 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSMILE: Zero-Shot Sparse Mixture of Low-Rank Experts Construction From Pre-Trained Foundation Models
Paper and Code
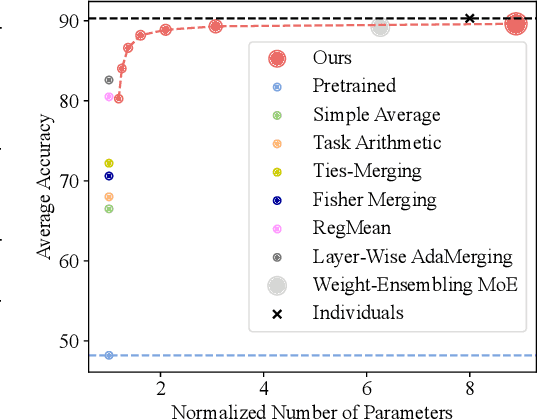



Deep model training on extensive datasets is increasingly becoming cost-prohibitive, prompting the widespread adoption of deep model fusion techniques to leverage knowledge from pre-existing models. From simple weight averaging to more sophisticated methods like AdaMerging, model fusion effectively improves model performance and accelerates the development of new models. However, potential interference between parameters of individual models and the lack of interpretability in the fusion progress remain significant challenges. Existing methods often try to resolve the parameter interference issue by evaluating attributes of parameters, such as their magnitude or sign, or by parameter pruning. In this study, we begin by examining the fine-tuning of linear layers through the lens of subspace analysis and explicitly define parameter interference as an optimization problem to shed light on this subject. Subsequently, we introduce an innovative approach to model fusion called zero-shot Sparse MIxture of Low-rank Experts (SMILE) construction, which allows for the upscaling of source models into an MoE model without extra data or further training. Our approach relies on the observation that fine-tuning mostly keeps the important parts from the pre-training, but it uses less significant or unused areas to adapt to new tasks. Also, the issue of parameter interference, which is intrinsically intractable in the original parameter space, can be managed by expanding the dimensions. We conduct extensive experiments across diverse scenarios, such as image classification and text generalization tasks, using full fine-tuning and LoRA fine-tuning, and we apply our method to large language models (CLIP models, Flan-T5 models, and Mistral-7B models), highlighting the adaptability and scalability of SMILE. Code is available at https://github.com/tanganke/fusion_bench