 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSC-Bench: Benchmarking and Analyzing Multi-Sensor Corruption for Driving Perception
Jan 02, 2025



Multi-sensor fusion models play a crucial role in autonomous driving perception, particularly in tasks like 3D object detection and HD map construction. These models provide essential and comprehensive static environmental information for autonomous driving systems. While camera-LiDAR fusion methods have shown promising results by integrating data from both modalities, they often depend on complete sensor inputs. This reliance can lead to low robustness and potential failures when sensors are corrupted or missing, raising significant safety concerns. To tackle this challenge, we introduce the Multi-Sensor Corruption Benchmark (MSC-Bench), the first comprehensive benchmark aimed at evaluating the robustness of multi-sensor autonomous driving perception models against various sensor corruptions. Our benchmark includes 16 combinations of corruption types that disrupt both camera and LiDAR inputs, either individually or concurrently. Extensive evaluations of six 3D object detection models and four HD map construction models reveal substantial performance degradation under adverse weather conditions and sensor failures, underscoring critical safety issues. The benchmark toolkit and affiliated code and model checkpoints have been made publicly accessible.
MapDistill: Boosting Efficient Camera-based HD Map Construction via Camera-LiDAR Fusion Model Distillation
Jul 16, 2024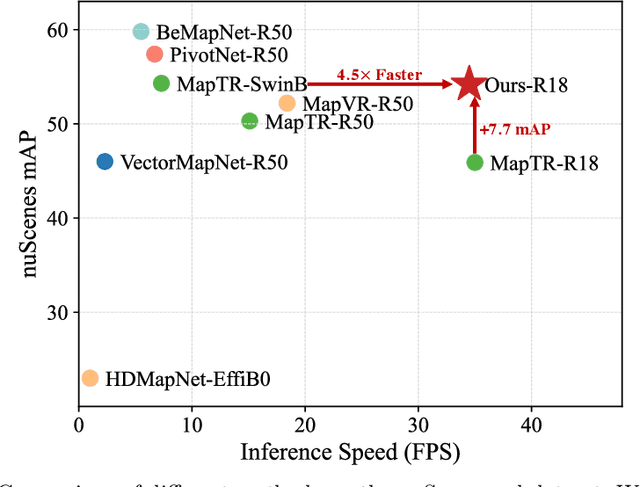
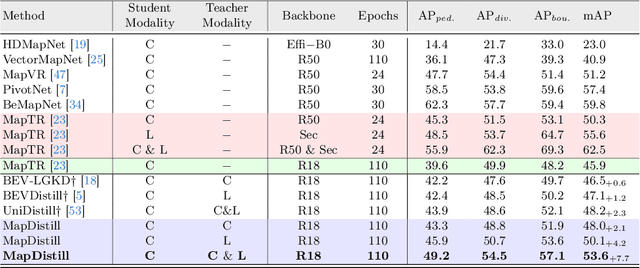
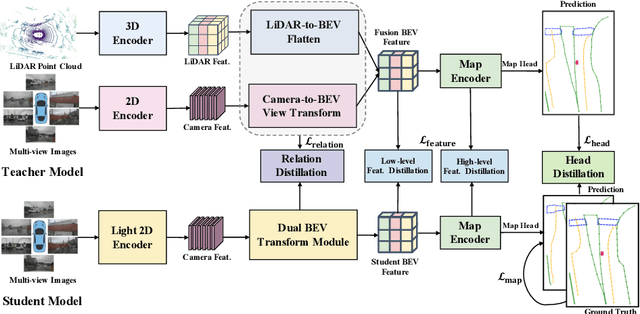
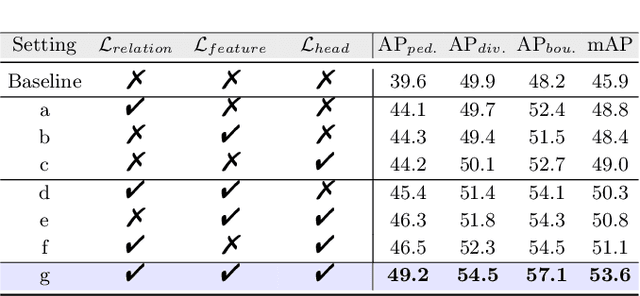
Online high-definition (HD) map construction is an important and challenging task in autonomous driving. Recently, there has been a growing interest in cost-effective multi-view camera-based methods without relying on other sensors like LiDAR. However, these methods suffer from a lack of explicit depth information, necessitating the use of large models to achieve satisfactory performance. To address this, we employ the Knowledge Distillation (KD) idea for efficient HD map construction for the first time and introduce a novel KD-based approach called MapDistill to transfer knowledge from a high-performance camera-LiDAR fusion model to a lightweight camera-only model. Specifically, we adopt the teacher-student architecture, i.e., a camera-LiDAR fusion model as the teacher and a lightweight camera model as the student, and devise a dual BEV transform module to facilitate cross-modal knowledge distillation while maintaining cost-effective camera-only deployment. Additionally, we present a comprehensive distillation scheme encompassing cross-modal relation distillation, dual-level feature distillation, and map head distillation. This approach alleviates knowledge transfer challenges between modalities, enabling the student model to learn improved feature representations for HD map construction. Experimental results on the challenging nuScenes dataset demonstrate the effectiveness of MapDistill, surpassing existing competitors by over 7.7 mAP or 4.5X speedup.
Is Your HD Map Constructor Reliable under Sensor Corruptions?
Jun 18, 2024



