 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMLPerf Inference Benchmark
Nov 06, 2019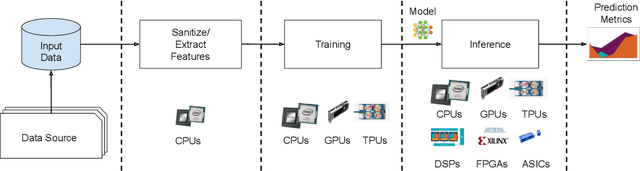
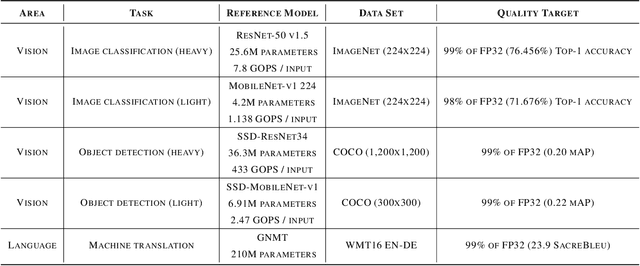
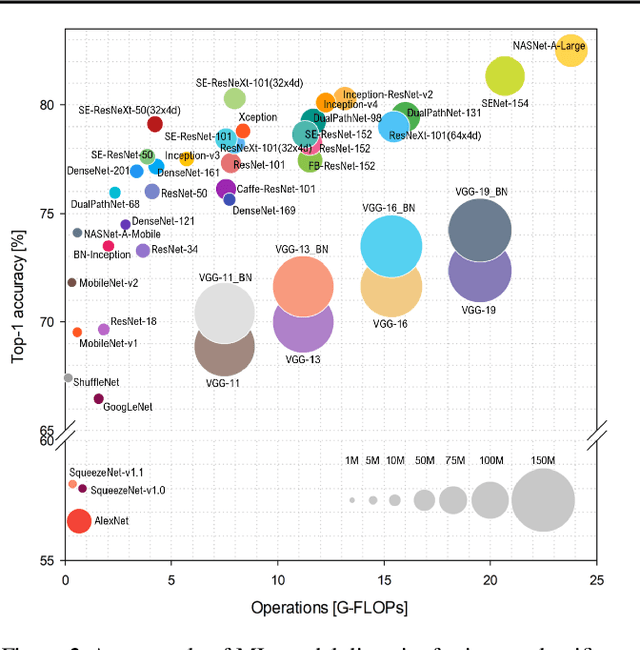
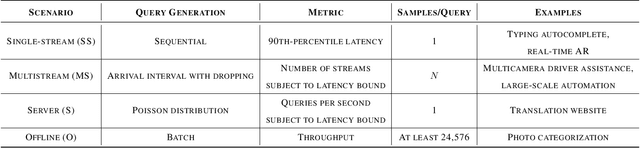
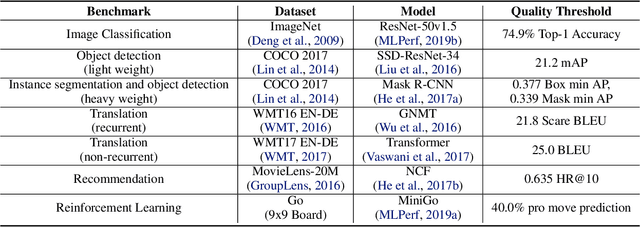
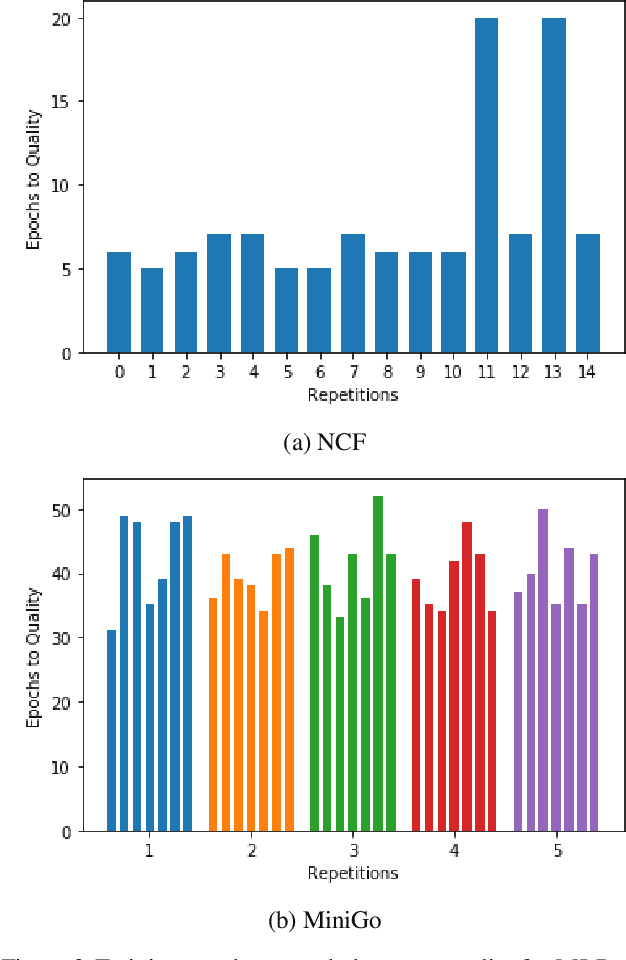
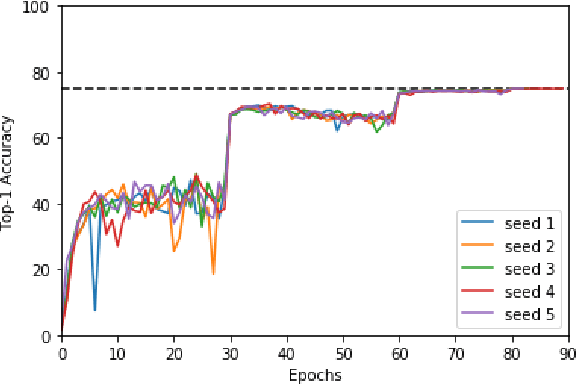
Machine-learning (ML) hardware and software system demand is burgeoning. Driven by ML applications, the number of different ML inference systems has exploded. Over 100 organizations are building ML inference chips, and the systems that incorporate existing models span at least three orders of magnitude in power consumption and four orders of magnitude in performance; they range from embedded devices to data-center solutions. Fueling the hardware are a dozen or more software frameworks and libraries. The myriad combinations of ML hardware and ML software make assessing ML-system performance in an architecture-neutral, representative, and reproducible manner challenging. There is a clear need for industry-wide standard ML benchmarking and evaluation criteria. MLPerf Inference answers that call. Driven by more than 30 organizations as well as more than 200 ML engineers and practitioners, MLPerf implements a set of rules