 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebate-Feedback: A Multi-Agent Framework for Efficient Legal Judgment Prediction
Apr 07, 2025The use of AI in legal analysis and prediction (LegalAI) has gained widespread attention, with past research focusing on retrieval-based methods and fine-tuning large models. However, these approaches often require large datasets and underutilize the capabilities of modern large language models (LLMs). In this paper, inspired by the debate phase of real courtroom trials, we propose a novel legal judgment prediction model based on the Debate-Feedback architecture, which integrates LLM multi-agent debate and reliability evaluation models. Unlike traditional methods, our model achieves significant improvements in efficiency by minimizing the need for large historical datasets, thus offering a lightweight yet robust solution. Comparative experiments show that it outperforms several general-purpose and domain-specific legal models, offering a dynamic reasoning process and a promising direction for future LegalAI research.
Humanity's Last Exam
Jan 24, 2025Benchmarks are important tools for tracking the rapid advancements in large language model (LLM) capabilities. However, benchmarks are not keeping pace in difficulty: LLMs now achieve over 90\% accuracy on popular benchmarks like MMLU, limiting informed measurement of state-of-the-art LLM capabilities. In response, we introduce Humanity's Last Exam (HLE), a multi-modal benchmark at the frontier of human knowledge, designed to be the final closed-ended academic benchmark of its kind with broad subject coverage. HLE consists of 3,000 questions across dozens of subjects, including mathematics, humanities, and the natural sciences. HLE is developed globally by subject-matter experts and consists of multiple-choice and short-answer questions suitable for automated grading. Each question has a known solution that is unambiguous and easily verifiable, but cannot be quickly answered via internet retrieval. State-of-the-art LLMs demonstrate low accuracy and calibration on HLE, highlighting a significant gap between current LLM capabilities and the expert human frontier on closed-ended academic questions. To inform research and policymaking upon a clear understanding of model capabilities, we publicly release HLE at https://lastexam.ai.
Implementation of an Asymmetric Adjusted Activation Function for Class Imbalance Credit Scoring
Jan 21, 2025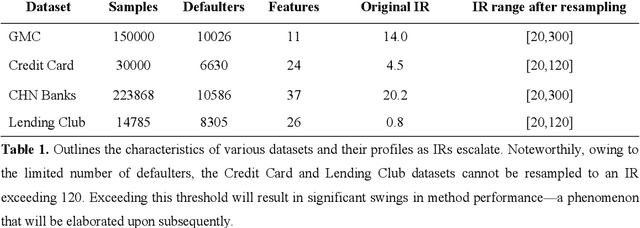

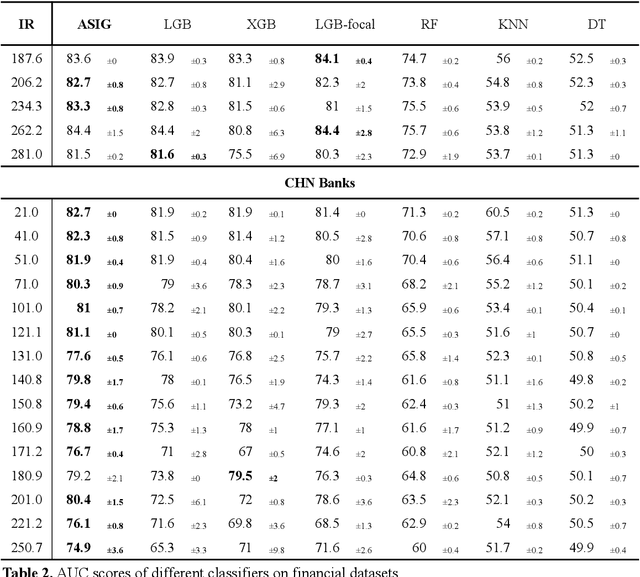

Credit scoring is a systematic approach to evaluate a borrower's probability of default (PD) on a bank loan. The data associated with such scenarios are characteristically imbalanced, complicating binary classification owing to the often-underestimated cost of misclassification during the classifier's learning process. Considering the high imbalance ratio (IR) of these datasets, we introduce an innovative yet straightforward optimized activation function by incorporating an IR-dependent asymmetric adjusted factor embedded Sigmoid activation function (ASIG). The embedding of ASIG makes the sensitive margin of the Sigmoid function auto-adjustable, depending on the imbalance nature of the datasets distributed, thereby giving the activation function an asymmetric characteristic that prevents the underrepresentation of the minority class (positive samples) during the classifier's learning process. The experimental results show that the ASIG-embedded-classifier outperforms traditional classifiers on datasets across wide-ranging IRs in the downstream credit-scoring task. The algorithm also shows robustness and stability, even when the IR is ultra-high. Therefore, the algorithm provides a competitive alternative in the financial industry, especially in credit scoring, possessing the ability to effectively process highly imbalanced distribution data.
