 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaster Neighborhood Attention: Reducing the O(n^2) Cost of Self Attention at the Threadblock Level
Mar 07, 2024



Neighborhood attention reduces the cost of self attention by restricting each token's attention span to its nearest neighbors. This restriction, parameterized by a window size and dilation factor, draws a spectrum of possible attention patterns between linear projection and self attention. Neighborhood attention, and more generally sliding window attention patterns, have long been bounded by infrastructure, particularly in higher-rank spaces (2-D and 3-D), calling for the development of custom kernels, which have been limited in either functionality, or performance, if not both. In this work, we first show that neighborhood attention can be represented as a batched GEMM problem, similar to standard attention, and implement it for 1-D and 2-D neighborhood attention. These kernels on average provide 895% and 272% improvement in full precision latency compared to existing naive kernels for 1-D and 2-D neighborhood attention respectively. We find certain inherent inefficiencies in all unfused neighborhood attention kernels that bound their performance and lower-precision scalability. We also developed fused neighborhood attention; an adaptation of fused dot-product attention kernels that allow fine-grained control over attention across different spatial axes. Known for reducing the quadratic time complexity of self attention to a linear complexity, neighborhood attention can now enjoy a reduced and constant memory footprint, and record-breaking half precision latency. We observe that our fused kernels successfully circumvent some of the unavoidable inefficiencies