 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDLSpec: A Deep Learning Task Exchange Specification
Feb 26, 2020
Deep Learning (DL) innovations are being introduced at a rapid pace. However, the current lack of standard specification of DL tasks makes sharing, running, reproducing, and comparing these innovations difficult. To address this problem, we propose DLSpec, a model-, dataset-, software-, and hardware-agnostic DL specification that captures the different aspects of DL tasks. DLSpec has been tested by specifying and running hundreds of DL tasks.
MLModelScope: A Distributed Platform for Model Evaluation and Benchmarking at Scale
Feb 19, 2020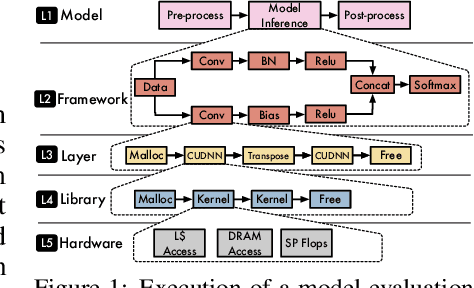
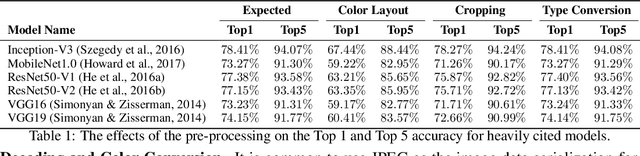


Machine Learning (ML) and Deep Learning (DL) innovations are being introduced at such a rapid pace that researchers are hard-pressed to analyze and study them. The complicated procedures for evaluating innovations, along with the lack of standard and efficient ways of specifying and provisioning ML/DL evaluation, is a major "pain point" for the community. This paper proposes MLModelScope, an open-source, framework/hardware agnostic, extensible and customizable design that enables repeatable, fair, and scalable model evaluation and benchmarking. We implement the distributed design with support for all major frameworks and hardware, and equip it with web, command-line, and library interfaces. To demonstrate MLModelScope's capabilities we perform parallel evaluation and show how subtle changes to model evaluation pipeline affects the accuracy and HW/SW stack choices affect performance.
DLBricks: Composable Benchmark Generation to Reduce Deep Learning Benchmarking Effort on CPUs
Nov 20, 2019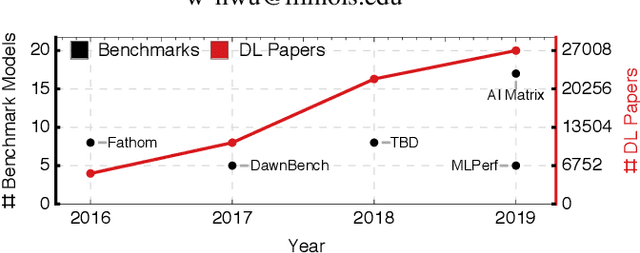



The past few years have seen a surge of applying Deep Learning (DL) models for a wide array of tasks such as image classification, object detection, machine translation, etc. While DL models provide an opportunity to solve otherwise intractable tasks, their adoption relies on them being optimized to meet latency and resource requirements. Benchmarking is a key step in this process but has been hampered in part due to the lack of representative and up-to-date benchmarking suites. This is exacerbated by the fast-evolving pace of DL models. This paper proposes DLBricks, a composable benchmark generation design that reduces the effort of developing, maintaining, and running DL benchmarks on CPUs. DLBricks decomposes DL models into a set of unique runnable networks and constructs the original model's performance using the performance of the generated benchmarks. DLBricks leverages two key observations: DL layers are the performance building blocks of DL models and layers are extensively repeated within and across DL models. Since benchmarks are generated automatically and the benchmarking time is minimized, DLBricks can keep up-to-date with the latest proposed models, relieving the pressure of selecting representative DL models. Moreover, DLBricks allows users to represent proprietary models within benchmark suites. We evaluate DLBricks using $50$ MXNet models spanning $5$ DL tasks on $4$ representative CPU systems. We show that DLBricks provides an accurate performance estimate for the DL models and reduces the benchmarking time across systems (e.g. within $95\%$ accuracy and up to $4.4\times$ benchmarking time speedup on Amazon EC2 c5.xlarge).
The Design and Implementation of a Scalable DL Benchmarking Platform
Nov 19, 2019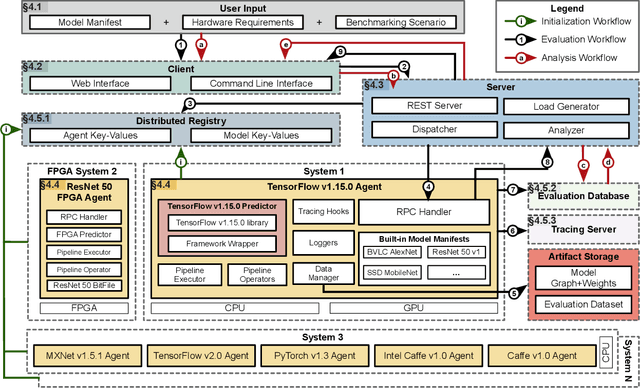


