 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Imaging-X: A Survey of 1000+ Open-Access Medical Imaging Datasets for Foundation Model Development
Mar 29, 2026Foundation models have demonstrated remarkable success across diverse domains and tasks, primarily due to the thrive of large-scale, diverse, and high-quality datasets. However, in the field of medical imaging, the curation and assembling of such medical datasets are highly challenging due to the reliance on clinical expertise and strict ethical and privacy constraints, resulting in a scarcity of large-scale unified medical datasets and hindering the development of powerful medical foundation models. In this work, we present the largest survey to date of medical image datasets, covering over 1,000 open-access datasets with a systematic catalog of their modalities, tasks, anatomies, annotations, limitations, and potential for integration. Our analysis exposes a landscape that is modest in scale, fragmented across narrowly scoped tasks, and unevenly distributed across organs and modalities, which in turn limits the utility of existing medical image datasets for developing versatile and robust medical foundation models. To turn fragmentation into scale, we propose a metadata-driven fusion paradigm (MDFP) that integrates public datasets with shared modalities or tasks, thereby transforming multiple small data silos into larger, more coherent resources. Building on MDFP, we release an interactive discovery portal that enables end-to-end, automated medical image dataset integration, and compile all surveyed datasets into a unified, structured table that clearly summarizes their key characteristics and provides reference links, offering the community an accessible and comprehensive repository. By charting the current terrain and offering a principled path to dataset consolidation, our survey provides a practical roadmap for scaling medical imaging corpora, supporting faster data discovery, more principled dataset creation, and more capable medical foundation models.
LoD-Loc v3: Generalized Aerial Localization in Dense Cities using Instance Silhouette Alignment
Mar 20, 2026We present LoD-Loc v3, a novel method for generalized aerial visual localization in dense urban environments. While prior work LoD-Loc v2 achieves localization through semantic building silhouette alignment with low-detail city models, it suffers from two key limitations: poor cross-scene generalization and frequent failure in dense building scenes. Our method addresses these challenges through two key innovations. First, we develop a new synthetic data generation pipeline that produces InsLoD-Loc - the largest instance segmentation dataset for aerial imagery to date, comprising 100k images with precise instance building annotations. This enables trained models to exhibit remarkable zero-shot generalization capability. Second, we reformulate the localization paradigm by shifting from semantic to instance silhouette alignment, which significantly reduces pose estimation ambiguity in dense scenes. Extensive experiments demonstrate that LoD-Loc v3 outperforms existing state-of-the-art (SOTA) baselines, achieving superior performance in both cross-scene and dense urban scenarios with a large margin. The project is available at https://nudt-sawlab.github.io/LoD-Locv3/.
PivotAttack: Rethinking the Search Trajectory in Hard-Label Text Attacks via Pivot Words
Mar 11, 2026Existing hard-label text attacks often rely on inefficient "outside-in" strategies that traverse vast search spaces. We propose PivotAttack, a query-efficient "inside-out" framework. It employs a Multi-Armed Bandit algorithm to identify Pivot Sets-combinatorial token groups acting as prediction anchors-and strategically perturbs them to induce label flips. This approach captures inter-word dependencies and minimizes query costs. Extensive experiments across traditional models and Large Language Models demonstrate that PivotAttack consistently outperforms state-of-the-art baselines in both Attack Success Rate and query efficiency.
Human-in-Context: Unified Cross-Domain 3D Human Motion Modeling via In-Context Learning
Aug 14, 2025This paper aims to model 3D human motion across domains, where a single model is expected to handle multiple modalities, tasks, and datasets. Existing cross-domain models often rely on domain-specific components and multi-stage training, which limits their practicality and scalability. To overcome these challenges, we propose a new setting to train a unified cross-domain model through a single process, eliminating the need for domain-specific components and multi-stage training. We first introduce Pose-in-Context (PiC), which leverages in-context learning to create a pose-centric cross-domain model. While PiC generalizes across multiple pose-based tasks and datasets, it encounters difficulties with modality diversity, prompting strategy, and contextual dependency handling. We thus propose Human-in-Context (HiC), an extension of PiC that broadens generalization across modalities, tasks, and datasets. HiC combines pose and mesh representations within a unified framework, expands task coverage, and incorporates larger-scale datasets. Additionally, HiC introduces a max-min similarity prompt sampling strategy to enhance generalization across diverse domains and a network architecture with dual-branch context injection for improved handling of contextual dependencies. Extensive experimental results show that HiC performs better than PiC in terms of generalization, data scale, and performance across a wide range of domains. These results demonstrate the potential of HiC for building a unified cross-domain 3D human motion model with improved flexibility and scalability. The source codes and models are available at https://github.com/BradleyWang0416/Human-in-Context.