Driving systems often rely on high-definition (HD) maps for precise environmental information, which is crucial for planning and navigation. While current HD map constructors perform well under ideal conditions, their resilience to real-world challenges, \eg, adverse weather and sensor failures, is not well understood, raising safety concerns. This work introduces MapBench, the first comprehensive benchmark designed to evaluate the robustness of HD map construction methods against various sensor corruptions. Our benchmark encompasses a total of 29 types of corruptions that occur from cameras and LiDAR sensors. Extensive evaluations across 31 HD map constructors reveal significant performance degradation of existing methods under adverse weather conditions and sensor failures, underscoring critical safety concerns. We identify effective strategies for enhancing robustness, including innovative approaches that leverage multi-modal fusion, advanced data augmentation, and architectural techniques. These insights provide a pathway for developing more reliable HD map construction methods, which are essential for the advancement of autonomous driving technology. The benchmark toolkit and affiliated code and model checkpoints have been made publicly accessible.
Team Samsung-RAL: Technical Report for 2024 RoboDrive Challenge-Robust Map Segmentation Track
May 17, 2024



In this report, we describe the technical details of our submission to the 2024 RoboDrive Challenge Robust Map Segmentation Track. The Robust Map Segmentation track focuses on the segmentation of complex driving scene elements in BEV maps under varied driving conditions. Semantic map segmentation provides abundant and precise static environmental information crucial for autonomous driving systems' planning and navigation. While current methods excel in ideal circumstances, e.g., clear daytime conditions and fully functional sensors, their resilience to real-world challenges like adverse weather and sensor failures remains unclear, raising concerns about system safety. In this paper, we explored several methods to improve the robustness of the map segmentation task. The details are as follows: 1) Robustness analysis of utilizing temporal information; 2) Robustness analysis of utilizing different backbones; and 3) Data Augmentation to boost corruption robustness. Based on the evaluation results, we draw several important findings including 1) The temporal fusion module is effective in improving the robustness of the map segmentation model; 2) A strong backbone is effective for improving the corruption robustness; and 3) Some data augmentation methods are effective in improving the robustness of map segmentation models. These novel findings allowed us to achieve promising results in the 2024 RoboDrive Challenge-Robust Map Segmentation Track.
The RoboDrive Challenge: Drive Anytime Anywhere in Any Condition
May 14, 2024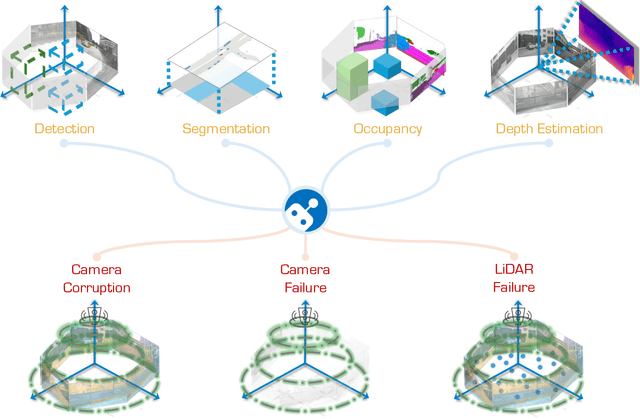