and practices to ensure comparability across systems with wildly differing architectures. In this paper, we present the method and design principles of the initial MLPerf Inference release. The first call for submissions garnered more than 600 inference-performance measurements from 14 organizations, representing over 30 systems that show a range of capabilities.
MLPerf Training Benchmark
Oct 30, 2019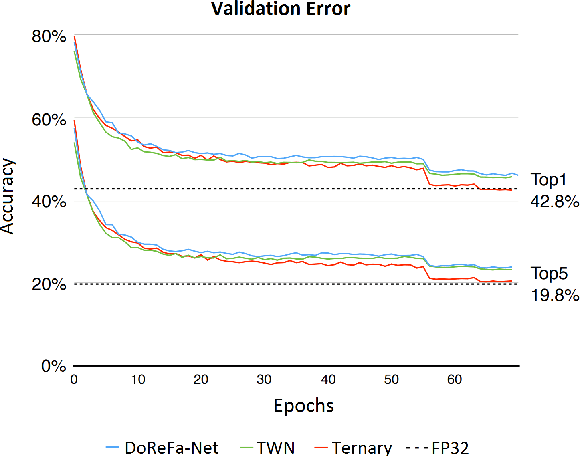
Machine learning is experiencing an explosion of software and hardware solutions, and needs industry-standard performance benchmarks to drive design and enable competitive evaluation. However, machine learning training presents a number of unique challenges to benchmarking that do not exist in other domains: (1) some optimizations that improve training throughput actually increase time to solution, (2) training is stochastic and time to solution has high variance, and (3) the software and hardware systems are so diverse that they cannot be fairly benchmarked with the same binary, code, or even hyperparameters. We present MLPerf, a machine learning benchmark that overcomes these challenges. We quantitatively evaluate the efficacy of MLPerf in driving community progress on performance and scalability across two rounds of results from multiple vendors.
