 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctic Inference with Shift Parallelism: Fast and Efficient Open Source Inference System for Enterprise AI
Jul 16, 2025Inference is now the dominant AI workload, yet existing systems force trade-offs between latency, throughput, and cost. Arctic Inference, an open-source vLLM plugin from Snowflake AI Research, introduces Shift Parallelism, a dynamic parallelism strategy that adapts to real-world traffic while integrating speculative decoding, SwiftKV compute reduction, and optimized embedding inference. It achieves up to 3.4 times faster request completion, 1.75 times faster generation, and 1.6M tokens/sec per GPU for embeddings, outperforming both latency- and throughput-optimized deployments. Already powering Snowflake Cortex AI, Arctic Inference delivers state-of-the-art, cost-effective inference for enterprise AI and is now available to the community.
At-Scale Sparse Deep Neural Network Inference with Efficient GPU Implementation
Sep 02, 2020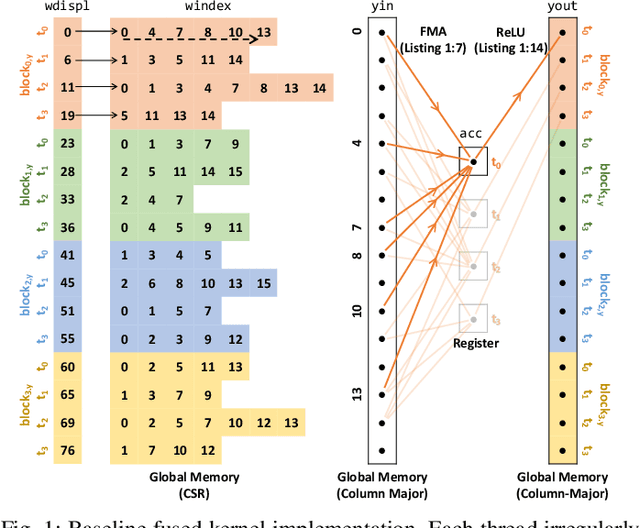
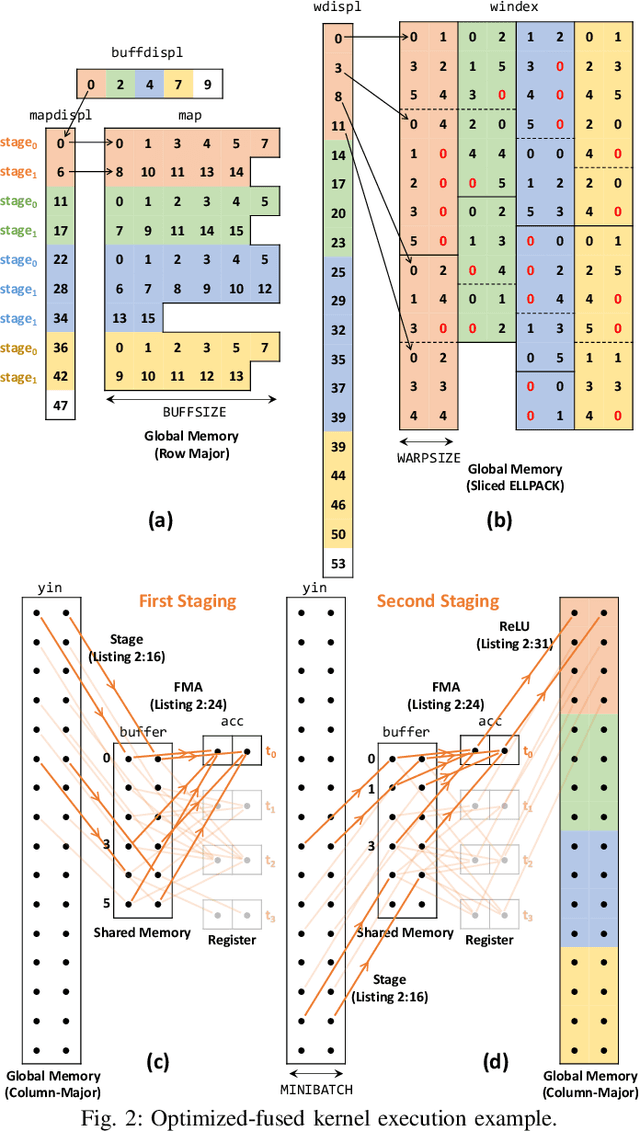
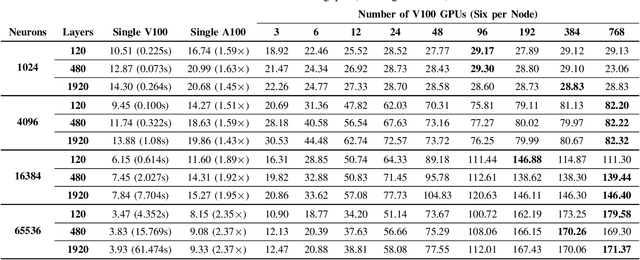
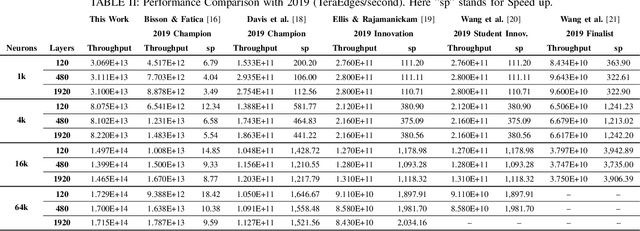
This paper presents GPU performance optimization and scaling results for inference models of the Sparse Deep Neural Network Challenge 2020. Demands for network quality have increased rapidly, pushing the size and thus the memory requirements of many neural networks beyond the capacity of available accelerators. Sparse deep neural networks (SpDNN) have shown promise for reining in the memory footprint of large neural networks. However, there is room for improvement in implementing SpDNN operations on GPUs. This work presents optimized sparse matrix multiplication kernels fused with the ReLU function. The optimized kernels reuse input feature maps from the shared memory and sparse weights from registers. For multi-GPU parallelism, our SpDNN implementation duplicates weights and statically partition the feature maps across GPUs. Results for the challenge benchmarks show that the proposed kernel design and multi-GPU parallelization achieve up to 180 tera-edges per second inference throughput. These results are up to 4.3x faster for a single GPU and an order of magnitude faster at full scale than those of the champion of the 2019 Sparse Deep Neural Network Graph Challenge for the same generation of NVIDIA V100 GPUs. Using the same implementation, we also show single-GPU throughput on NVIDIA A100 is 2.37$\times$ faster than V100.
* 7 pages