Class-Imbalanced-Aware Adaptive Dataset Distillation for Scalable Pretrained Model on Credit Scoring
Jan 18, 2025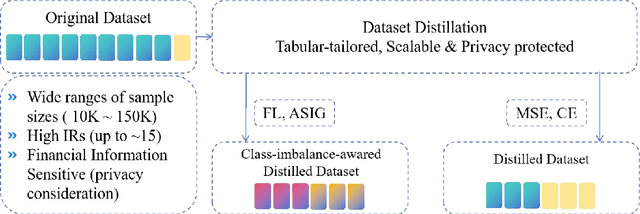
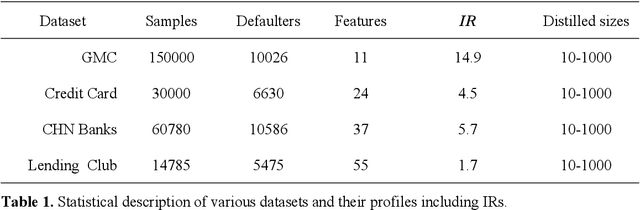
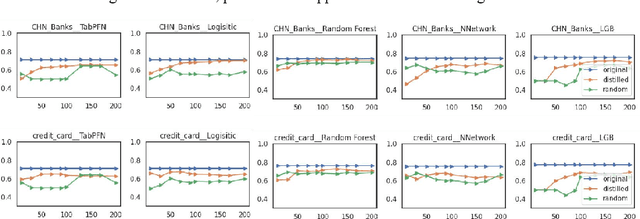
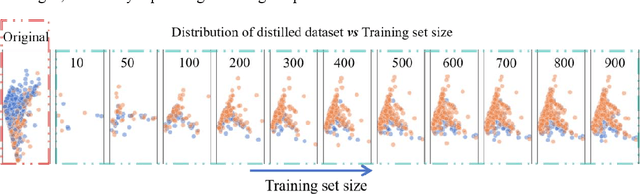
The advent of artificial intelligence has significantly enhanced credit scoring technologies. Despite the remarkable efficacy of advanced deep learning models, mainstream adoption continues to favor tree-structured models due to their robust predictive performance on tabular data. Although pretrained models have seen considerable development, their application within the financial realm predominantly revolves around question-answering tasks and the use of such models for tabular-structured credit scoring datasets remains largely unexplored. Tabular-oriented large models, such as TabPFN, has made the application of large models in credit scoring feasible, albeit can only processing with limited sample sizes. This paper provides a novel framework to combine tabular-tailored dataset distillation technique with the pretrained model, empowers the scalability for TabPFN. Furthermore, though class imbalance distribution is the common nature in financial datasets, its influence during dataset distillation has not been explored. We thus integrate the imbalance-aware techniques during dataset distillation, resulting in improved performance in financial datasets (e.g., a 2.5% enhancement in AUC). This study presents a novel framework for scaling up the application of large pretrained models on financial tabular datasets and offers a comparative analysis of the influence of class imbalance on the dataset distillation process. We believe this approach can broaden the applications and downstream tasks of large models in the financial domain.
PNeRFLoc: Visual Localization with Point-based Neural Radiance Fields
Dec 17, 2023
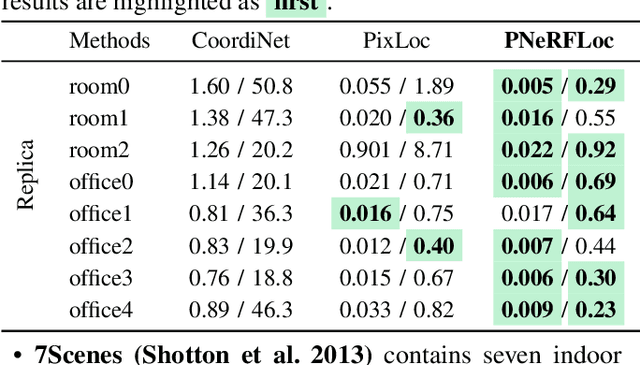

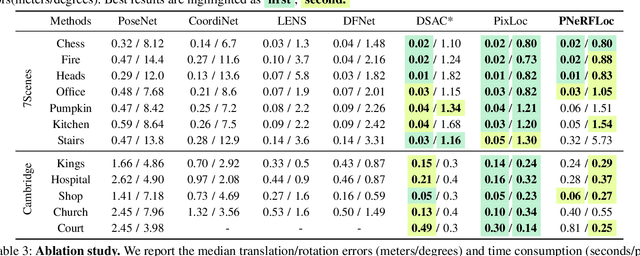
Due to the ability to synthesize high-quality novel views, Neural Radiance Fields (NeRF) have been recently exploited to improve visual localization in a known environment. However, the existing methods mostly utilize NeRFs for data augmentation to improve the regression model training, and the performance on novel viewpoints and appearances is still limited due to the lack of geometric constraints. In this paper, we propose a novel visual localization framework, \ie, PNeRFLoc, based on a unified point-based representation. On the one hand, PNeRFLoc supports the initial pose estimation by matching 2D and 3D feature points as traditional structure-based methods; on the other hand, it also enables pose refinement with novel view synthesis using rendering-based optimization. Specifically, we propose a novel feature adaption module to close the gaps between the features for visual localization and neural rendering. To improve the efficacy and efficiency of neural rendering-based optimization, we also develop an efficient rendering-based framework with a warping loss function. Furthermore, several robustness techniques are developed to handle illumination changes and dynamic objects for outdoor scenarios. Experiments demonstrate that PNeRFLoc performs the best on synthetic data when the NeRF model can be well learned and performs on par with the SOTA method on the visual localization benchmark datasets.
