 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArctic Inference with Shift Parallelism: Fast and Efficient Open Source Inference System for Enterprise AI
Jul 16, 2025Inference is now the dominant AI workload, yet existing systems force trade-offs between latency, throughput, and cost. Arctic Inference, an open-source vLLM plugin from Snowflake AI Research, introduces Shift Parallelism, a dynamic parallelism strategy that adapts to real-world traffic while integrating speculative decoding, SwiftKV compute reduction, and optimized embedding inference. It achieves up to 3.4 times faster request completion, 1.75 times faster generation, and 1.6M tokens/sec per GPU for embeddings, outperforming both latency- and throughput-optimized deployments. Already powering Snowflake Cortex AI, Arctic Inference delivers state-of-the-art, cost-effective inference for enterprise AI and is now available to the community.
Helix: Distributed Serving of Large Language Models via Max-Flow on Heterogeneous GPUs
Jun 03, 2024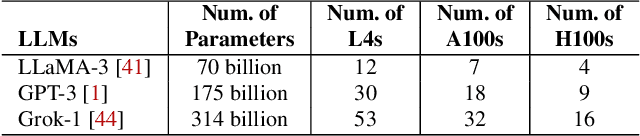



This paper introduces Helix, a distributed system for high-throughput, low-latency large language model (LLM) serving on heterogeneous GPU clusters. A key idea behind Helix is to formulate inference computation of LLMs over heterogeneous GPUs and network connections as a max-flow problem for a directed, weighted graph, whose nodes represent GPU instances and edges capture both GPU and network heterogeneity through their capacities. Helix then uses a mixed integer linear programming (MILP) algorithm to discover highly optimized strategies to serve LLMs. This approach allows Helix to jointly optimize model placement and request scheduling, two highly entangled tasks in heterogeneous LLM serving. Our evaluation on several heterogeneous cluster settings ranging from 24 to 42 GPU nodes shows that Helix improves serving throughput by up to 2.7$\times$ and reduces prompting and decoding latency by up to 2.8$\times$ and 1.3$\times$, respectively, compared to best existing approaches.
DSDRNet: Disentangling Representation and Reconstruct Network for Domain Generalization
Apr 22, 2024


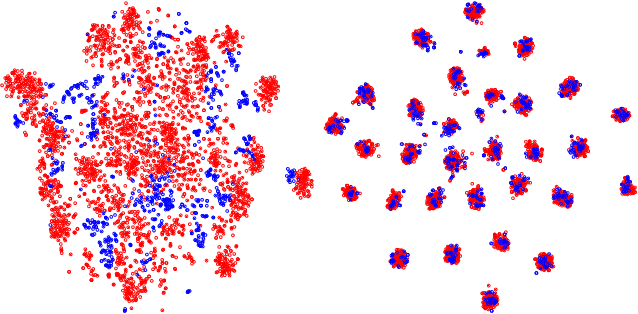
Domain generalization faces challenges due to the distribution shift between training and testing sets, and the presence of unseen target domains. Common solutions include domain alignment, meta-learning, data augmentation, or ensemble learning, all of which rely on domain labels or domain adversarial techniques. In this paper, we propose a Dual-Stream Separation and Reconstruction Network, dubbed DSDRNet. It is a disentanglement-reconstruction approach that integrates features of both inter-instance and intra-instance through dual-stream fusion. The method introduces novel supervised signals by combining inter-instance semantic distance and intra-instance similarity. Incorporating Adaptive Instance Normalization (AdaIN) into a two-stage cyclic reconstruction process enhances self-disentangled reconstruction signals to facilitate model convergence. Extensive experiments on four benchmark datasets demonstrate that DSDRNet outperforms other popular methods in terms of domain generalization capabilities.
Cross-Modal Adapter: Parameter-Efficient Transfer Learning Approach for Vision-Language Models
Apr 19, 2024
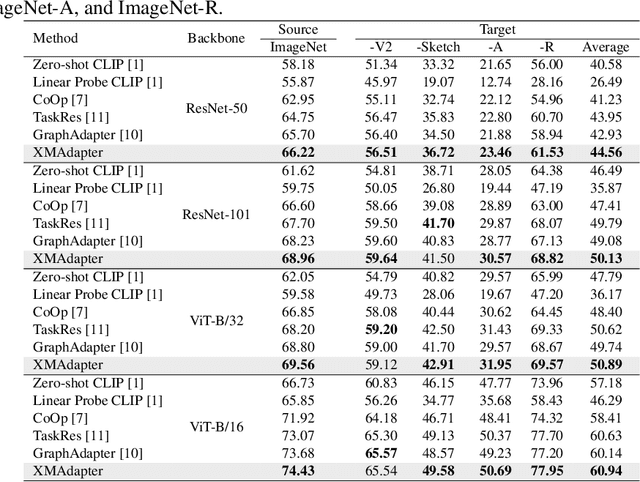