In the realm of autonomous driving, robust perception under out-of-distribution conditions is paramount for the safe deployment of vehicles. Challenges such as adverse weather, sensor malfunctions, and environmental unpredictability can severely impact the performance of autonomous systems. The 2024 RoboDrive Challenge was crafted to propel the development of driving perception technologies that can withstand and adapt to these real-world variabilities. Focusing on four pivotal tasks -- BEV detection, map segmentation, semantic occupancy prediction, and multi-view depth estimation -- the competition laid down a gauntlet to innovate and enhance system resilience against typical and atypical disturbances. This year's challenge consisted of five distinct tracks and attracted 140 registered teams from 93 institutes across 11 countries, resulting in nearly one thousand submissions evaluated through our servers. The competition culminated in 15 top-performing solutions, which introduced a range of innovative approaches including advanced data augmentation, multi-sensor fusion, self-supervised learning for error correction, and new algorithmic strategies to enhance sensor robustness. These contributions significantly advanced the state of the art, particularly in handling sensor inconsistencies and environmental variability. Participants, through collaborative efforts, pushed the boundaries of current technologies, showcasing their potential in real-world scenarios. Extensive evaluations and analyses provided insights into the effectiveness of these solutions, highlighting key trends and successful strategies for improving the resilience of driving perception systems. This challenge has set a new benchmark in the field, providing a rich repository of techniques expected to guide future research in this field.
UniMix: Towards Domain Adaptive and Generalizable LiDAR Semantic Segmentation in Adverse Weather
Apr 08, 2024



LiDAR semantic segmentation (LSS) is a critical task in autonomous driving and has achieved promising progress. However, prior LSS methods are conventionally investigated and evaluated on datasets within the same domain in clear weather. The robustness of LSS models in unseen scenes and all weather conditions is crucial for ensuring safety and reliability in real applications. To this end, we propose UniMix, a universal method that enhances the adaptability and generalizability of LSS models. UniMix first leverages physically valid adverse weather simulation to construct a Bridge Domain, which serves to bridge the domain gap between the clear weather scenes and the adverse weather scenes. Then, a Universal Mixing operator is defined regarding spatial, intensity, and semantic distributions to create the intermediate domain with mixed samples from given domains. Integrating the proposed two techniques into a teacher-student framework, UniMix efficiently mitigates the domain gap and enables LSS models to learn weather-robust and domain-invariant representations. We devote UniMix to two main setups: 1) unsupervised domain adaption, adapting the model from the clear weather source domain to the adverse weather target domain; 2) domain generalization, learning a model that generalizes well to unseen scenes in adverse weather. Extensive experiments validate the effectiveness of UniMix across different tasks and datasets, all achieving superior performance over state-of-the-art methods. The code will be released.
BEVSimDet: Simulated Multi-modal Distillation in Bird's-Eye View for Multi-view 3D Object Detection
Apr 15, 2023



Multi-view camera-based 3D object detection has gained popularity due to its low cost. But accurately inferring 3D geometry solely from camera data remains challenging, which impacts model performance. One promising approach to address this issue is to distill precise 3D geometry knowledge from LiDAR data. However, transferring knowledge between different sensor modalities is hindered by the significant modality gap. In this paper, we approach this challenge from the perspective of both architecture design and knowledge distillation and present a new simulated multi-modal 3D object detection method named BEVSimDet. We first introduce a novel framework that includes a LiDAR and camera fusion-based teacher and a simulated multi-modal student, where the student simulates multi-modal features with image-only input. To facilitate effective distillation, we propose a simulated multi-modal distillation scheme that supports intra-modal, cross-modal, and multi-modal distillation simultaneously, in Bird's-eye-view (BEV) space. By combining them together, BEVSimDet can learn better feature representations for 3D object detection while enjoying cost-effective camera-only deployment. Experimental results on the challenging nuScenes benchmark demonstrate the effectiveness and superiority of BEVSimDet over recent representative methods. The source code will be released at \href{https://github.com/ViTAE-Transformer/BEVSimDet}{BEVSimDet}.
On Robust Cross-View Consistency in Self-Supervised Monocular Depth Estimation
Sep 19, 2022
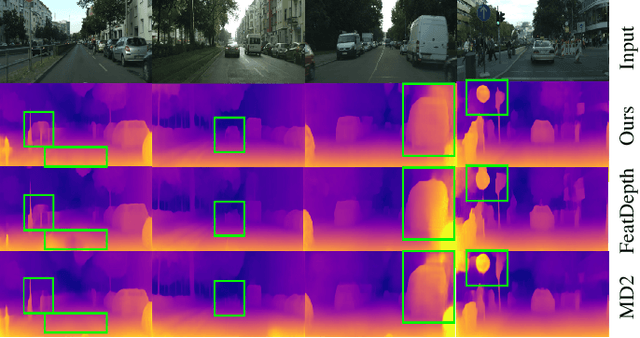


