 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStability as a Liability:Systematic Breakdown of Linguistic Structure in LLMs
Jan 26, 2026Training stability is typically regarded as a prerequisite for reliable optimization in large language models. In this work, we analyze how stabilizing training dynamics affects the induced generation distribution. We show that under standard maximum likelihood training, stable parameter trajectories lead stationary solutions to approximately minimize the forward KL divergence to the empirical distribution, while implicitly reducing generative entropy. As a consequence, the learned model can concentrate probability mass on a limited subset of empirical modes, exhibiting systematic degeneration despite smooth loss convergence. We empirically validate this effect using a controlled feedback-based training framework that stabilizes internal generation statistics, observing consistent low-entropy outputs and repetitive behavior across architectures and random seeds. It indicates that optimization stability and generative expressivity are not inherently aligned, and that stability alone is an insufficient indicator of generative quality.
Dynamic Cross-Modal Feature Interaction Network for Hyperspectral and LiDAR Data Classification
Mar 10, 2025Hyperspectral image (HSI) and LiDAR data joint classification is a challenging task. Existing multi-source remote sensing data classification methods often rely on human-designed frameworks for feature extraction, which heavily depend on expert knowledge. To address these limitations, we propose a novel Dynamic Cross-Modal Feature Interaction Network (DCMNet), the first framework leveraging a dynamic routing mechanism for HSI and LiDAR classification. Specifically, our approach introduces three feature interaction blocks: Bilinear Spatial Attention Block (BSAB), Bilinear Channel Attention Block (BCAB), and Integration Convolutional Block (ICB). These blocks are designed to effectively enhance spatial, spectral, and discriminative feature interactions. A multi-layer routing space with routing gates is designed to determine optimal computational paths, enabling data-dependent feature fusion. Additionally, bilinear attention mechanisms are employed to enhance feature interactions in spatial and channel representations. Extensive experiments on three public HSI and LiDAR datasets demonstrate the superiority of DCMNet over state-of-the-art methods. Our code will be available at https://github.com/oucailab/DCMNet.
Image Gradient-Aided Photometric Stereo Network
Dec 16, 2024Photometric stereo (PS) endeavors to ascertain surface normals using shading clues from photometric images under various illuminations. Recent deep learning-based PS methods often overlook the complexity of object surfaces. These neural network models, which exclusively rely on photometric images for training, often produce blurred results in high-frequency regions characterized by local discontinuities, such as wrinkles and edges with significant gradient changes. To address this, we propose the Image Gradient-Aided Photometric Stereo Network (IGA-PSN), a dual-branch framework extracting features from both photometric images and their gradients. Furthermore, we incorporate an hourglass regression network along with supervision to regularize normal regression. Experiments on DiLiGenT benchmarks show that IGA-PSN outperforms previous methods in surface normal estimation, achieving a mean angular error of 6.46 while preserving textures and geometric shapes in complex regions.
* 13 pages, 5 figures, published to Springer
A Deep Semantic Segmentation Network with Semantic and Contextual Refinements
Dec 11, 2024



Semantic segmentation is a fundamental task in multimedia processing, which can be used for analyzing, understanding, editing contents of images and videos, among others. To accelerate the analysis of multimedia data, existing segmentation researches tend to extract semantic information by progressively reducing the spatial resolutions of feature maps. However, this approach introduces a misalignment problem when restoring the resolution of high-level feature maps. In this paper, we design a Semantic Refinement Module (SRM) to address this issue within the segmentation network. Specifically, SRM is designed to learn a transformation offset for each pixel in the upsampled feature maps, guided by high-resolution feature maps and neighboring offsets. By applying these offsets to the upsampled feature maps, SRM enhances the semantic representation of the segmentation network, particularly for pixels around object boundaries. Furthermore, a Contextual Refinement Module (CRM) is presented to capture global context information across both spatial and channel dimensions. To balance dimensions between channel and space, we aggregate the semantic maps from all four stages of the backbone to enrich channel context information. The efficacy of these proposed modules is validated on three widely used datasets-Cityscapes, Bdd100K, and ADE20K-demonstrating superior performance compared to state-of-the-art methods. Additionally, this paper extends these modules to a lightweight segmentation network, achieving an mIoU of 82.5% on the Cityscapes validation set with only 137.9 GFLOPs.