AI Matrix: A Deep Learning Benchmark for Alibaba Data Centers
Sep 23, 2019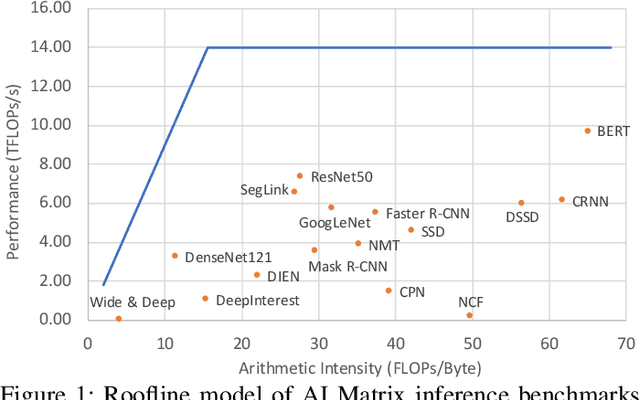
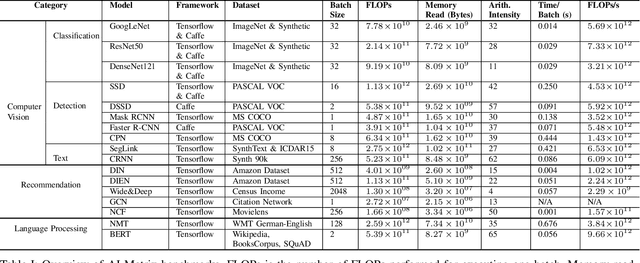
Alibaba has China's largest e-commerce platform. To support its diverse businesses, Alibaba has its own large-scale data centers providing the computing foundation for a wide variety of software applications. Among these applications, deep learning (DL) has been playing an important role in delivering services like image recognition, objection detection, text recognition, recommendation, and language processing. To build more efficient data centers that deliver higher performance for these DL applications, it is important to understand their computational needs and use that information to guide the design of future computing infrastructure. An effective way to achieve this is through benchmarks that can fully represent Alibaba's DL applications.
Across-Stack Profiling and Characterization of Machine Learning Models on GPUs
Aug 19, 2019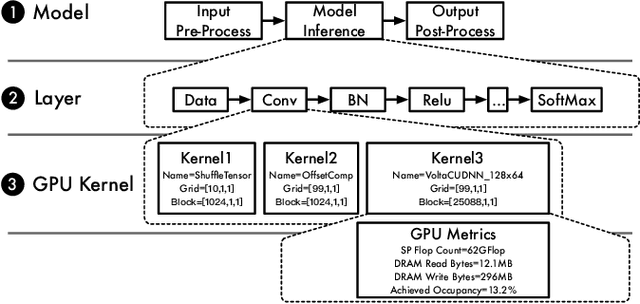
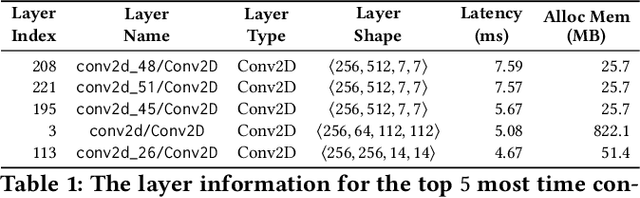
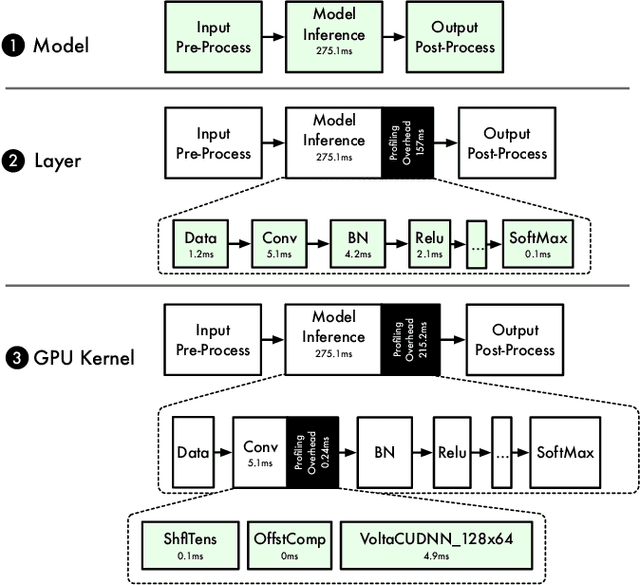

The world sees a proliferation of machine learning/deep learning (ML) models and their wide adoption in different application domains recently. This has made the profiling and characterization of ML models an increasingly pressing task for both hardware designers and system providers, as they would like to offer the best possible computing system to serve ML models with the desired latency, throughput, and energy requirements while maximizing resource utilization. Such an endeavor is challenging as the characteristics of an ML model depend on the interplay between the model, framework, system libraries, and the hardware (or the HW/SW stack). A thorough characterization requires understanding the behavior of the model execution across the HW/SW stack levels. Existing profiling tools are disjoint, however, and only focus on profiling within a particular level of the stack. This paper proposes a leveled profiling design that leverages existing profiling tools to perform across-stack profiling. The design does so in spite of the profiling overheads incurred from the profiling providers. We coupled the profiling capability with an automatic analysis pipeline to systematically characterize 65 state-of-the-art ML models. Through this characterization, we show that our across-stack profiling solution provides insights (which are difficult to discern otherwise) on the characteristics of ML models, ML frameworks, and GPU hardware.