in unfused implementations. While our unfused GEMM-based kernels only improve half precision performance compared to naive kernels by an average of 496% and 113% in 1-D and 2-D problems respectively, our fused kernels improve naive kernels by an average of 1607% and 581% in 1-D and 2-D problems respectively.
Pseudo-IoU: Improving Label Assignment in Anchor-Free Object Detection
Apr 29, 2021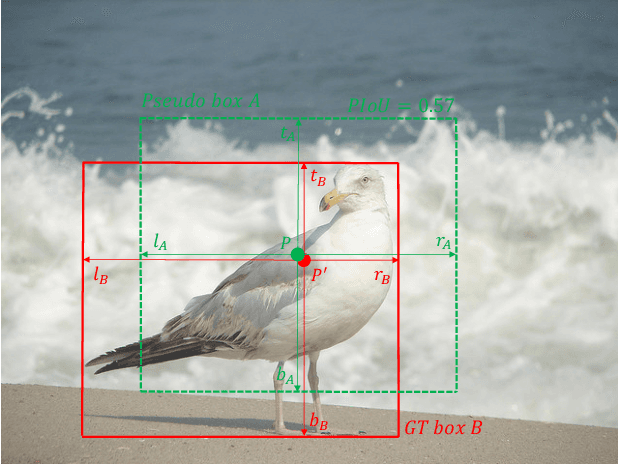
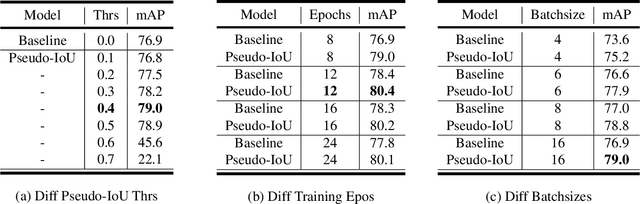
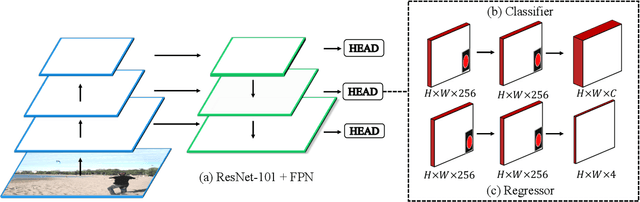
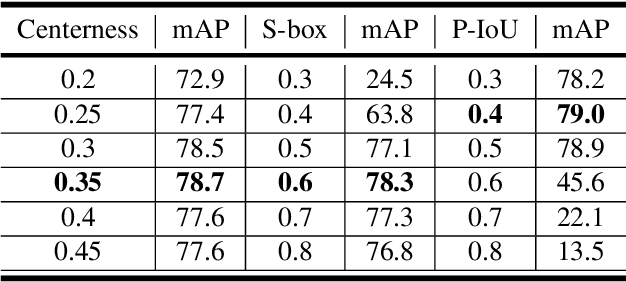
Current anchor-free object detectors are quite simple and effective yet lack accurate label assignment methods, which limits their potential in competing with classic anchor-based models that are supported by well-designed assignment methods based on the Intersection-over-Union~(IoU) metric. In this paper, we present \textbf{Pseudo-Intersection-over-Union~(Pseudo-IoU)}: a simple metric that brings more standardized and accurate assignment rule into anchor-free object detection frameworks without any additional computational cost or extra parameters for training and testing, making it possible to further improve anchor-free object detection by utilizing training samples of good quality under effective assignment rules that have been previously applied in anchor-based methods. By incorporating Pseudo-IoU metric into an end-to-end single-stage anchor-free object detection framework, we observe consistent improvements in their performance on general object detection benchmarks such as PASCAL VOC and MSCOCO. Our method (single-model and single-scale) also achieves comparable performance to other recent state-of-the-art anchor-free methods without bells and whistles. Our code is based on mmdetection toolbox and will be made publicly available at https://github.com/SHI-Labs/Pseudo-IoU-for-Anchor-Free-Object-Detection.
