 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFreeSpec: Training-Free Long Video Generation via Singular-Spectrum Reconstruction
May 07, 2026Video diffusion models perform well in short-video synthesis, but their training-free extension to long videos often suffers from content drift, temporal inconsistency, and over-smoothed dynamics. Existing methods improve temporal consistency by combining a global branch with a local branch, but they often further decompose appearance consistency and temporal dynamics within each branch using predefined criteria. This assignment is unreliable when appearance and action progression are tightly coupled, such as in camera motion and sequential motion. We analyze the video temporal extension issue from a singular-spectrum perspective and show that enlarged self-attention windows induce spectral concentration: spectral energy becomes dominated by a few low-rank singular directions, preserving coarse structure but suppressing high-rank spatial details and motion-rich temporal variations. To mitigate this problem, we propose FreeSpec, a training-free spectral reconstruction framework for long-video generation. FreeSpec decomposes global and local features with singular value decomposition, and uses the global branch as low-rank spectral guidance and the local branch as a high-rank reconstruction basis. This spectrum-level fusion avoids the rigid feature partitioning of previous decomposition rules, preserving long-range consistency while better retaining spatial details and temporal dynamics. Experiments on Wan2.1 and LTX-Video demonstrate that FreeSpec improves long-video generation, especially for temporal dynamics, while maintaining strong visual quality and temporal consistency. Project demo: https://fdchen24.github.io/FreeSpec-Website/.
InpaintHuman: Reconstructing Occluded Humans with Multi-Scale UV Mapping and Identity-Preserving Diffusion Inpainting
Jan 05, 2026Reconstructing complete and animatable 3D human avatars from monocular videos remains challenging, particularly under severe occlusions. While 3D Gaussian Splatting has enabled photorealistic human rendering, existing methods struggle with incomplete observations, often producing corrupted geometry and temporal inconsistencies. We present InpaintHuman, a novel method for generating high-fidelity, complete, and animatable avatars from occluded monocular videos. Our approach introduces two key innovations: (i) a multi-scale UV-parameterized representation with hierarchical coarse-to-fine feature interpolation, enabling robust reconstruction of occluded regions while preserving geometric details; and (ii) an identity-preserving diffusion inpainting module that integrates textual inversion with semantic-conditioned guidance for subject-specific, temporally coherent completion. Unlike SDS-based methods, our approach employs direct pixel-level supervision to ensure identity fidelity. Experiments on synthetic benchmarks (PeopleSnapshot, ZJU-MoCap) and real-world scenarios (OcMotion) demonstrate competitive performance with consistent improvements in reconstruction quality across diverse poses and viewpoints.
Omni-View: Unlocking How Generation Facilitates Understanding in Unified 3D Model based on Multiview images
Nov 10, 2025This paper presents Omni-View, which extends the unified multimodal understanding and generation to 3D scenes based on multiview images, exploring the principle that "generation facilitates understanding". Consisting of understanding model, texture module, and geometry module, Omni-View jointly models scene understanding, novel view synthesis, and geometry estimation, enabling synergistic interaction between 3D scene understanding and generation tasks. By design, it leverages the spatiotemporal modeling capabilities of its texture module responsible for appearance synthesis, alongside the explicit geometric constraints provided by its dedicated geometry module, thereby enriching the model's holistic understanding of 3D scenes. Trained with a two-stage strategy, Omni-View achieves a state-of-the-art score of 55.4 on the VSI-Bench benchmark, outperforming existing specialized 3D understanding models, while simultaneously delivering strong performance in both novel view synthesis and 3D scene generation.
Unified Multimodal Understanding and Generation Models: Advances, Challenges, and Opportunities
May 05, 2025

