 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgora: Toward Autonomous Bug Detection in Production-Level Consensus Protocols with LLM Agents
May 28, 2026Consensus protocols form the backbone of distributed systems and blockchains, where implementation bugs can cause data corruption and financial losses. While LLM-based approaches show promise in code analysis, they struggle with deep protocol-level logic bugs involving complex state-dependent behaviors across multiple execution stages. We present Agora, a domain-aware multi-agent framework that integrates hypothesis-driven testing with LLM capabilities for systematic protocol verification. Agora employs specialized agents that collaboratively explore protocol state spaces, synthesize attack scenarios using domain-specific constraints, and validate findings through iterative refinement. This explicit role separation enables reasoning about global protocol invariants beyond single-function code analysis. We evaluate Agora on four consensus implementations (Raft, EPaxos, HotStuff, BullShark) using four state-of-the-art LLMs. Agora discovers 15 previously unknown protocol-level logic bugs that violate safety properties, while existing LLM-based agents fail to detect any such protocol-level logic bugs. Our results demonstrate that domain-aware multi-agent collaboration is essential for detecting deep logic bugs in complex protocols.
ED-ViT: Splitting Vision Transformer for Distributed Inference on Edge Devices
Oct 15, 2024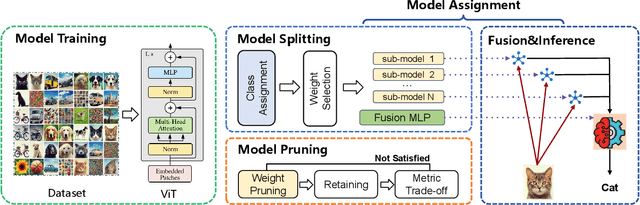

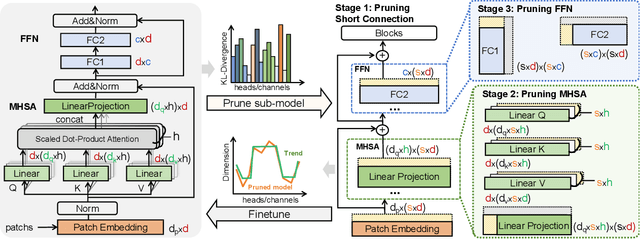
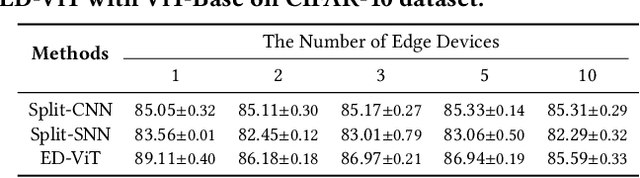
Deep learning models are increasingly deployed on resource-constrained edge devices for real-time data analytics. In recent years, Vision Transformer models and their variants have demonstrated outstanding performance across various computer vision tasks. However, their high computational demands and inference latency pose significant challenges for model deployment on resource-constraint edge devices. To address this issue, we propose a novel Vision Transformer splitting framework, ED-ViT, designed to execute complex models across multiple edge devices efficiently. Specifically, we partition Vision Transformer models into several sub-models, where each sub-model is tailored to handle a specific subset of data classes. To further minimize computation overhead and inference latency, we introduce a class-wise pruning technique that reduces the size of each sub-model. We conduct extensive experiments on five datasets with three model structures, demonstrating that our approach significantly reduces inference latency on edge devices and achieves a model size reduction of up to 28.9 times and 34.1 times, respectively, while maintaining test accuracy comparable to the original Vision Transformer. Additionally, we compare ED-ViT with two state-of-the-art methods that deploy CNN and SNN models on edge devices, evaluating accuracy, inference time, and overall model size. Our comprehensive evaluation underscores the effectiveness of the proposed ED-ViT framework.
BENCHIP: Benchmarking Intelligence Processors
Nov 25, 2017
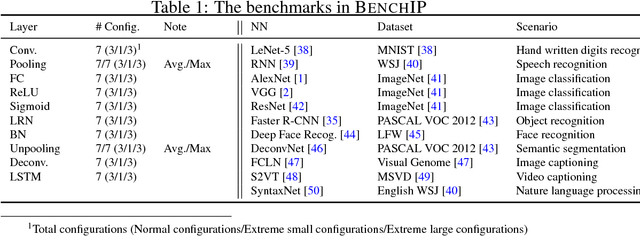
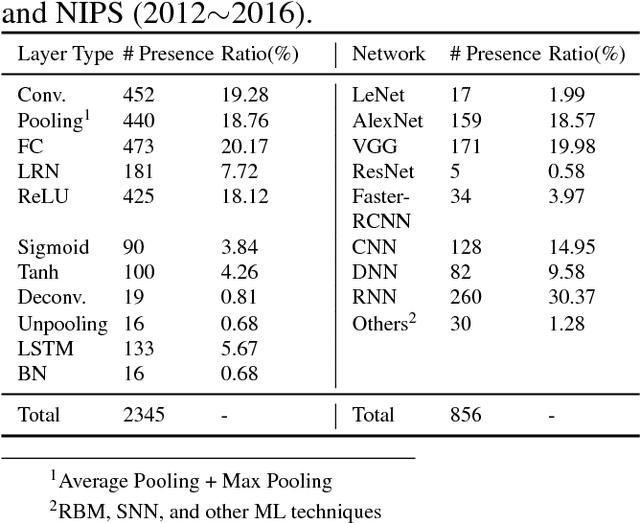
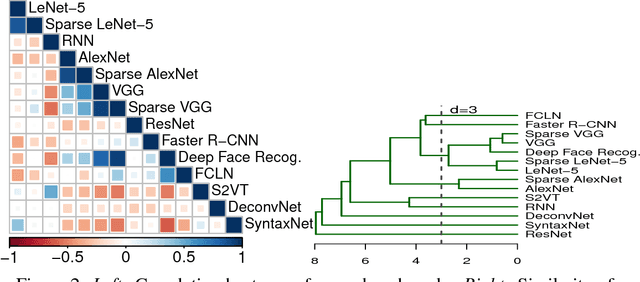
The increasing attention on deep learning has tremendously spurred the design of intelligence processing hardware. The variety of emerging intelligence processors requires standard benchmarks for fair comparison and system optimization (in both software and hardware). However, existing benchmarks are unsuitable for benchmarking intelligence processors due to their non-diversity and nonrepresentativeness. Also, the lack of a standard benchmarking methodology further exacerbates this problem. In this paper, we propose BENCHIP, a benchmark suite and benchmarking methodology for intelligence processors. The benchmark suite in BENCHIP consists of two sets of benchmarks: microbenchmarks and macrobenchmarks. The microbenchmarks consist of single-layer networks. They are mainly designed for bottleneck analysis and system optimization. The macrobenchmarks contain state-of-the-art industrial networks, so as to offer a realistic comparison of different platforms. We also propose a standard benchmarking methodology built upon an industrial software stack and evaluation metrics that comprehensively reflect the various characteristics of the evaluated intelligence processors. BENCHIP is utilized for evaluating various hardware platforms, including CPUs, GPUs, and accelerators. BENCHIP will be open-sourced soon.