At-Scale Sparse Deep Neural Network Inference with Efficient GPU Implementation
Sep 02, 2020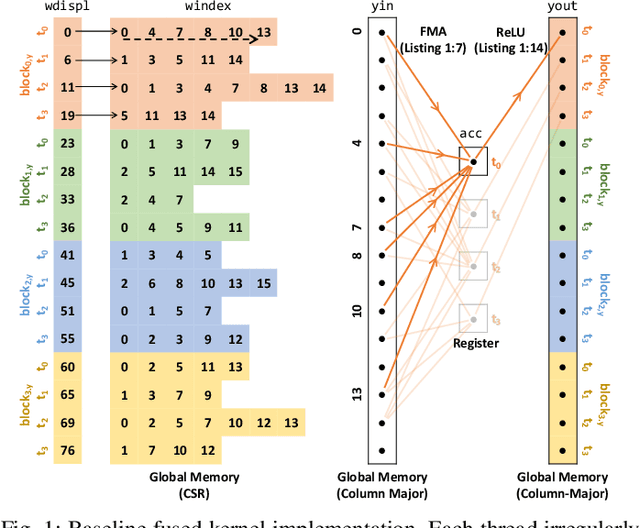
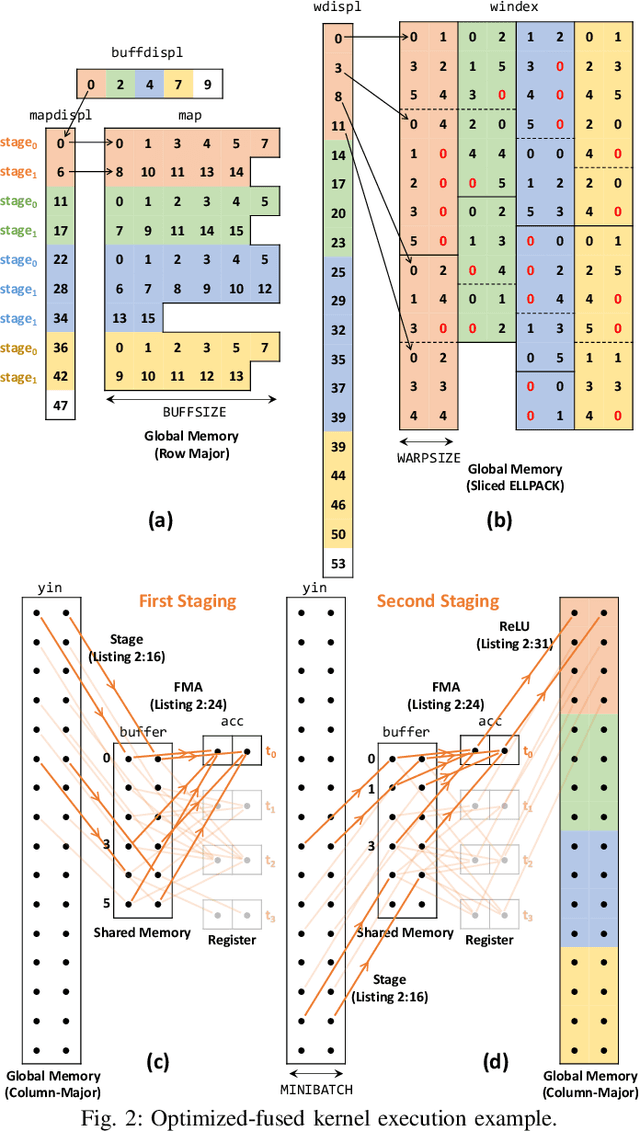
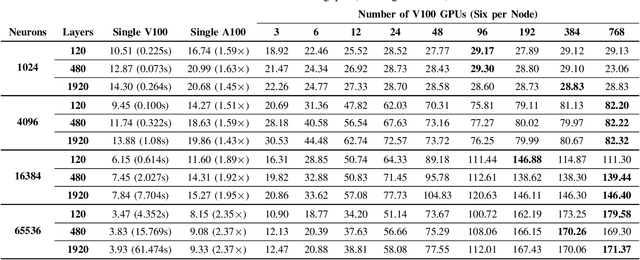
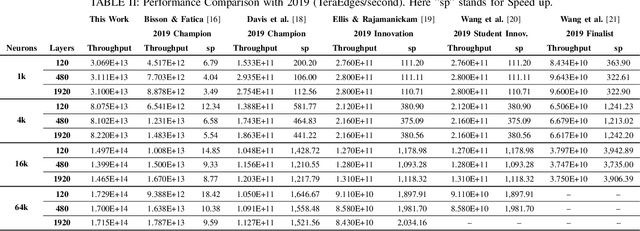
This paper presents GPU performance optimization and scaling results for inference models of the Sparse Deep Neural Network Challenge 2020. Demands for network quality have increased rapidly, pushing the size and thus the memory requirements of many neural networks beyond the capacity of available accelerators. Sparse deep neural networks (SpDNN) have shown promise for reining in the memory footprint of large neural networks. However, there is room for improvement in implementing SpDNN operations on GPUs. This work presents optimized sparse matrix multiplication kernels fused with the ReLU function. The optimized kernels reuse input feature maps from the shared memory and sparse weights from registers. For multi-GPU parallelism, our SpDNN implementation duplicates weights and statically partition the feature maps across GPUs. Results for the challenge benchmarks show that the proposed kernel design and multi-GPU parallelization achieve up to 180 tera-edges per second inference throughput. These results are up to 4.3x faster for a single GPU and an order of magnitude faster at full scale than those of the champion of the 2019 Sparse Deep Neural Network Graph Challenge for the same generation of NVIDIA V100 GPUs. Using the same implementation, we also show single-GPU throughput on NVIDIA A100 is 2.37$\times$ faster than V100.