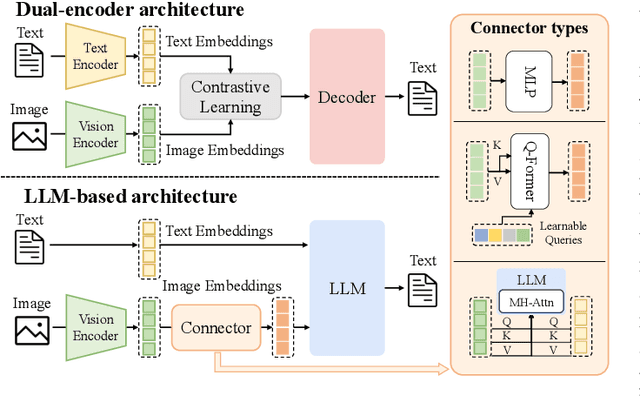

Recent years have seen remarkable progress in both multimodal understanding models and image generation models. Despite their respective successes, these two domains have evolved independently, leading to distinct architectural paradigms: While autoregressive-based architectures have dominated multimodal understanding, diffusion-based models have become the cornerstone of image generation. Recently, there has been growing interest in developing unified frameworks that integrate these tasks. The emergence of GPT-4o's new capabilities exemplifies this trend, highlighting the potential for unification. However, the architectural differences between the two domains pose significant challenges. To provide a clear overview of current efforts toward unification, we present a comprehensive survey aimed at guiding future research. First, we introduce the foundational concepts and recent advancements in multimodal understanding and text-to-image generation models. Next, we review existing unified models, categorizing them into three main architectural paradigms: diffusion-based, autoregressive-based, and hybrid approaches that fuse autoregressive and diffusion mechanisms. For each category, we analyze the structural designs and innovations introduced by related works. Additionally, we compile datasets and benchmarks tailored for unified models, offering resources for future exploration. Finally, we discuss the key challenges facing this nascent field, including tokenization strategy, cross-modal attention, and data. As this area is still in its early stages, we anticipate rapid advancements and will regularly update this survey. Our goal is to inspire further research and provide a valuable reference for the community. The references associated with this survey will be available on GitHub soon.
JointTuner: Appearance-Motion Adaptive Joint Training for Customized Video Generation
Mar 31, 2025



Recent text-to-video advancements have enabled coherent video synthesis from prompts and expanded to fine-grained control over appearance and motion. However, existing methods either suffer from concept interference due to feature domain mismatch caused by naive decoupled optimizations or exhibit appearance contamination induced by spatial feature leakage resulting from the entanglement of motion and appearance in reference video reconstructions. In this paper, we propose JointTuner, a novel adaptive joint training framework, to alleviate these issues. Specifically, we develop Adaptive LoRA, which incorporates a context-aware gating mechanism, and integrate the gated LoRA components into the spatial and temporal Transformers within the diffusion model. These components enable simultaneous optimization of appearance and motion, eliminating concept interference. In addition, we introduce the Appearance-independent Temporal Loss, which decouples motion patterns from intrinsic appearance in reference video reconstructions through an appearance-agnostic noise prediction task. The key innovation lies in adding frame-wise offset noise to the ground-truth Gaussian noise, perturbing its distribution, thereby disrupting spatial attributes associated with frames while preserving temporal coherence. Furthermore, we construct a benchmark comprising 90 appearance-motion customized combinations and 10 multi-type automatic metrics across four dimensions, facilitating a more comprehensive evaluation for this customization task. Extensive experiments demonstrate the superior performance of our method compared to current advanced approaches.
UNIC-Adapter: Unified Image-instruction Adapter with Multi-modal Transformer for Image Generation
Dec 25, 2024



Recently, text-to-image generation models have achieved remarkable advancements, particularly with diffusion models facilitating high-quality image synthesis from textual descriptions. However, these models often struggle with achieving precise control over pixel-level layouts, object appearances, and global styles when using text prompts alone. To mitigate this issue, previous works introduce conditional images as auxiliary inputs for image generation, enhancing control but typically necessitating specialized models tailored to different types of reference inputs. In this paper, we explore a new approach to unify controllable generation within a single framework. Specifically, we propose the unified image-instruction adapter (UNIC-Adapter) built on the Multi-Modal-Diffusion Transformer architecture, to enable flexible and controllable generation across diverse conditions without the need for multiple specialized models. Our UNIC-Adapter effectively extracts multi-modal instruction information by incorporating both conditional images and task instructions, injecting this information into the image generation process through a cross-attention mechanism enhanced by Rotary Position Embedding. Experimental results across a variety of tasks, including pixel-level spatial control, subject-driven image generation, and style-image-based image synthesis, demonstrate the effectiveness of our UNIC-Adapter in unified controllable image generation.
Non-target Divergence Hypothesis: Toward Understanding Domain Gaps in Cross-Modal Knowledge Distillation
Sep 04, 2024



