 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImplementation of an Asymmetric Adjusted Activation Function for Class Imbalance Credit Scoring
Jan 21, 2025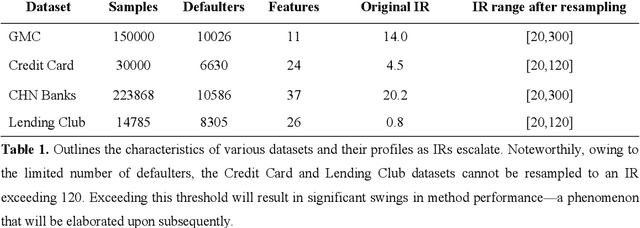

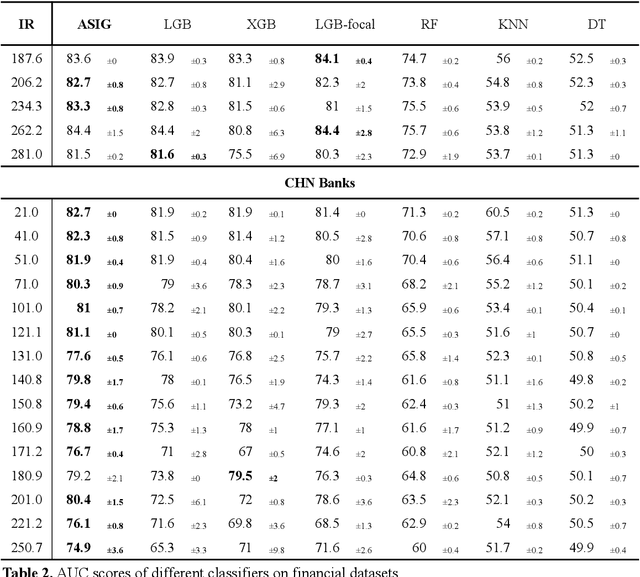

Credit scoring is a systematic approach to evaluate a borrower's probability of default (PD) on a bank loan. The data associated with such scenarios are characteristically imbalanced, complicating binary classification owing to the often-underestimated cost of misclassification during the classifier's learning process. Considering the high imbalance ratio (IR) of these datasets, we introduce an innovative yet straightforward optimized activation function by incorporating an IR-dependent asymmetric adjusted factor embedded Sigmoid activation function (ASIG). The embedding of ASIG makes the sensitive margin of the Sigmoid function auto-adjustable, depending on the imbalance nature of the datasets distributed, thereby giving the activation function an asymmetric characteristic that prevents the underrepresentation of the minority class (positive samples) during the classifier's learning process. The experimental results show that the ASIG-embedded-classifier outperforms traditional classifiers on datasets across wide-ranging IRs in the downstream credit-scoring task. The algorithm also shows robustness and stability, even when the IR is ultra-high. Therefore, the algorithm provides a competitive alternative in the financial industry, especially in credit scoring, possessing the ability to effectively process highly imbalanced distribution data.
Class-Imbalanced-Aware Adaptive Dataset Distillation for Scalable Pretrained Model on Credit Scoring
Jan 18, 2025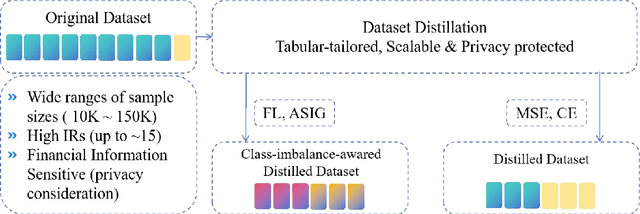
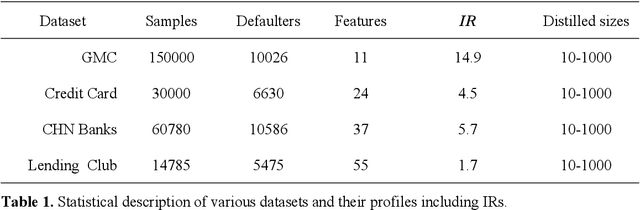
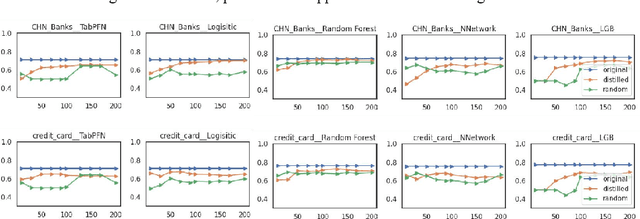
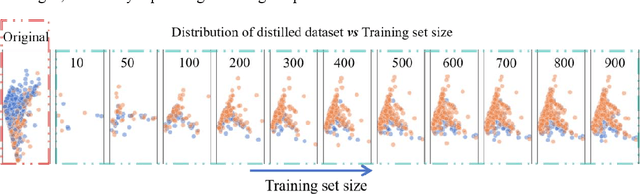
The advent of artificial intelligence has significantly enhanced credit scoring technologies. Despite the remarkable efficacy of advanced deep learning models, mainstream adoption continues to favor tree-structured models due to their robust predictive performance on tabular data. Although pretrained models have seen considerable development, their application within the financial realm predominantly revolves around question-answering tasks and the use of such models for tabular-structured credit scoring datasets remains largely unexplored. Tabular-oriented large models, such as TabPFN, has made the application of large models in credit scoring feasible, albeit can only processing with limited sample sizes. This paper provides a novel framework to combine tabular-tailored dataset distillation technique with the pretrained model, empowers the scalability for TabPFN. Furthermore, though class imbalance distribution is the common nature in financial datasets, its influence during dataset distillation has not been explored. We thus integrate the imbalance-aware techniques during dataset distillation, resulting in improved performance in financial datasets (e.g., a 2.5% enhancement in AUC). This study presents a novel framework for scaling up the application of large pretrained models on financial tabular datasets and offers a comparative analysis of the influence of class imbalance on the dataset distillation process. We believe this approach can broaden the applications and downstream tasks of large models in the financial domain.