 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Robust Cross-View Consistency in Self-Supervised Monocular Depth Estimation
Paper and Code

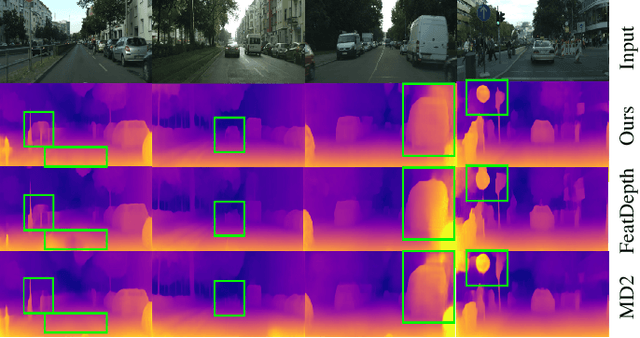


Remarkable progress has been made in self-supervised monocular depth estimation (SS-MDE) by exploring cross-view consistency, e.g., photometric consistency and 3D point cloud consistency. However, they are very vulnerable to illumination variance, occlusions, texture-less regions, as well as moving objects, making them not robust enough to deal with various scenes. To address this challenge, we study two kinds of robust cross-view consistency in this paper. Firstly, the spatial offset field between adjacent frames is obtained by reconstructing the reference frame from its neighbors via deformable alignment, which is used to align the temporal depth features via a Depth Feature Alignment (DFA) loss. Secondly, the 3D point clouds of each reference frame and its nearby frames are calculated and transformed into voxel space, where the point density in each voxel is calculated and aligned via a Voxel Density Alignment (VDA) loss. In this way, we exploit the temporal coherence in both depth feature space and 3D voxel space for SS-MDE, shifting the "point-to-point" alignment paradigm to the "region-to-region" one. Compared with the photometric consistency loss as well as the rigid point cloud alignment loss, the proposed DFA and VDA losses are more robust owing to the strong representation power of deep features as well as the high tolerance of voxel density to the aforementioned challenges. Experimental results on several outdoor benchmarks show that our method outperforms current state-of-the-art techniques. Extensive ablation study and analysis validate the effectiveness of the proposed losses, especially in challenging scenes. The code and models are available at https://github.com/sunnyHelen/RCVC-depth.