Compared to single-modal knowledge distillation, cross-modal knowledge distillation faces more severe challenges due to domain gaps between modalities. Although various methods have proposed various solutions to overcome these challenges, there is still limited research on how domain gaps affect cross-modal knowledge distillation. This paper provides an in-depth analysis and evaluation of this issue. We first introduce the Non-Target Divergence Hypothesis (NTDH) to reveal the impact of domain gaps on cross-modal knowledge distillation. Our key finding is that domain gaps between modalities lead to distribution differences in non-target classes, and the smaller these differences, the better the performance of cross-modal knowledge distillation. Subsequently, based on Vapnik-Chervonenkis (VC) theory, we derive the upper and lower bounds of the approximation error for cross-modal knowledge distillation, thereby theoretically validating the NTDH. Finally, experiments on five cross-modal datasets further confirm the validity, generalisability, and applicability of the NTDH.
Towards Modality-agnostic Label-efficient Segmentation with Entropy-Regularized Distribution Alignment
Aug 29, 2024



Label-efficient segmentation aims to perform effective segmentation on input data using only sparse and limited ground-truth labels for training. This topic is widely studied in 3D point cloud segmentation due to the difficulty of annotating point clouds densely, while it is also essential for cost-effective segmentation on 2D images. Until recently, pseudo-labels have been widely employed to facilitate training with limited ground-truth labels, and promising progress has been witnessed in both the 2D and 3D segmentation. However, existing pseudo-labeling approaches could suffer heavily from the noises and variations in unlabelled data, which would result in significant discrepancies between generated pseudo-labels and current model predictions during training. We analyze that this can further confuse and affect the model learning process, which shows to be a shared problem in label-efficient learning across both 2D and 3D modalities. To address this issue, we propose a novel learning strategy to regularize the pseudo-labels generated for training, thus effectively narrowing the gaps between pseudo-labels and model predictions. More specifically, our method introduces an Entropy Regularization loss and a Distribution Alignment loss for label-efficient learning, resulting in an ERDA learning strategy. Interestingly, by using KL distance to formulate the distribution alignment loss, ERDA reduces to a deceptively simple cross-entropy-based loss which optimizes both the pseudo-label generation module and the segmentation model simultaneously. In addition, we innovate in the pseudo-label generation to make our ERDA consistently effective across both 2D and 3D data modalities for segmentation. Enjoying simplicity and more modality-agnostic pseudo-label generation, our method has shown outstanding performance in fully utilizing all unlabeled data points for training across ...
UniMix: Towards Domain Adaptive and Generalizable LiDAR Semantic Segmentation in Adverse Weather
Apr 08, 2024