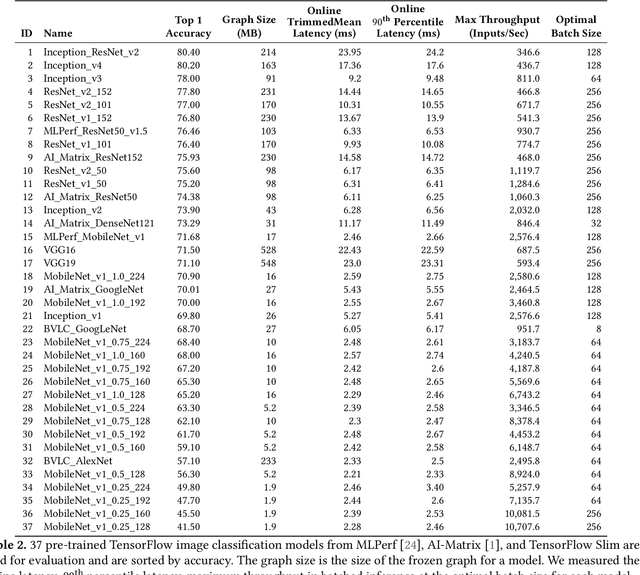
The current Deep Learning (DL) landscape is fast-paced and is rife with non-uniform models, hardware/software (HW/SW) stacks, but lacks a DL benchmarking platform to facilitate evaluation and comparison of DL innovations, be it models, frameworks, libraries, or hardware. Due to the lack of a benchmarking platform, the current practice of evaluating the benefits of proposed DL innovations is both arduous and error-prone - stifling the adoption of the innovations. In this work, we first identify $10$ design features which are desirable within a DL benchmarking platform. These features include: performing the evaluation in a consistent, reproducible, and scalable manner, being framework and hardware agnostic, supporting real-world benchmarking workloads, providing in-depth model execution inspection across the HW/SW stack levels, etc. We then propose MLModelScope, a DL benchmarking platform design that realizes the $10$ objectives. MLModelScope proposes a specification to define DL model evaluations and techniques to provision the evaluation workflow using the user-specified HW/SW stack. MLModelScope defines abstractions for frameworks and supports board range of DL models and evaluation scenarios. We implement MLModelScope as an open-source project with support for all major frameworks and hardware architectures. Through MLModelScope's evaluation and automated analysis workflows, we performed case-study analyses of $37$ models across $4$ systems and show how model, hardware, and framework selection affects model accuracy and performance under different benchmarking scenarios. We further demonstrated how MLModelScope's tracing capability gives a holistic view of model execution and helps pinpoint bottlenecks.
Benanza: Automatic $μ$Benchmark Generation to Compute "Lower-bound" Latency and Inform Optimizations of Deep Learning Models on GPUs
Nov 19, 2019