CP-SLAM: Collaborative Neural Point-based SLAM System
Nov 14, 2023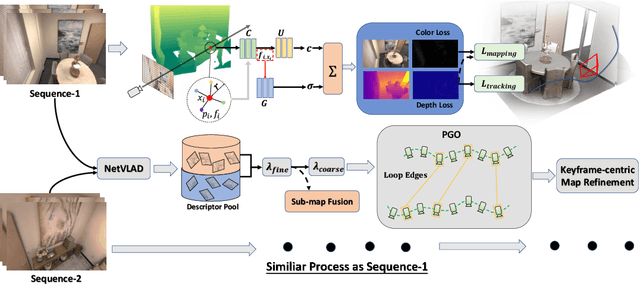
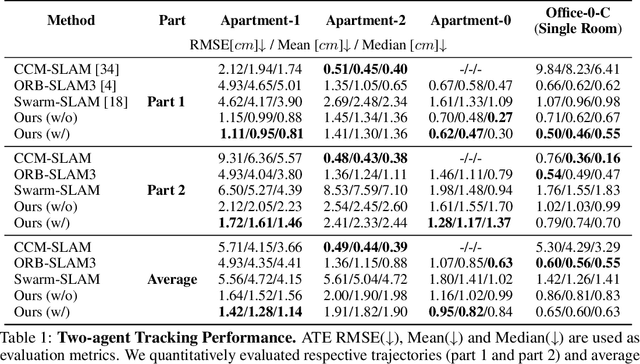
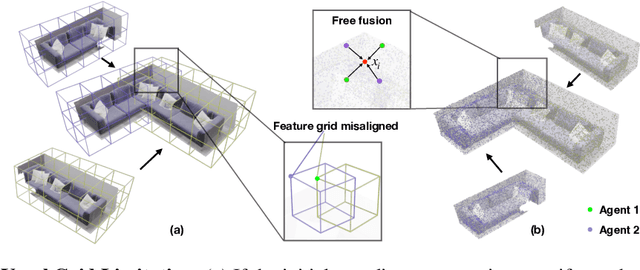
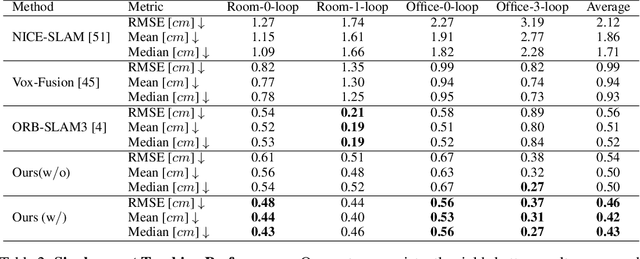
This paper presents a collaborative implicit neural simultaneous localization and mapping (SLAM) system with RGB-D image sequences, which consists of complete front-end and back-end modules including odometry, loop detection, sub-map fusion, and global refinement. In order to enable all these modules in a unified framework, we propose a novel neural point based 3D scene representation in which each point maintains a learnable neural feature for scene encoding and is associated with a certain keyframe. Moreover, a distributed-to-centralized learning strategy is proposed for the collaborative implicit SLAM to improve consistency and cooperation. A novel global optimization framework is also proposed to improve the system accuracy like traditional bundle adjustment. Experiments on various datasets demonstrate the superiority of the proposed method in both camera tracking and mapping.