A feature refinement module for light-weight semantic segmentation network
Dec 11, 2024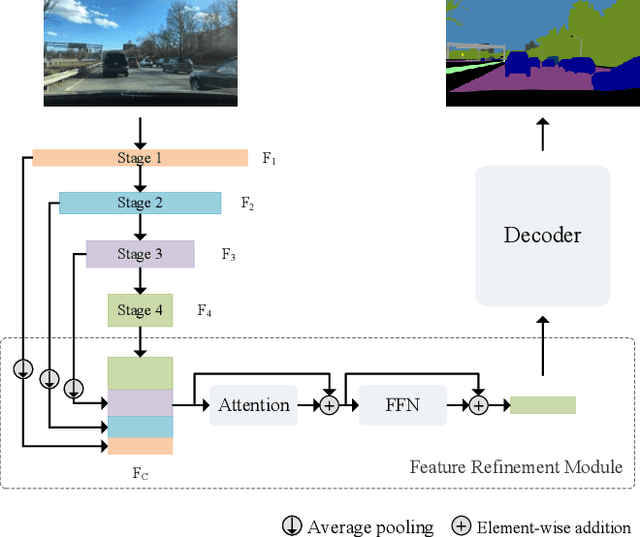
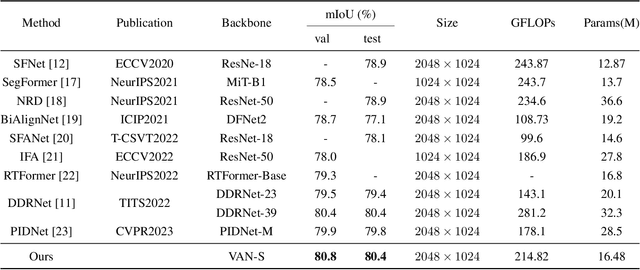
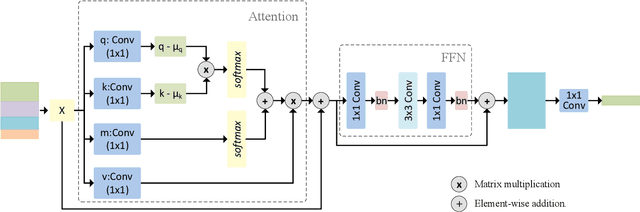
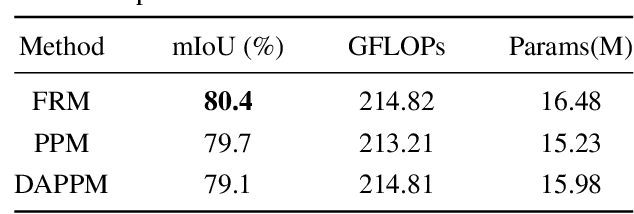
Low computational complexity and high segmentation accuracy are both essential to the real-world semantic segmentation tasks. However, to speed up the model inference, most existing approaches tend to design light-weight networks with a very limited number of parameters, leading to a considerable degradation in accuracy due to the decrease of the representation ability of the networks. To solve the problem, this paper proposes a novel semantic segmentation method to improve the capacity of obtaining semantic information for the light-weight network. Specifically, a feature refinement module (FRM) is proposed to extract semantics from multi-stage feature maps generated by the backbone and capture non-local contextual information by utilizing a transformer block. On Cityscapes and Bdd100K datasets, the experimental results demonstrate that the proposed method achieves a promising trade-off between accuracy and computational cost, especially for Cityscapes test set where 80.4% mIoU is achieved and only 214.82 GFLOPs are required.
Superpixel Cost Volume Excitation for Stereo Matching
Nov 20, 2024In this work, we concentrate on exciting the intrinsic local consistency of stereo matching through the incorporation of superpixel soft constraints, with the objective of mitigating inaccuracies at the boundaries of predicted disparity maps. Our approach capitalizes on the observation that neighboring pixels are predisposed to belong to the same object and exhibit closely similar intensities within the probability volume of superpixels. By incorporating this insight, our method encourages the network to generate consistent probability distributions of disparity within each superpixel, aiming to improve the overall accuracy and coherence of predicted disparity maps. Experimental evalua tions on widely-used datasets validate the efficacy of our proposed approach, demonstrating its ability to assist cost volume-based matching networks in restoring competitive performance.
* 13 pages, 7 figures
Hierarchical Attention and Parallel Filter Fusion Network for Multi-Source Data Classification
Aug 22, 2024Hyperspectral image (HSI) and synthetic aperture radar (SAR) data joint classification is a crucial and yet challenging task in the field of remote sensing image interpretation. However, feature modeling in existing methods is deficient to exploit the abundant global, spectral, and local features simultaneously, leading to sub-optimal classification performance. To solve the problem, we propose a hierarchical attention and parallel filter fusion network for multi-source data classification. Concretely, we design a hierarchical attention module for hyperspectral feature extraction. This module integrates global, spectral, and local features simultaneously to provide more comprehensive feature representation. In addition, we develop parallel filter fusion module which enhances cross-modal feature interactions among different spatial locations in the frequency domain. Extensive experiments on two multi-source remote sensing data classification datasets verify the superiority of our proposed method over current state-of-the-art classification approaches. Specifically, our proposed method achieves 91.44% and 80.51% of overall accuracy (OA) on the respective datasets, highlighting its superior performance.