* 7 pages
Alleviating Semantic-level Shift: A Semi-supervised Domain Adaptation Method for Semantic Segmentation
Apr 02, 2020
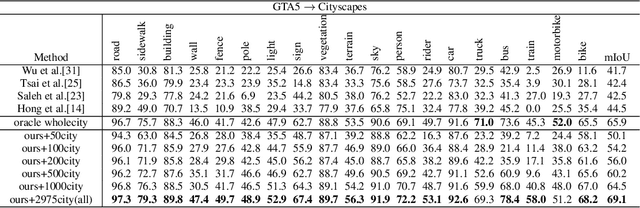
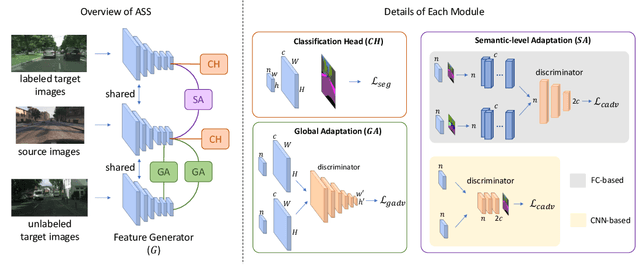
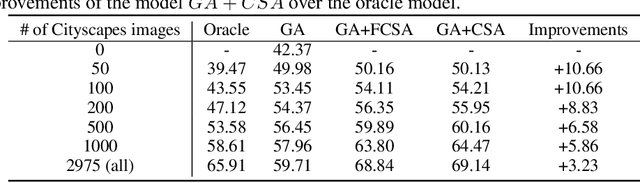
Learning segmentation from synthetic data and adapting to real data can significantly relieve human efforts in labelling pixel-level masks. A key challenge of this task is how to alleviate the data distribution discrepancy between the source and target domains, i.e. reducing domain shift. The common approach to this problem is to minimize the discrepancy between feature distributions from different domains through adversarial training. However, directly aligning the feature distribution globally cannot guarantee consistency from a local view (i.e. semantic-level), which prevents certain semantic knowledge learned on the source domain from being applied to the target domain. To tackle this issue, we propose a semi-supervised approach named Alleviating Semantic-level Shift (ASS), which can successfully promote the distribution consistency from both global and local views. Specifically, leveraging a small number of labeled data from the target domain, we directly extract semantic-level feature representations from both the source and the target domains by averaging the features corresponding to same categories advised by pixel-level masks. We then feed the produced features to the discriminator to conduct semantic-level adversarial learning, which collaborates with the adversarial learning from the global view to better alleviate the domain shift. We apply our ASS to two domain adaptation tasks, from GTA5 to Cityscapes and from Synthia to Cityscapes. Extensive experiments demonstrate that: (1) ASS can significantly outperform the current unsupervised state-of-the-arts by employing a small number of annotated samples from the target domain; (2) ASS can beat the oracle model trained on the whole target dataset by over 3 points by augmenting the synthetic source data with annotated samples from the target domain without suffering from the prevalent problem of overfitting to the source domain.
DLSpec: A Deep Learning Task Exchange Specification
Feb 26, 2020
Deep Learning (DL) innovations are being introduced at a rapid pace. However, the current lack of standard specification of DL tasks makes sharing, running, reproducing, and comparing these innovations difficult. To address this problem, we propose DLSpec, a model-, dataset-, software-, and hardware-agnostic DL specification that captures the different aspects of DL tasks. DLSpec has been tested by specifying and running hundreds of DL tasks.
PaRe: A Paper-Reviewer Matching Approach Using a Common Topic Space
Sep 25, 2019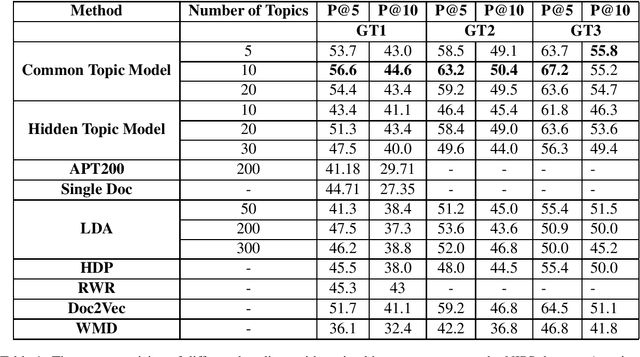
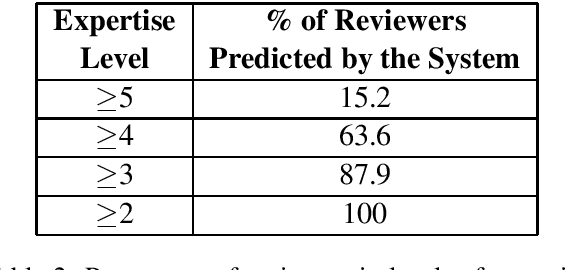


Finding the right reviewers to assess the quality of conference submissions is a time consuming process for conference organizers. Given the importance of this step, various automated reviewer-paper matching solutions have been proposed to alleviate the burden. Prior approaches, including bag-of-words models and probabilistic topic models have been inadequate to deal with the vocabulary mismatch and partial topic overlap between a paper submission and the reviewer's expertise. Our approach, the common topic model, jointly models the topics common to the submission and the reviewer's profile while relying on abstract topic vectors. Experiments and insightful evaluations on two datasets demonstrate that the proposed method achieves consistent improvements compared to available state-of-the-art implementations of paper-reviewer matching.
