic analysis. In this work, we propose a Layer-wise Representation Similarity approach to group CLIP-ViT layers with similar behaviors into {shallow, middle, and deep} categories and assess their impact on MLLM performance. Building on this foundation, we revisit the visual layer selection problem in MLLMs at scale, training LLaVA-style models ranging from 1.4B to 7B parameters. Through extensive experiments across 10 datasets and 4 tasks, we find that: (1) deep layers are essential for OCR tasks; (2) shallow and middle layers substantially outperform deep layers on reasoning tasks involving counting, positioning, and object localization; (3) a lightweight fusion of features across shallow, middle, and deep layers consistently outperforms specialized fusion baselines and single-layer selections, achieving gains on 9 out of 10 datasets. Our work offers the first principled study of visual layer selection in MLLMs, laying the groundwork for deeper investigations into visual representation learning for MLLMs.
Dynamic Cross-Modal Feature Interaction Network for Hyperspectral and LiDAR Data Classification
Mar 10, 2025Hyperspectral image (HSI) and LiDAR data joint classification is a challenging task. Existing multi-source remote sensing data classification methods often rely on human-designed frameworks for feature extraction, which heavily depend on expert knowledge. To address these limitations, we propose a novel Dynamic Cross-Modal Feature Interaction Network (DCMNet), the first framework leveraging a dynamic routing mechanism for HSI and LiDAR classification. Specifically, our approach introduces three feature interaction blocks: Bilinear Spatial Attention Block (BSAB), Bilinear Channel Attention Block (BCAB), and Integration Convolutional Block (ICB). These blocks are designed to effectively enhance spatial, spectral, and discriminative feature interactions. A multi-layer routing space with routing gates is designed to determine optimal computational paths, enabling data-dependent feature fusion. Additionally, bilinear attention mechanisms are employed to enhance feature interactions in spatial and channel representations. Extensive experiments on three public HSI and LiDAR datasets demonstrate the superiority of DCMNet over state-of-the-art methods. Our code will be available at https://github.com/oucailab/DCMNet.
Multi-Layer Visual Feature Fusion in Multimodal LLMs: Methods, Analysis, and Best Practices
Mar 08, 2025Multimodal Large Language Models (MLLMs) have made significant advancements in recent years, with visual features playing an increasingly critical role in enhancing model performance. However, the integration of multi-layer visual features in MLLMs remains underexplored, particularly with regard to optimal layer selection and fusion strategies. Existing methods often rely on arbitrary design choices, leading to suboptimal outcomes. In this paper, we systematically investigate two core aspects of multi-layer visual feature fusion: (1) selecting the most effective visual layers and (2) identifying the best fusion approach with the language model. Our experiments reveal that while combining visual features from multiple stages improves generalization, incorporating additional features from the same stage typically leads to diminished performance. Furthermore, we find that direct fusion of multi-layer visual features at the input stage consistently yields superior and more stable performance across various configurations. We make all our code publicly available: https://github.com/EIT-NLP/Layer_Select_Fuse_for_MLLM.
Semantics Disentanglement and Composition for Versatile Codec toward both Human-eye Perception and Machine Vision Task
Dec 24, 2024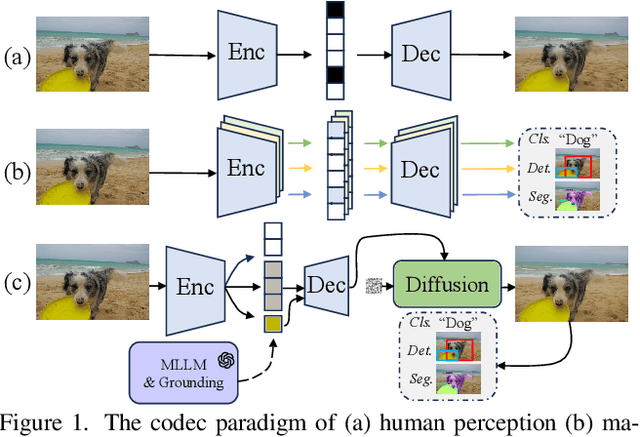



While learned image compression methods have achieved impressive results in either human visual perception or machine vision tasks, they are often specialized only for one domain. This drawback limits their versatility and generalizability across scenarios and also requires retraining to adapt to new applications-a process that adds significant complexity and cost in real-world scenarios. In this study, we introduce an innovative semantics DISentanglement and COmposition VERsatile codec (DISCOVER) to simultaneously enhance human-eye perception and machine vision tasks. The approach derives a set of labels per task through multimodal large models, which grounding models are then applied for precise localization, enabling a comprehensive understanding and disentanglement of image components at the encoder side. At the decoding stage, a comprehensive reconstruction of the image is achieved by leveraging these encoded components alongside priors from generative models, thereby optimizing performance for both human visual perception and machine-based analytical tasks. Extensive experimental evaluations substantiate the robustness and effectiveness of DISCOVER, demonstrating superior performance in fulfilling the dual objectives of human and machine vision requirements.
To Preserve or To Compress: An In-Depth Study of Connector Selection in Multimodal Large Language Models
Oct 09, 2024



In recent years, multimodal large language models (MLLMs) have garnered significant attention from both industry and academia. However, there is still considerable debate on constructing MLLM architectures, particularly regarding the selection of appropriate connectors for perception tasks of varying granularities. This paper systematically investigates the impact of connectors on MLLM performance. Specifically, we classify connectors into feature-preserving and feature-compressing types. Utilizing a unified classification standard, we categorize sub-tasks from three comprehensive benchmarks, MMBench, MME, and SEED-Bench, into three task types: coarse-grained perception, fine-grained perception, and reasoning, and evaluate the performance. Our findings reveal that feature-preserving connectors excel in \emph{fine-grained perception} tasks due to their ability to retain detailed visual information. In contrast, feature-compressing connectors, while less effective in fine-grained perception tasks, offer significant speed advantages and perform comparably in \emph{coarse-grained perception} and \emph{reasoning} tasks. These insights are crucial for guiding MLLM architecture design and advancing the optimization of MLLM architectures.
Tell Codec What Worth Compressing: Semantically Disentangled Image Coding for Machine with LMMs
Aug 16, 2024



We present a new image compression paradigm to achieve ``intelligently coding for machine'' by cleverly leveraging the common sense of Large Multimodal Models (LMMs). We are motivated by the evidence that large language/multimodal models are powerful general-purpose semantics predictors for understanding the real world. Different from traditional image compression typically optimized for human eyes, the image coding for machines (ICM) framework we focus on requires the compressed bitstream to more comply with different downstream intelligent analysis tasks. To this end, we employ LMM to \textcolor{red}{tell codec what to compress}: 1) first utilize the powerful semantic understanding capability of LMMs w.r.t object grounding, identification, and importance ranking via prompts, to disentangle image content before compression, 2) and then based on these semantic priors we accordingly encode and transmit objects of the image in order with a structured bitstream. In this way, diverse vision benchmarks including image classification, object detection, instance segmentation, etc., can be well supported with such a semantically structured bitstream. We dub our method ``\textit{SDComp}'' for ``\textit{S}emantically \textit{D}isentangled \textit{Comp}ression'', and compare it with state-of-the-art codecs on a wide variety of different vision tasks. SDComp codec leads to more flexible reconstruction results, promised decoded visual quality, and a more generic/satisfactory intelligent task-supporting ability.