Designing conflict-based communicative tasks in Teaching Chinese as a Foreign Language with ChatGPT
Jun 10, 2025In developing the teaching program for a course in Oral Expression in Teaching Chinese as a Foreign Language at the university level, the teacher designs communicative tasks based on conflicts to encourage learners to engage in interactive dynamics and develop their oral interaction skills. During the design of these tasks, the teacher uses ChatGPT to assist in finalizing the program. This article aims to present the key characteristics of the interactions between the teacher and ChatGPT during this program development process, as well as to examine the use of ChatGPT and its impacts in this specific context.
* in French language
Automatic Pruning via Structured Lasso with Class-wise Information
Feb 13, 2025Most pruning methods concentrate on unimportant filters of neural networks. However, they face the loss of statistical information due to a lack of consideration for class-wise data. In this paper, from the perspective of leveraging precise class-wise information for model pruning, we utilize structured lasso with guidance from Information Bottleneck theory. Our approach ensures that statistical information is retained during the pruning process. With these techniques, we introduce two innovative adaptive network pruning schemes: sparse graph-structured lasso pruning with Information Bottleneck (\textbf{sGLP-IB}) and sparse tree-guided lasso pruning with Information Bottleneck (\textbf{sTLP-IB}). The key aspect is pruning model filters using sGLP-IB and sTLP-IB to better capture class-wise relatedness. Compared to multiple state-of-the-art methods, our approaches demonstrate superior performance across three datasets and six model architectures in extensive experiments. For instance, using the VGG16 model on the CIFAR-10 dataset, we achieve a parameter reduction of 85%, a decrease in FLOPs by 61%, and maintain an accuracy of 94.10% (0.14% higher than the original model); we reduce the parameters by 55% with the accuracy at 76.12% using the ResNet architecture on ImageNet (only drops 0.03%). In summary, we successfully reduce model size and computational resource usage while maintaining accuracy. Our codes are at https://anonymous.4open.science/r/IJCAI-8104.
One-shot Federated Learning Methods: A Practical Guide
Feb 13, 2025One-shot Federated Learning (OFL) is a distributed machine learning paradigm that constrains client-server communication to a single round, addressing privacy and communication overhead issues associated with multiple rounds of data exchange in traditional Federated Learning (FL). OFL demonstrates the practical potential for integration with future approaches that require collaborative training models, such as large language models (LLMs). However, current OFL methods face two major challenges: data heterogeneity and model heterogeneity, which result in subpar performance compared to conventional FL methods. Worse still, despite numerous studies addressing these limitations, a comprehensive summary is still lacking. To address these gaps, this paper presents a systematic analysis of the challenges faced by OFL and thoroughly reviews the current methods. We also offer an innovative categorization method and analyze the trade-offs of various techniques. Additionally, we discuss the most promising future directions and the technologies that should be integrated into the OFL field. This work aims to provide guidance and insights for future research.
Implementation of an Asymmetric Adjusted Activation Function for Class Imbalance Credit Scoring
Jan 21, 2025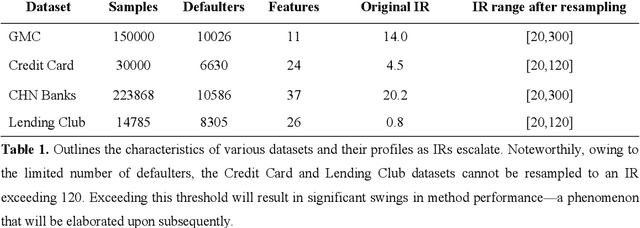

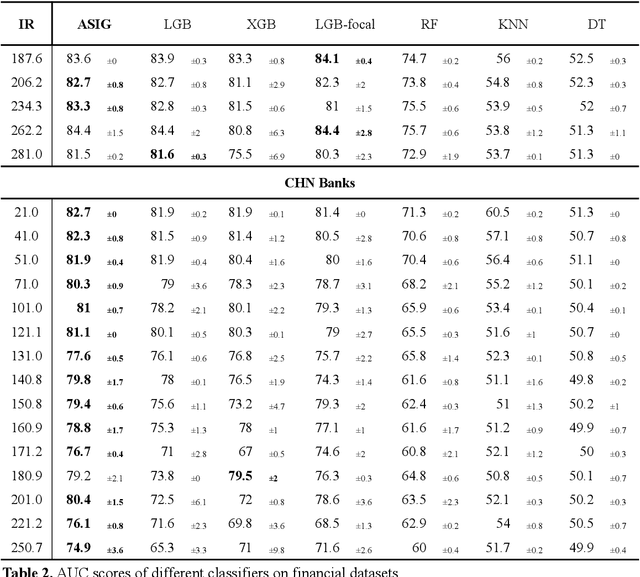

Credit scoring is a systematic approach to evaluate a borrower's probability of default (PD) on a bank loan. The data associated with such scenarios are characteristically imbalanced, complicating binary classification owing to the often-underestimated cost of misclassification during the classifier's learning process. Considering the high imbalance ratio (IR) of these datasets, we introduce an innovative yet straightforward optimized activation function by incorporating an IR-dependent asymmetric adjusted factor embedded Sigmoid activation function (ASIG). The embedding of ASIG makes the sensitive margin of the Sigmoid function auto-adjustable, depending on the imbalance nature of the datasets distributed, thereby giving the activation function an asymmetric characteristic that prevents the underrepresentation of the minority class (positive samples) during the classifier's learning process. The experimental results show that the ASIG-embedded-classifier outperforms traditional classifiers on datasets across wide-ranging IRs in the downstream credit-scoring task. The algorithm also shows robustness and stability, even when the IR is ultra-high. Therefore, the algorithm provides a competitive alternative in the financial industry, especially in credit scoring, possessing the ability to effectively process highly imbalanced distribution data.