SPGNet: Semantic Prediction Guidance for Scene Parsing
Aug 26, 2019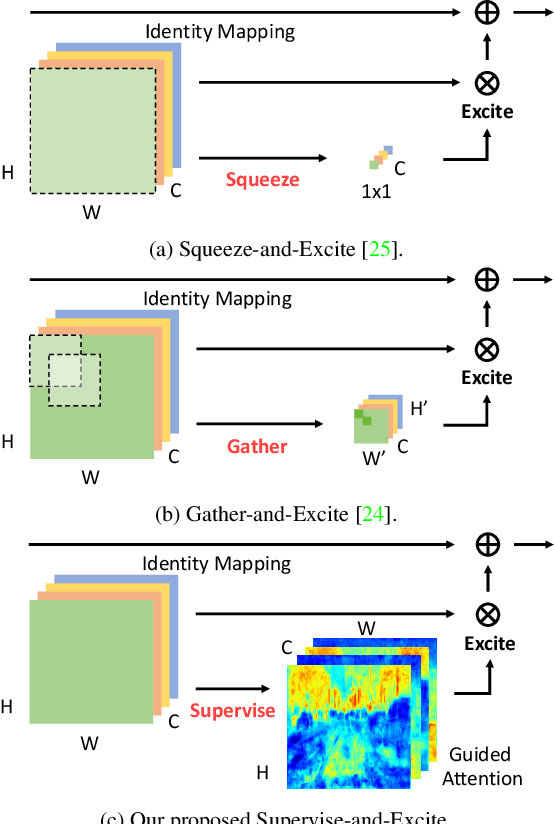
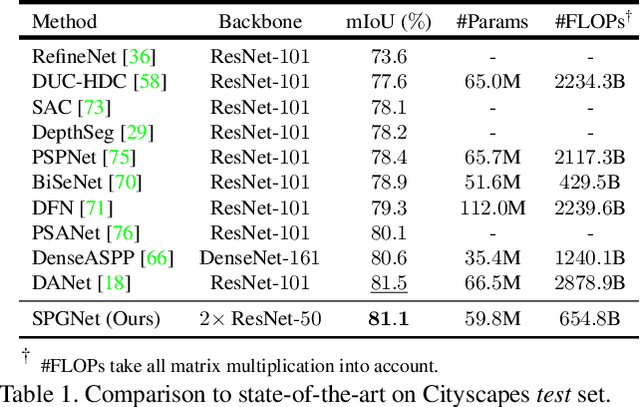
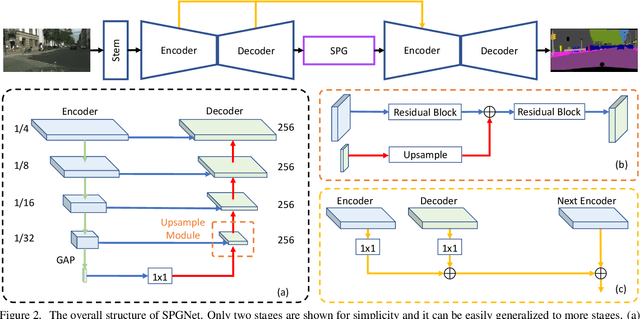

Multi-scale context module and single-stage encoder-decoder structure are commonly employed for semantic segmentation. The multi-scale context module refers to the operations to aggregate feature responses from a large spatial extent, while the single-stage encoder-decoder structure encodes the high-level semantic information in the encoder path and recovers the boundary information in the decoder path. In contrast, multi-stage encoder-decoder networks have been widely used in human pose estimation and show superior performance than their single-stage counterpart. However, few efforts have been attempted to bring this effective design to semantic segmentation. In this work, we propose a Semantic Prediction Guidance (SPG) module which learns to re-weight the local features through the guidance from pixel-wise semantic prediction. We find that by carefully re-weighting features across stages, a two-stage encoder-decoder network coupled with our proposed SPG module can significantly outperform its one-stage counterpart with similar parameters and computations. Finally, we report experimental results on the semantic segmentation benchmark Cityscapes, in which our SPGNet attains 81.1% on the test set using only 'fine' annotations.
