 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE: Zero-Shot Sparse Mixture of Low-Rank Experts Construction From Pre-Trained Foundation Models
Aug 19, 2024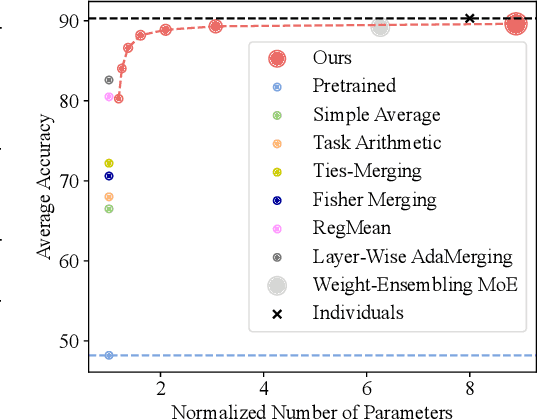



Deep model training on extensive datasets is increasingly becoming cost-prohibitive, prompting the widespread adoption of deep model fusion techniques to leverage knowledge from pre-existing models. From simple weight averaging to more sophisticated methods like AdaMerging, model fusion effectively improves model performance and accelerates the development of new models. However, potential interference between parameters of individual models and the lack of interpretability in the fusion progress remain significant challenges. Existing methods often try to resolve the parameter interference issue by evaluating attributes of parameters, such as their magnitude or sign, or by parameter pruning. In this study, we begin by examining the fine-tuning of linear layers through the lens of subspace analysis and explicitly define parameter interference as an optimization problem to shed light on this subject. Subsequently, we introduce an innovative approach to model fusion called zero-shot Sparse MIxture of Low-rank Experts (SMILE) construction, which allows for the upscaling of source models into an MoE model without extra data or further training. Our approach relies on the observation that fine-tuning mostly keeps the important parts from the pre-training, but it uses less significant or unused areas to adapt to new tasks. Also, the issue of parameter interference, which is intrinsically intractable in the original parameter space, can be managed by expanding the dimensions. We conduct extensive experiments across diverse scenarios, such as image classification and text generalization tasks, using full fine-tuning and LoRA fine-tuning, and we apply our method to large language models (CLIP models, Flan-T5 models, and Mistral-7B models), highlighting the adaptability and scalability of SMILE. Code is available at https://github.com/tanganke/fusion_bench
DSDRNet: Disentangling Representation and Reconstruct Network for Domain Generalization
Apr 22, 2024


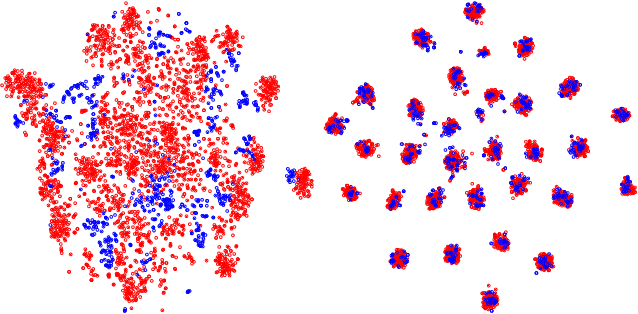
Domain generalization faces challenges due to the distribution shift between training and testing sets, and the presence of unseen target domains. Common solutions include domain alignment, meta-learning, data augmentation, or ensemble learning, all of which rely on domain labels or domain adversarial techniques. In this paper, we propose a Dual-Stream Separation and Reconstruction Network, dubbed DSDRNet. It is a disentanglement-reconstruction approach that integrates features of both inter-instance and intra-instance through dual-stream fusion. The method introduces novel supervised signals by combining inter-instance semantic distance and intra-instance similarity. Incorporating Adaptive Instance Normalization (AdaIN) into a two-stage cyclic reconstruction process enhances self-disentangled reconstruction signals to facilitate model convergence. Extensive experiments on four benchmark datasets demonstrate that DSDRNet outperforms other popular methods in terms of domain generalization capabilities.
Cross-Modal Adapter: Parameter-Efficient Transfer Learning Approach for Vision-Language Models
Apr 19, 2024
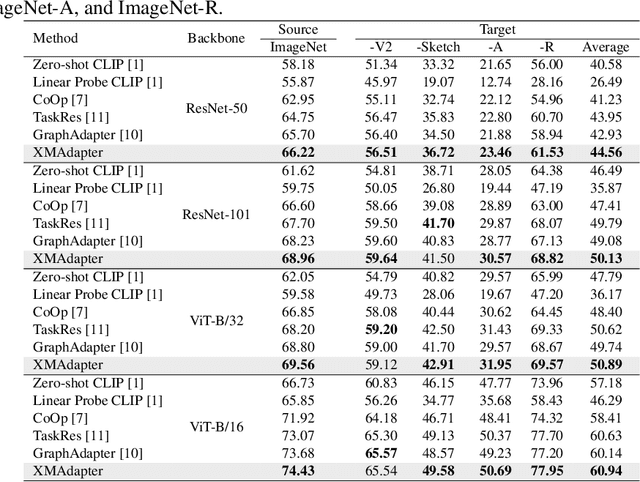