Class-Imbalanced-Aware Adaptive Dataset Distillation for Scalable Pretrained Model on Credit Scoring
Jan 18, 2025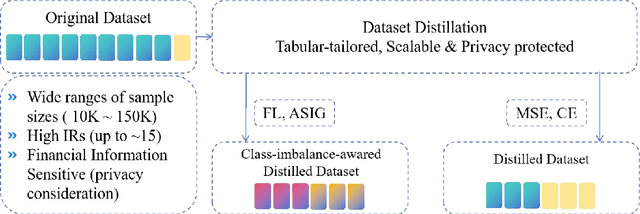
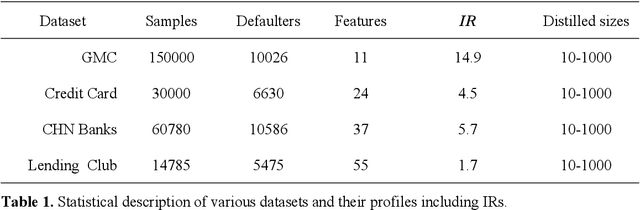
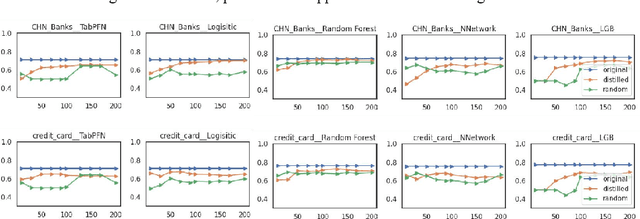
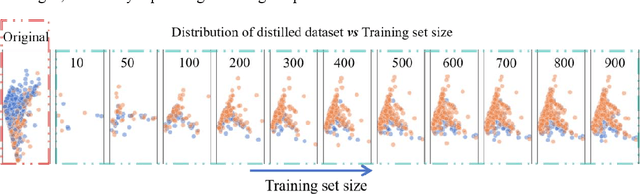
The advent of artificial intelligence has significantly enhanced credit scoring technologies. Despite the remarkable efficacy of advanced deep learning models, mainstream adoption continues to favor tree-structured models due to their robust predictive performance on tabular data. Although pretrained models have seen considerable development, their application within the financial realm predominantly revolves around question-answering tasks and the use of such models for tabular-structured credit scoring datasets remains largely unexplored. Tabular-oriented large models, such as TabPFN, has made the application of large models in credit scoring feasible, albeit can only processing with limited sample sizes. This paper provides a novel framework to combine tabular-tailored dataset distillation technique with the pretrained model, empowers the scalability for TabPFN. Furthermore, though class imbalance distribution is the common nature in financial datasets, its influence during dataset distillation has not been explored. We thus integrate the imbalance-aware techniques during dataset distillation, resulting in improved performance in financial datasets (e.g., a 2.5% enhancement in AUC). This study presents a novel framework for scaling up the application of large pretrained models on financial tabular datasets and offers a comparative analysis of the influence of class imbalance on the dataset distillation process. We believe this approach can broaden the applications and downstream tasks of large models in the financial domain.
Image Gradient-Aided Photometric Stereo Network
Dec 16, 2024Photometric stereo (PS) endeavors to ascertain surface normals using shading clues from photometric images under various illuminations. Recent deep learning-based PS methods often overlook the complexity of object surfaces. These neural network models, which exclusively rely on photometric images for training, often produce blurred results in high-frequency regions characterized by local discontinuities, such as wrinkles and edges with significant gradient changes. To address this, we propose the Image Gradient-Aided Photometric Stereo Network (IGA-PSN), a dual-branch framework extracting features from both photometric images and their gradients. Furthermore, we incorporate an hourglass regression network along with supervision to regularize normal regression. Experiments on DiLiGenT benchmarks show that IGA-PSN outperforms previous methods in surface normal estimation, achieving a mean angular error of 6.46 while preserving textures and geometric shapes in complex regions.
* 13 pages, 5 figures, published to Springer