AI Matrix - Synthetic Benchmarks for DNN
Nov 27, 2018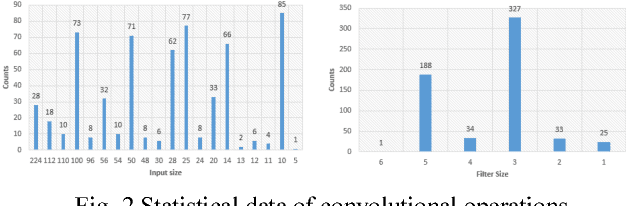
Deep neural network (DNN) architectures, such as convolutional neural networks (CNN), involve heavy computation and require hardware, such as CPU, GPU, and AI accelerators, to provide the massive computing power. With the many varieties of AI hardware prevailing on the market, it is often hard to decide which one is the best to use. Thus, benchmarking AI hardware effectively becomes important and is of great help to select and optimize AI hardware. Unfortunately, there are few AI benchmarks available in both academia and industry. Examples are BenchNN[1], DeepBench[2], and Dawn Bench[3], which are usually a collection of typical real DNN applications. While these benchmarks provide performance comparison across different AI hardware, they suffer from a number of drawbacks. First, they cannot adapt to the emerging changes of DNN algorithms and are fixed once selected. Second, they contain tens to hundreds of applications and take very long time to finish running. Third, they are mainly selected from open sources, which are restricted by copyright and are not representable to proprietary applications. In this work, a synthetic benchmarks framework is firstly proposed to address the above drawbacks of AI benchmarks. Instead of pre-selecting a set of open-sourced benchmarks and running all of them, the synthetic approach generates only a one or few benchmarks that best represent a broad range of applications using profiled workload characteristics data of these applications. Thus, it can adapt to emerging changes of new DNN algorithms by re-profiling new applications and updating itself, greatly reduce benchmark count and running time, and strongly represent DNN applications of interests. The generated benchmarks are called AI Matrix, serving as a performance benchmarks matching the statistical workload characteristics of a combination of applications of interests.