Adapter-based parameter-efficient transfer learning has achieved exciting results in vision-language models. Traditional adapter methods often require training or fine-tuning, facing challenges such as insufficient samples or resource limitations. While some methods overcome the need for training by leveraging image modality cache and retrieval, they overlook the text modality's importance and cross-modal cues for the efficient adaptation of parameters in visual-language models. This work introduces a cross-modal parameter-efficient approach named XMAdapter. XMAdapter establishes cache models for both text and image modalities. It then leverages retrieval through visual-language bimodal information to gather clues for inference. By dynamically adjusting the affinity ratio, it achieves cross-modal fusion, decoupling different modal similarities to assess their respective contributions. Additionally, it explores hard samples based on differences in cross-modal affinity and enhances model performance through adaptive adjustment of sample learning intensity. Extensive experimental results on benchmark datasets demonstrate that XMAdapter outperforms previous adapter-based methods significantly regarding accuracy, generalization, and efficiency.
Soft-Prompting with Graph-of-Thought for Multi-modal Representation Learning
Apr 06, 2024
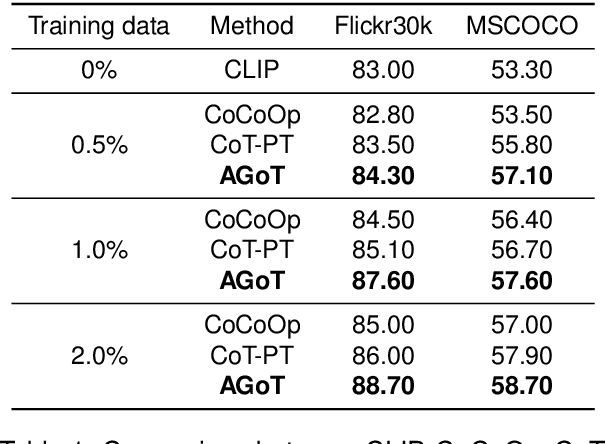

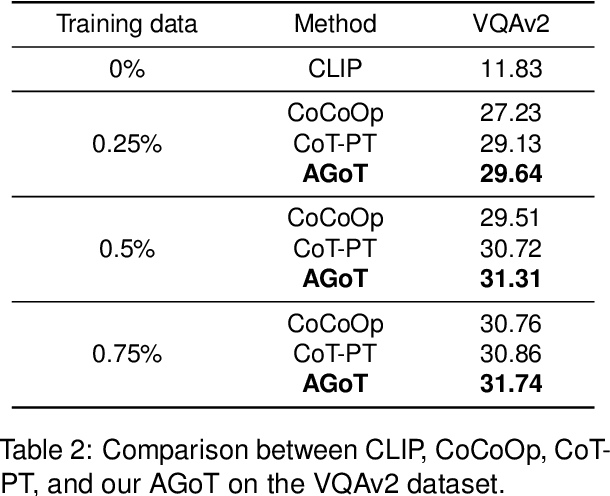
The chain-of-thought technique has been received well in multi-modal tasks. It is a step-by-step linear reasoning process that adjusts the length of the chain to improve the performance of generated prompts. However, human thought processes are predominantly non-linear, as they encompass multiple aspects simultaneously and employ dynamic adjustment and updating mechanisms. Therefore, we propose a novel Aggregation-Graph-of-Thought (AGoT) mechanism for soft-prompt tuning in multi-modal representation learning. The proposed AGoT models the human thought process not only as a chain but also models each step as a reasoning aggregation graph to cope with the overlooked multiple aspects of thinking in single-step reasoning. This turns the entire reasoning process into prompt aggregation and prompt flow operations. Experiments show that our multi-modal model enhanced with AGoT soft-prompting achieves good results in several tasks such as text-image retrieval, visual question answering, and image recognition. In addition, we demonstrate that it has good domain generalization performance due to better reasoning.