Adapter-based parameter-efficient transfer learning has achieved exciting results in vision-language models. Traditional adapter methods often require training or fine-tuning, facing challenges such as insufficient samples or resource limitations. While some methods overcome the need for training by leveraging image modality cache and retrieval, they overlook the text modality's importance and cross-modal cues for the efficient adaptation of parameters in visual-language models. This work introduces a cross-modal parameter-efficient approach named XMAdapter. XMAdapter establishes cache models for both text and image modalities. It then leverages retrieval through visual-language bimodal information to gather clues for inference. By dynamically adjusting the affinity ratio, it achieves cross-modal fusion, decoupling different modal similarities to assess their respective contributions. Additionally, it explores hard samples based on differences in cross-modal affinity and enhances model performance through adaptive adjustment of sample learning intensity. Extensive experimental results on benchmark datasets demonstrate that XMAdapter outperforms previous adapter-based methods significantly regarding accuracy, generalization, and efficiency.
Soft-Prompting with Graph-of-Thought for Multi-modal Representation Learning
Apr 06, 2024
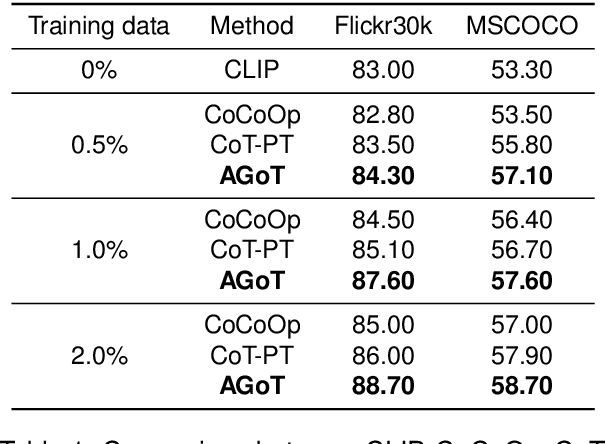

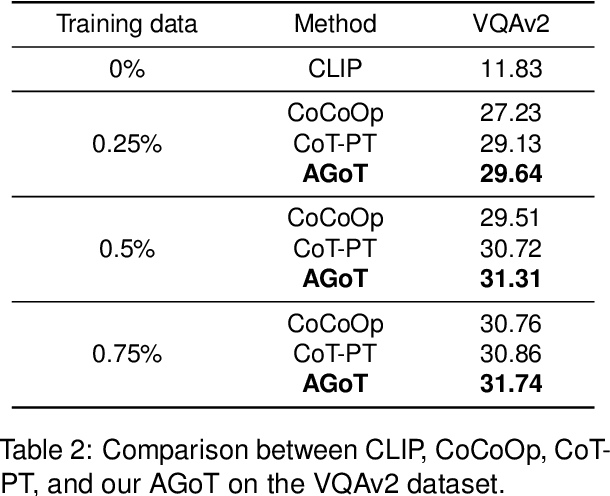
The chain-of-thought technique has been received well in multi-modal tasks. It is a step-by-step linear reasoning process that adjusts the length of the chain to improve the performance of generated prompts. However, human thought processes are predominantly non-linear, as they encompass multiple aspects simultaneously and employ dynamic adjustment and updating mechanisms. Therefore, we propose a novel Aggregation-Graph-of-Thought (AGoT) mechanism for soft-prompt tuning in multi-modal representation learning. The proposed AGoT models the human thought process not only as a chain but also models each step as a reasoning aggregation graph to cope with the overlooked multiple aspects of thinking in single-step reasoning. This turns the entire reasoning process into prompt aggregation and prompt flow operations. Experiments show that our multi-modal model enhanced with AGoT soft-prompting achieves good results in several tasks such as text-image retrieval, visual question answering, and image recognition. In addition, we demonstrate that it has good domain generalization performance due to better reasoning.
OmniForce: On Human-Centered, Large Model Empowered and Cloud-Edge Collaborative AutoML System
Mar 01, 2023