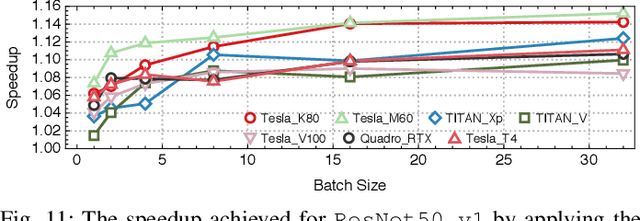

As Deep Learning (DL) models have been increasingly used in latency-sensitive applications, there has been a growing interest in improving their response time. An important venue for such improvement is to profile the execution of these models and characterize their performance to identify possible optimization opportunities. However, the current profiling tools lack the highly desired abilities to characterize ideal performance, identify sources of inefficiency, and quantify the benefits of potential optimizations. Such deficiencies have led to slow characterization/optimization cycles that cannot keep up with the fast pace at which new DL models are introduced. We propose Benanza, a sustainable and extensible benchmarking and analysis design that speeds up the characterization/optimization cycle of DL models on GPUs. Benanza consists of four major components: a model processor that parses models into an internal representation, a configurable benchmark generator that automatically generates micro-benchmarks given a set of models, a database of benchmark results, and an analyzer that computes the "lower-bound" latency of DL models using the benchmark data and informs optimizations of model execution. The "lower-bound" latency metric estimates the ideal model execution on a GPU system and serves as the basis for identifying optimization opportunities in frameworks or system libraries. We used Benanza to evaluate 30 ONNX models in MXNet, ONNX Runtime, and PyTorch on 7 GPUs ranging from Kepler to the latest Turing, and identified optimizations in parallel layer execution, cuDNN convolution algorithm selection, framework inefficiency, layer fusion, and using Tensor Cores.
Across-Stack Profiling and Characterization of Machine Learning Models on GPUs
Aug 19, 2019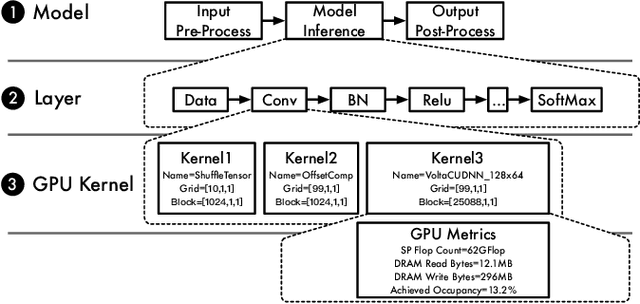
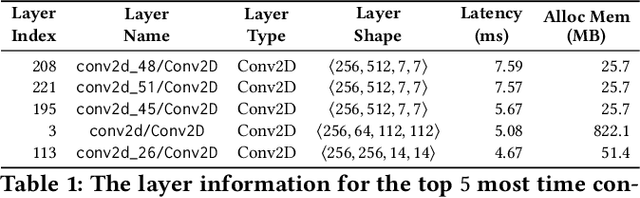
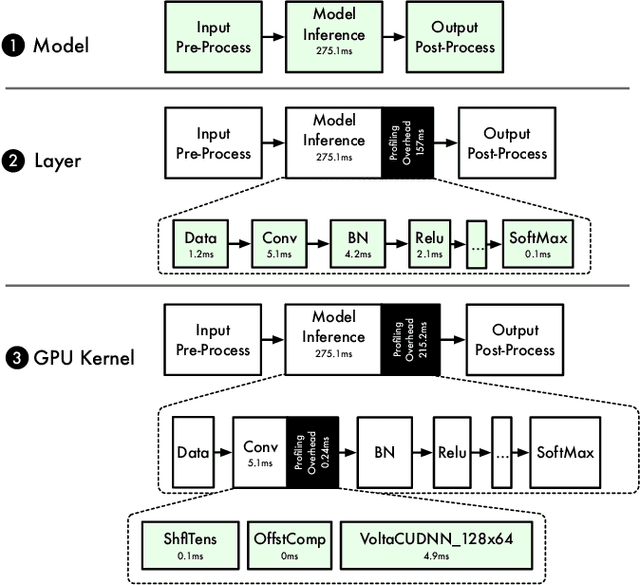

The world sees a proliferation of machine learning/deep learning (ML) models and their wide adoption in different application domains recently. This has made the profiling and characterization of ML models an increasingly pressing task for both hardware designers and system providers, as they would like to offer the best possible computing system to serve ML models with the desired latency, throughput, and energy requirements while maximizing resource utilization. Such an endeavor is challenging as the characteristics of an ML model depend on the interplay between the model, framework, system libraries, and the hardware (or the HW/SW stack). A thorough characterization requires understanding the behavior of the model execution across the HW/SW stack levels. Existing profiling tools are disjoint, however, and only focus on profiling within a particular level of the stack. This paper proposes a leveled profiling design that leverages existing profiling tools to perform across-stack profiling. The design does so in spite of the profiling overheads incurred from the profiling providers. We coupled the profiling capability with an automatic analysis pipeline to systematically characterize 65 state-of-the-art ML models. Through this characterization, we show that our across-stack profiling solution provides insights (which are difficult to discern otherwise) on the characteristics of ML models, ML frameworks, and GPU hardware.
Challenges and Pitfalls of Reproducing Machine Learning Artifacts
Apr 29, 2019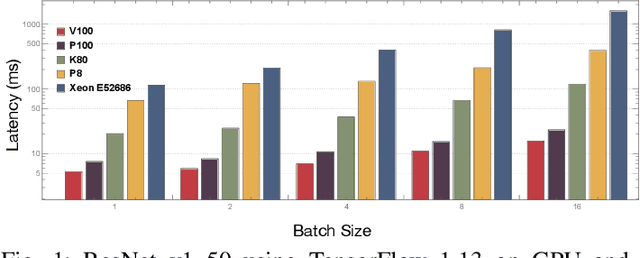