LiDAR semantic segmentation (LSS) is a critical task in autonomous driving and has achieved promising progress. However, prior LSS methods are conventionally investigated and evaluated on datasets within the same domain in clear weather. The robustness of LSS models in unseen scenes and all weather conditions is crucial for ensuring safety and reliability in real applications. To this end, we propose UniMix, a universal method that enhances the adaptability and generalizability of LSS models. UniMix first leverages physically valid adverse weather simulation to construct a Bridge Domain, which serves to bridge the domain gap between the clear weather scenes and the adverse weather scenes. Then, a Universal Mixing operator is defined regarding spatial, intensity, and semantic distributions to create the intermediate domain with mixed samples from given domains. Integrating the proposed two techniques into a teacher-student framework, UniMix efficiently mitigates the domain gap and enables LSS models to learn weather-robust and domain-invariant representations. We devote UniMix to two main setups: 1) unsupervised domain adaption, adapting the model from the clear weather source domain to the adverse weather target domain; 2) domain generalization, learning a model that generalizes well to unseen scenes in adverse weather. Extensive experiments validate the effectiveness of UniMix across different tasks and datasets, all achieving superior performance over state-of-the-art methods. The code will be released.
Local-consistent Transformation Learning for Rotation-invariant Point Cloud Analysis
Mar 17, 2024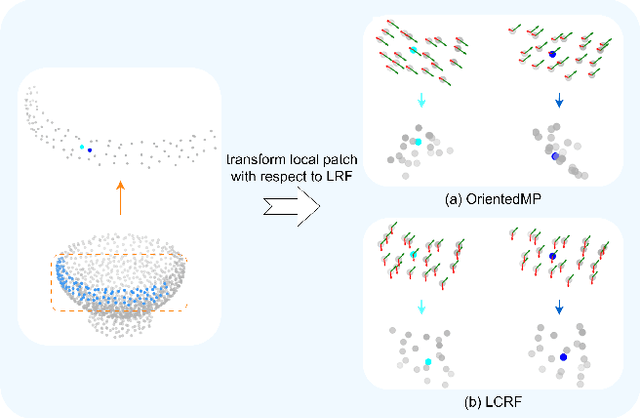
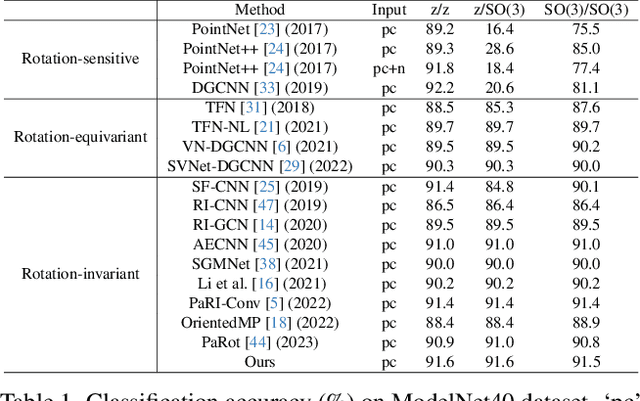
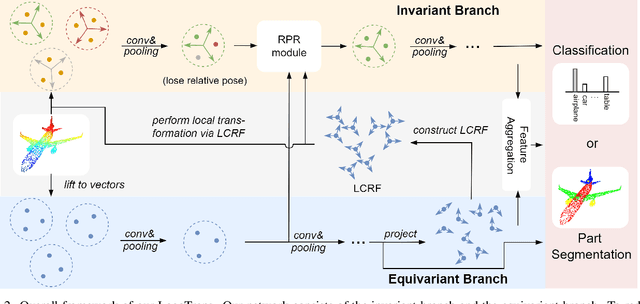
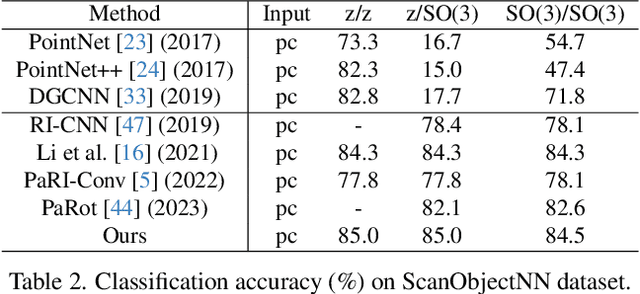
Rotation invariance is an important requirement for point shape analysis. To achieve this, current state-of-the-art methods attempt to construct the local rotation-invariant representation through learning or defining the local reference frame (LRF). Although efficient, these LRF-based methods suffer from perturbation of local geometric relations, resulting in suboptimal local rotation invariance. To alleviate this issue, we propose a Local-consistent Transformation (LocoTrans) learning strategy. Specifically, we first construct the local-consistent reference frame (LCRF) by considering the symmetry of the two axes in LRF. In comparison with previous LRFs, our LCRF is able to preserve local geometric relationships better through performing local-consistent transformation. However, as the consistency only exists in local regions, the relative pose information is still lost in the intermediate layers of the network. We mitigate such a relative pose issue by developing a relative pose recovery (RPR) module. RPR aims to restore the relative pose between adjacent transformed patches. Equipped with LCRF and RPR, our LocoTrans is capable of learning local-consistent transformation and preserving local geometry, which benefits rotation invariance learning. Competitive performance under arbitrary rotations on both shape classification and part segmentation tasks and ablations can demonstrate the effectiveness of our method. Code will be available publicly at https://github.com/wdttt/LocoTrans.