MLModelScope: Evaluate and Measure ML Models within AI Pipelines
Nov 24, 2018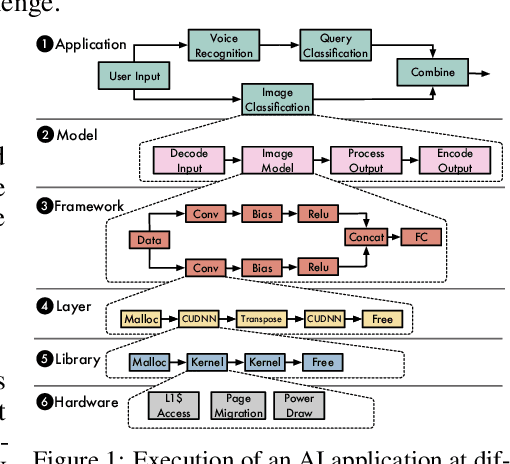
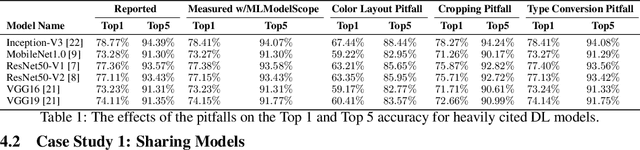
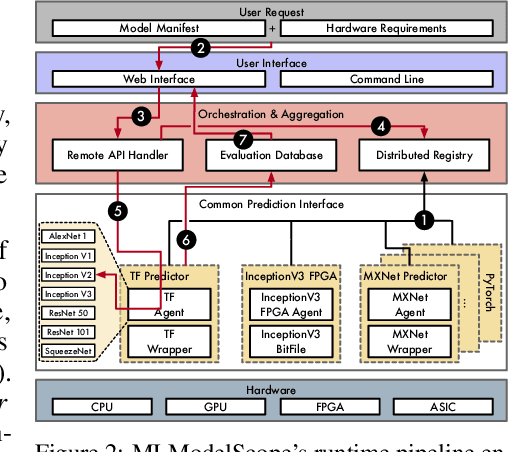

The current landscape of Machine Learning (ML) and Deep Learning (DL) is rife with non-uniform frameworks, models, and system stacks but lacks standard tools to facilitate the evaluation and measurement of model. Due to the absence of such tools, the current practice for evaluating and comparing the benefits of proposed AI innovations (be it hardware or software) on end-to-end AI pipelines is both arduous and error prone -- stifling the adoption of the innovations. We propose MLModelScope -- a hardware/software agnostic platform to facilitate the evaluation, measurement, and introspection of ML models within AI pipelines. MLModelScope aids application developers in discovering and experimenting with models, data scientists developers in replicating and evaluating for publishing models, and system architects in understanding the performance of AI workloads. We describe the design and implementation of MLModelScope and show how it is able to give users a holistic view into the execution of models within AI pipelines. Using AlexNet as a case study, we demonstrate how MLModelScope aids in identifying deviation in accuracy, helps in pin pointing the source of system bottlenecks, and automates the evaluation and performance aggregation of models across frameworks and systems.