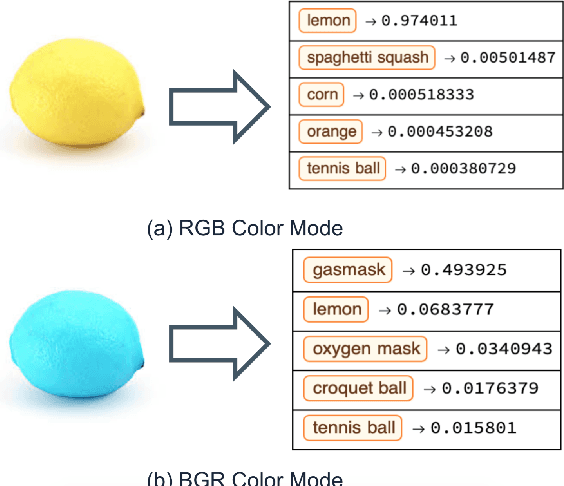
An increasingly complex and diverse collection of Machine Learning(ML) models as well as hardware/software stacks, collectively referred to as "ML artifacts", are being proposed - leading to a diverse landscape of ML. These ML innovations proposed have outpaced researchers' ability to analyze, study and adapt them. This is exacerbated by the complicated and sometimes non-reproducible procedures for ML evaluation. The current practice of sharing ML artifacts is through repositories where artifact authors post ad-hoc code and some documentation. The authors often fail to reveal critical information for others to reproduce their results. One often fails to reproduce artifact authors' claims, not to mention adapt the model to his/her own use. This article discusses the common challenges and pitfalls of reproducing ML artifacts, which can be used as a guideline for ML researchers when sharing or reproducing artifacts.
MLModelScope: Evaluate and Measure ML Models within AI Pipelines
Nov 24, 2018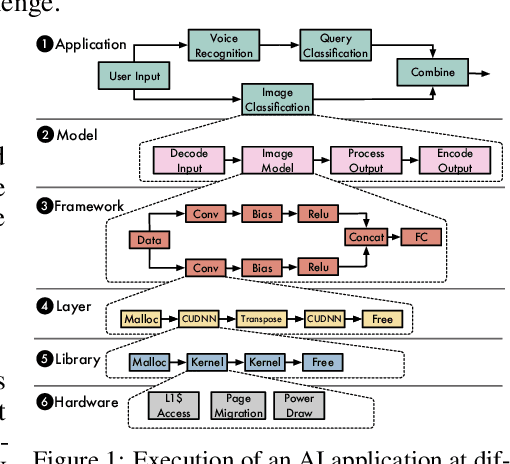
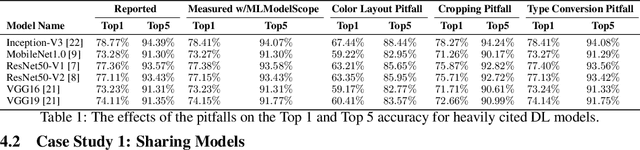
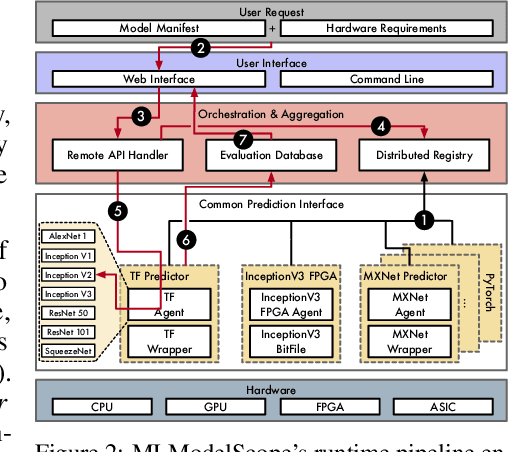

The current landscape of Machine Learning (ML) and Deep Learning (DL) is rife with non-uniform frameworks, models, and system stacks but lacks standard tools to facilitate the evaluation and measurement of model. Due to the absence of such tools, the current practice for evaluating and comparing the benefits of proposed AI innovations (be it hardware or software) on end-to-end AI pipelines is both arduous and error prone -- stifling the adoption of the innovations. We propose MLModelScope -- a hardware/software agnostic platform to facilitate the evaluation, measurement, and introspection of ML models within AI pipelines. MLModelScope aids application developers in discovering and experimenting with models, data scientists developers in replicating and evaluating for publishing models, and system architects in understanding the performance of AI workloads. We describe the design and implementation of MLModelScope and show how it is able to give users a holistic view into the execution of models within AI pipelines. Using AlexNet as a case study, we demonstrate how MLModelScope aids in identifying deviation in accuracy, helps in pin pointing the source of system bottlenecks, and automates the evaluation and performance aggregation of models across frameworks and systems.