Exploring Cross-Domain Few-Shot Classification via Frequency-Aware Prompting
Jun 24, 2024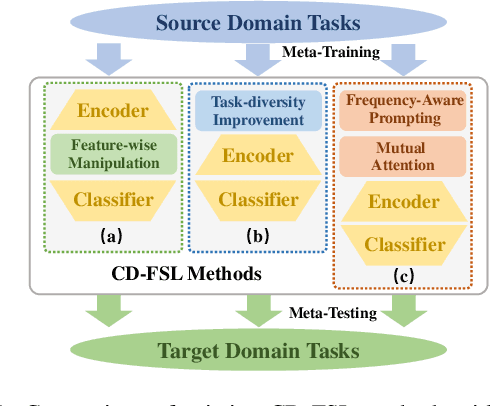
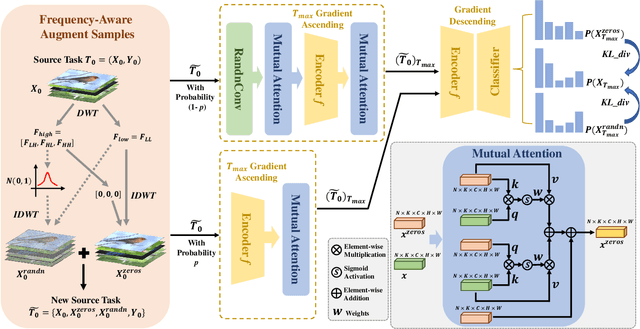
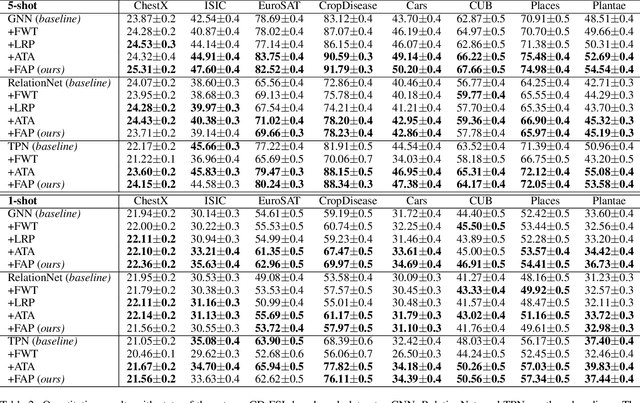
Cross-Domain Few-Shot Learning has witnessed great stride with the development of meta-learning. However, most existing methods pay more attention to learning domain-adaptive inductive bias (meta-knowledge) through feature-wise manipulation or task diversity improvement while neglecting the phenomenon that deep networks tend to rely more on high-frequency cues to make the classification decision, which thus degenerates the robustness of learned inductive bias since high-frequency information is vulnerable and easy to be disturbed by noisy information. Hence in this paper, we make one of the first attempts to propose a Frequency-Aware Prompting method with mutual attention for Cross-Domain Few-Shot classification, which can let networks simulate the human visual perception of selecting different frequency cues when facing new recognition tasks. Specifically, a frequency-aware prompting mechanism is first proposed, in which high-frequency components of the decomposed source image are switched either with normal distribution sampling or zeroing to get frequency-aware augment samples. Then, a mutual attention module is designed to learn generalizable inductive bias under CD-FSL settings. More importantly, the proposed method is a plug-and-play module that can be directly applied to most off-the-shelf CD-FLS methods. Experimental results on CD-FSL benchmarks demonstrate the effectiveness of our proposed method as well as robustly improve the performance of existing CD-FLS methods. Resources at https://github.com/tinkez/FAP_CDFSC.
Dual-Stream Attention Network for Hyperspectral Image Unmixing
Jun 03, 2024



Hyperspectral image (HSI) contains abundant spatial and spectral information, making it highly valuable for unmixing. In this paper, we propose a Dual-Stream Attention Network (DSANet) for HSI unmixing. The endmembers and abundance of a pixel in HSI have high correlations with its adjacent pixels. Therefore, we adopt a "many to one" strategy to estimate the abundance of the central pixel. In addition, we adopt multiview spectral method, dividing spectral bands into multiple partitions with low correlations to estimate abundances. To aggregate the estimated abundances for complementary from the two branches, we design a cross-fusion attention network to enhance valuable information. Extensive experiments have been conducted on two real datasets, which demonstrate the effectiveness of our DSANet.
Sparse Focus Network for Multi-Source Remote Sensing Data Classification
Jun 03, 2024



Multi-source remote sensing data classification has emerged as a prominent research topic with the advancement of various sensors. Existing multi-source data classification methods are susceptible to irrelevant information interference during multi-source feature extraction and fusion. To solve this issue, we propose a sparse focus network for multi-source data classification. Sparse attention is employed in Transformer block for HSI and SAR/LiDAR feature extraction, thereby the most useful self-attention values are maintained for better feature aggregation. Furthermore, cross-attention is used to enhance multi-source feature interactions, and further improves the efficiency of cross-modal feature fusion. Experimental results on the Berlin and Houston2018 datasets highlight the effectiveness of SF-Net, outperforming existing state-of-the-art methods.