BENCHIP: Benchmarking Intelligence Processors
Nov 25, 2017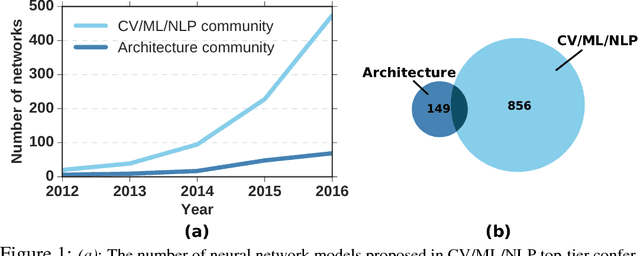
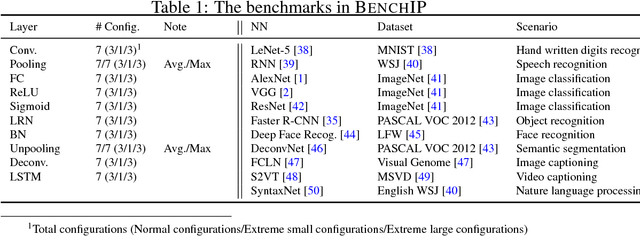
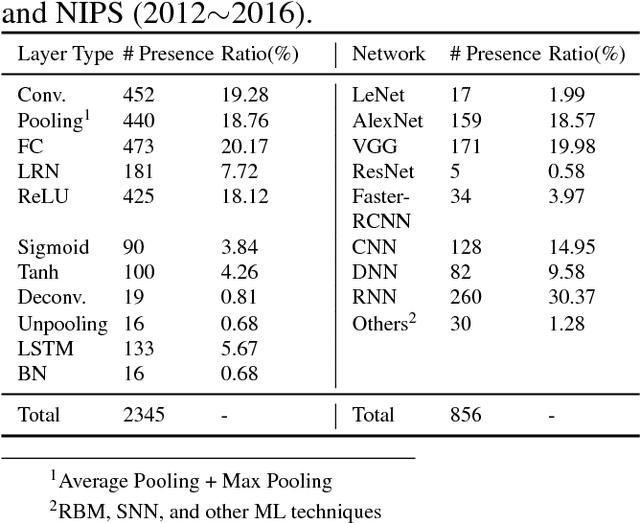
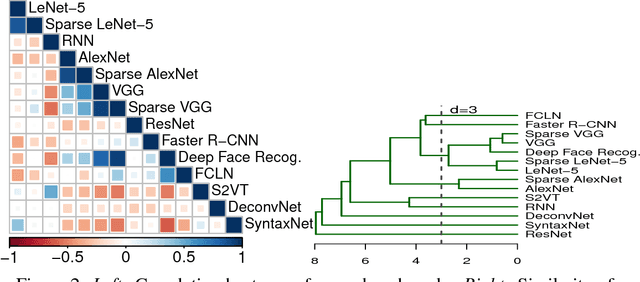
The increasing attention on deep learning has tremendously spurred the design of intelligence processing hardware. The variety of emerging intelligence processors requires standard benchmarks for fair comparison and system optimization (in both software and hardware). However, existing benchmarks are unsuitable for benchmarking intelligence processors due to their non-diversity and nonrepresentativeness. Also, the lack of a standard benchmarking methodology further exacerbates this problem. In this paper, we propose BENCHIP, a benchmark suite and benchmarking methodology for intelligence processors. The benchmark suite in BENCHIP consists of two sets of benchmarks: microbenchmarks and macrobenchmarks. The microbenchmarks consist of single-layer networks. They are mainly designed for bottleneck analysis and system optimization. The macrobenchmarks contain state-of-the-art industrial networks, so as to offer a realistic comparison of different platforms. We also propose a standard benchmarking methodology built upon an industrial software stack and evaluation metrics that comprehensively reflect the various characteristics of the evaluated intelligence processors. BENCHIP is utilized for evaluating various hardware platforms, including CPUs, GPUs, and accelerators. BENCHIP will be open-sourced soon.