Remarkable progress has been made in self-supervised monocular depth estimation (SS-MDE) by exploring cross-view consistency, e.g., photometric consistency and 3D point cloud consistency. However, they are very vulnerable to illumination variance, occlusions, texture-less regions, as well as moving objects, making them not robust enough to deal with various scenes. To address this challenge, we study two kinds of robust cross-view consistency in this paper. Firstly, the spatial offset field between adjacent frames is obtained by reconstructing the reference frame from its neighbors via deformable alignment, which is used to align the temporal depth features via a Depth Feature Alignment (DFA) loss. Secondly, the 3D point clouds of each reference frame and its nearby frames are calculated and transformed into voxel space, where the point density in each voxel is calculated and aligned via a Voxel Density Alignment (VDA) loss. In this way, we exploit the temporal coherence in both depth feature space and 3D voxel space for SS-MDE, shifting the "point-to-point" alignment paradigm to the "region-to-region" one. Compared with the photometric consistency loss as well as the rigid point cloud alignment loss, the proposed DFA and VDA losses are more robust owing to the strong representation power of deep features as well as the high tolerance of voxel density to the aforementioned challenges. Experimental results on several outdoor benchmarks show that our method outperforms current state-of-the-art techniques. Extensive ablation study and analysis validate the effectiveness of the proposed losses, especially in challenging scenes. The code and models are available at https://github.com/sunnyHelen/RCVC-depth.
JPerceiver: Joint Perception Network for Depth, Pose and Layout Estimation in Driving Scenes
Jul 16, 2022
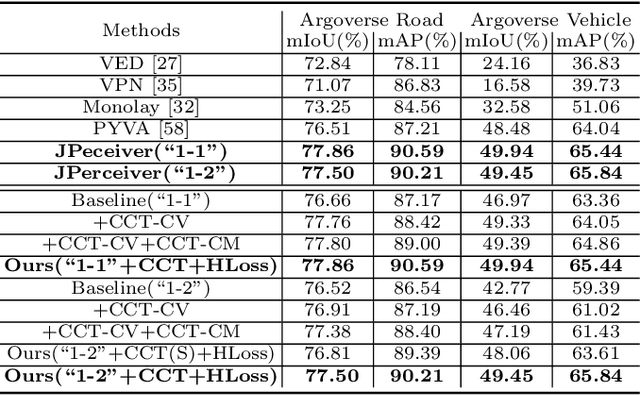
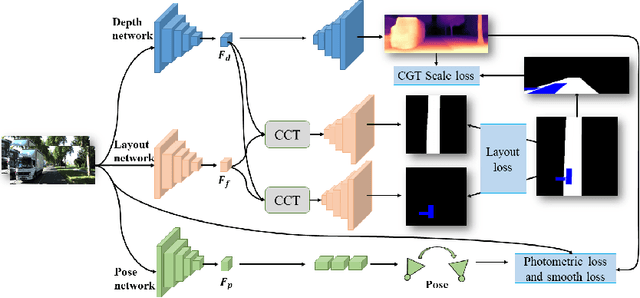
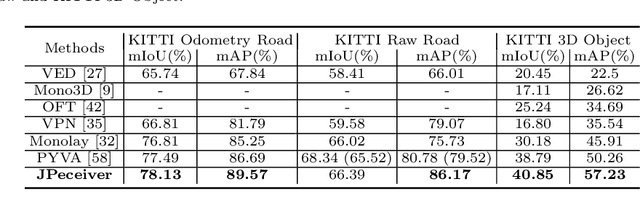
Depth estimation, visual odometry (VO), and bird's-eye-view (BEV) scene layout estimation present three critical tasks for driving scene perception, which is fundamental for motion planning and navigation in autonomous driving. Though they are complementary to each other, prior works usually focus on each individual task and rarely deal with all three tasks together. A naive way is to accomplish them independently in a sequential or parallel manner, but there are many drawbacks, i.e., 1) the depth and VO results suffer from the inherent scale ambiguity issue; 2) the BEV layout is directly predicted from the front-view image without using any depth-related information, although the depth map contains useful geometry clues for inferring scene layouts. In this paper, we address these issues by proposing a novel joint perception framework named JPerceiver, which can simultaneously estimate scale-aware depth and VO as well as BEV layout from a monocular video sequence. It exploits the cross-view geometric transformation (CGT) to propagate the absolute scale from the road layout to depth and VO based on a carefully-designed scale loss. Meanwhile, a cross-view and cross-modal transfer (CCT) module is devised to leverage the depth clues for reasoning road and vehicle layout through an attention mechanism. JPerceiver can be trained in an end-to-end multi-task learning way, where the CGT scale loss and CCT module promote inter-task knowledge transfer to benefit feature learning of each task. Experiments on Argoverse, Nuscenes and KITTI show the superiority of JPerceiver over existing methods on all the above three tasks in terms of accuracy, model size, and inference speed. The code and models are available at~\href{https://github.com/sunnyHelen/JPerceiver}{https://github.com/sunnyHelen/JPerceiver}.