 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantics Disentanglement and Composition for Versatile Codec toward both Human-eye Perception and Machine Vision Task
Dec 24, 2024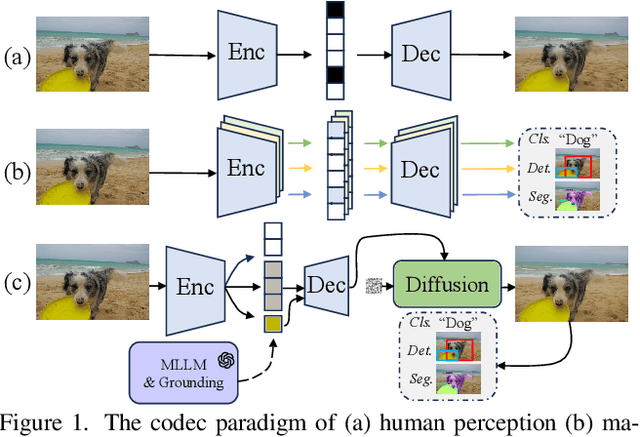



While learned image compression methods have achieved impressive results in either human visual perception or machine vision tasks, they are often specialized only for one domain. This drawback limits their versatility and generalizability across scenarios and also requires retraining to adapt to new applications-a process that adds significant complexity and cost in real-world scenarios. In this study, we introduce an innovative semantics DISentanglement and COmposition VERsatile codec (DISCOVER) to simultaneously enhance human-eye perception and machine vision tasks. The approach derives a set of labels per task through multimodal large models, which grounding models are then applied for precise localization, enabling a comprehensive understanding and disentanglement of image components at the encoder side. At the decoding stage, a comprehensive reconstruction of the image is achieved by leveraging these encoded components alongside priors from generative models, thereby optimizing performance for both human visual perception and machine-based analytical tasks. Extensive experimental evaluations substantiate the robustness and effectiveness of DISCOVER, demonstrating superior performance in fulfilling the dual objectives of human and machine vision requirements.
Tell Codec What Worth Compressing: Semantically Disentangled Image Coding for Machine with LMMs
Aug 16, 2024



We present a new image compression paradigm to achieve ``intelligently coding for machine'' by cleverly leveraging the common sense of Large Multimodal Models (LMMs). We are motivated by the evidence that large language/multimodal models are powerful general-purpose semantics predictors for understanding the real world. Different from traditional image compression typically optimized for human eyes, the image coding for machines (ICM) framework we focus on requires the compressed bitstream to more comply with different downstream intelligent analysis tasks. To this end, we employ LMM to \textcolor{red}{tell codec what to compress}: 1) first utilize the powerful semantic understanding capability of LMMs w.r.t object grounding, identification, and importance ranking via prompts, to disentangle image content before compression, 2) and then based on these semantic priors we accordingly encode and transmit objects of the image in order with a structured bitstream. In this way, diverse vision benchmarks including image classification, object detection, instance segmentation, etc., can be well supported with such a semantically structured bitstream. We dub our method ``\textit{SDComp}'' for ``\textit{S}emantically \textit{D}isentangled \textit{Comp}ression'', and compare it with state-of-the-art codecs on a wide variety of different vision tasks. SDComp codec leads to more flexible reconstruction results, promised decoded visual quality, and a more generic/satisfactory intelligent task-supporting ability.