Automated machine learning (AutoML) seeks to build ML models with minimal human effort. While considerable research has been conducted in the area of AutoML in general, aiming to take humans out of the loop when building artificial intelligence (AI) applications, scant literature has focused on how AutoML works well in open-environment scenarios such as the process of training and updating large models, industrial supply chains or the industrial metaverse, where people often face open-loop problems during the search process: they must continuously collect data, update data and models, satisfy the requirements of the development and deployment environment, support massive devices, modify evaluation metrics, etc. Addressing the open-environment issue with pure data-driven approaches requires considerable data, computing resources, and effort from dedicated data engineers, making current AutoML systems and platforms inefficient and computationally intractable. Human-computer interaction is a practical and feasible way to tackle the problem of open-environment AI. In this paper, we introduce OmniForce, a human-centered AutoML (HAML) system that yields both human-assisted ML and ML-assisted human techniques, to put an AutoML system into practice and build adaptive AI in open-environment scenarios. Specifically, we present OmniForce in terms of ML version management; pipeline-driven development and deployment collaborations; a flexible search strategy framework; and widely provisioned and crowdsourced application algorithms, including large models. Furthermore, the (large) models constructed by OmniForce can be automatically turned into remote services in a few minutes; this process is dubbed model as a service (MaaS). Experimental results obtained in multiple search spaces and real-world use cases demonstrate the efficacy and efficiency of OmniForce.
DEAL: Difficulty-aware Active Learning for Semantic Segmentation
Oct 17, 2020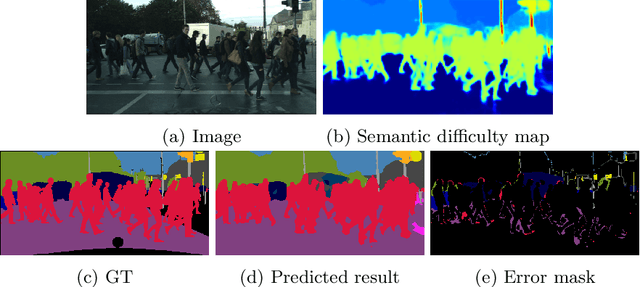

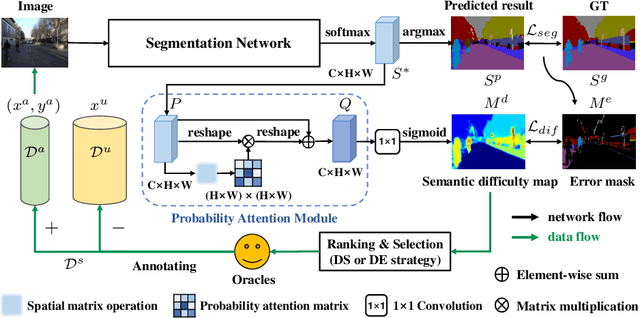
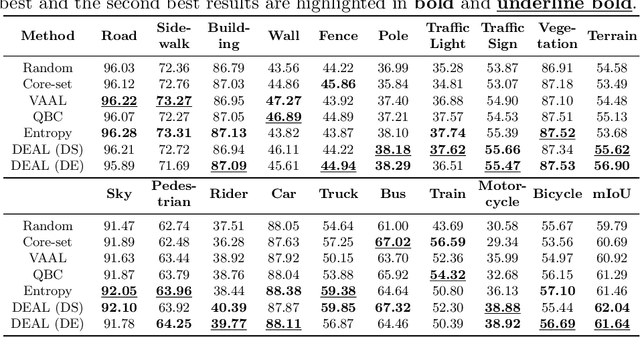
Active learning aims to address the paucity of labeled data by finding the most informative samples. However, when applying to semantic segmentation, existing methods ignore the segmentation difficulty of different semantic areas, which leads to poor performance on those hard semantic areas such as tiny or slender objects. To deal with this problem, we propose a semantic Difficulty-awarE Active Learning (DEAL) network composed of two branches: the common segmentation branch and the semantic difficulty branch. For the latter branch, with the supervision of segmentation error between the segmentation result and GT, a pixel-wise probability attention module is introduced to learn the semantic difficulty scores for different semantic areas. Finally, two acquisition functions are devised to select the most valuable samples with semantic difficulty. Competitive results on semantic segmentation benchmarks demonstrate that DEAL achieves state-of-the-art active learning performance and improves the performance of the hard semantic areas in particular.