 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePRM-as-a-Judge: A Dense Evaluation Paradigm for Fine-Grained Robotic Auditing
Mar 23, 2026Current robotic evaluation is still largely dominated by binary success rates, which collapse rich execution processes into a single outcome and obscure critical qualities such as progress, efficiency, and stability. To address this limitation, we propose PRM-as-a-Judge, a dense evaluation paradigm that leverages Process Reward Models (PRMs) to audit policy execution directly from trajectory videos by estimating task progress from observation sequences. Central to this paradigm is the OPD (Outcome-Process-Diagnosis) metric system, which explicitly formalizes execution quality via a task-aligned progress potential. We characterize dense robotic evaluation through two axiomatic properties: macro-consistency, which requires additive and path-consistent aggregation, and micro-resolution, which requires sensitivity to fine-grained physical evolution. Under this formulation, potential-based PRM judges provide a natural instantiation of dense evaluation, with macro-consistency following directly from the induced scalar potential. We empirically validate the micro-resolution property using RoboPulse, a diagnostic benchmark specifically designed for probing micro-scale progress discrimination, where several trajectory-trained PRM judges outperform discriminative similarity-based methods and general-purpose foundation-model judges. Finally, leveraging PRM-as-a-Judge and the OPD metric system, we conduct a structured audit of mainstream policy paradigms across long-horizon tasks, revealing behavioral signatures and failure modes that are invisible to outcome-only metrics.
MathSticks: A Benchmark for Visual Symbolic Compositional Reasoning with Matchstick Puzzles
Oct 01, 2025We introduce \textsc{MathSticks}, a benchmark for Visual Symbolic Compositional Reasoning (VSCR), which unifies visual perception, symbolic manipulation, and arithmetic consistency. Each task presents an incorrect matchstick equation that must be corrected by moving one or two sticks under strict conservation rules. The benchmark includes both text-guided and purely visual settings, systematically covering digit scale, move complexity, solution multiplicity, and operator variation, with 1.4M generated instances and a curated test set. Evaluations of 14 vision--language models reveal substantial limitations: closed-source models succeed only on simple cases, open-source models fail in the visual regime, while humans exceed 90\% accuracy. These findings establish \textsc{MathSticks} as a rigorous testbed for advancing compositional reasoning across vision and symbols. Our code and dataset are publicly available at https://github.com/Yuheng2000/MathSticks.
VisualTrans: A Benchmark for Real-World Visual Transformation Reasoning
Aug 06, 2025Visual transformation reasoning (VTR) is a vital cognitive capability that empowers intelligent agents to understand dynamic scenes, model causal relationships, and predict future states, and thereby guiding actions and laying the foundation for advanced intelligent systems. However, existing benchmarks suffer from a sim-to-real gap, limited task complexity, and incomplete reasoning coverage, limiting their practical use in real-world scenarios. To address these limitations, we introduce VisualTrans, the first comprehensive benchmark specifically designed for VTR in real-world human-object interaction scenarios. VisualTrans encompasses 12 semantically diverse manipulation tasks and systematically evaluates three essential reasoning dimensions - spatial, procedural, and quantitative - through 6 well-defined subtask types. The benchmark features 472 high-quality question-answer pairs in various formats, including multiple-choice, open-ended counting, and target enumeration. We introduce a scalable data construction pipeline built upon first-person manipulation videos, which integrates task selection, image pair extraction, automated metadata annotation with large multimodal models, and structured question generation. Human verification ensures the final benchmark is both high-quality and interpretable. Evaluations of various state-of-the-art vision-language models show strong performance in static spatial tasks. However, they reveal notable shortcomings in dynamic, multi-step reasoning scenarios, particularly in areas like intermediate state recognition and transformation sequence planning. These findings highlight fundamental weaknesses in temporal modeling and causal reasoning, providing clear directions for future research aimed at developing more capable and generalizable VTR systems. The dataset and code are available at https://github.com/WangYipu2002/VisualTrans.
Exploring Task Performance with Interpretable Models via Sparse Auto-Encoders
Jul 08, 2025



Large Language Models (LLMs) are traditionally viewed as black-box algorithms, therefore reducing trustworthiness and obscuring potential approaches to increasing performance on downstream tasks. In this work, we apply an effective LLM decomposition method using a dictionary-learning approach with sparse autoencoders. This helps extract monosemantic features from polysemantic LLM neurons. Remarkably, our work identifies model-internal misunderstanding, allowing the automatic reformulation of the prompts with additional annotations to improve the interpretation by LLMs. Moreover, this approach demonstrates a significant performance improvement in downstream tasks, such as mathematical reasoning and metaphor detection.
What Really Matters for Robust Multi-Sensor HD Map Construction?
Jul 02, 2025High-definition (HD) map construction methods are crucial for providing precise and comprehensive static environmental information, which is essential for autonomous driving systems. While Camera-LiDAR fusion techniques have shown promising results by integrating data from both modalities, existing approaches primarily focus on improving model accuracy and often neglect the robustness of perception models, which is a critical aspect for real-world applications. In this paper, we explore strategies to enhance the robustness of multi-modal fusion methods for HD map construction while maintaining high accuracy. We propose three key components: data augmentation, a novel multi-modal fusion module, and a modality dropout training strategy. These components are evaluated on a challenging dataset containing 10 days of NuScenes data. Our experimental results demonstrate that our proposed methods significantly enhance the robustness of baseline methods. Furthermore, our approach achieves state-of-the-art performance on the clean validation set of the NuScenes dataset. Our findings provide valuable insights for developing more robust and reliable HD map construction models, advancing their applicability in real-world autonomous driving scenarios. Project website: https://robomap-123.github.io.
FastRSR: Efficient and Accurate Road Surface Reconstruction from Bird's Eye View
Apr 13, 2025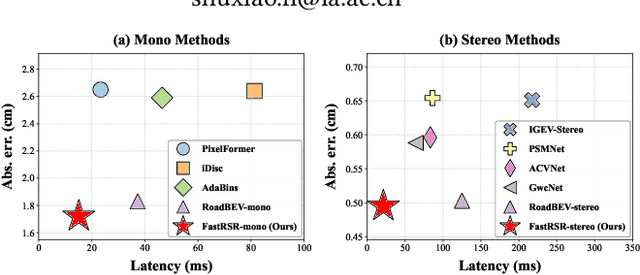
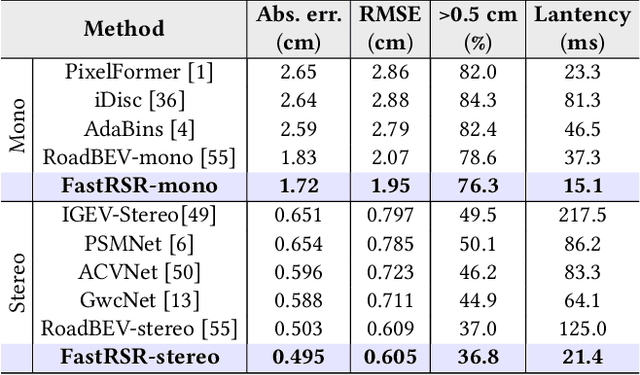
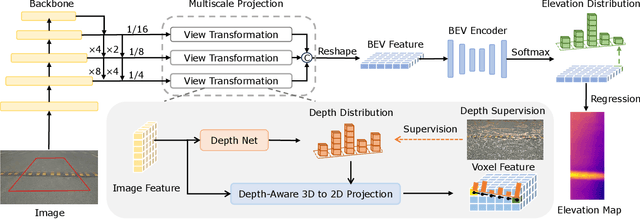
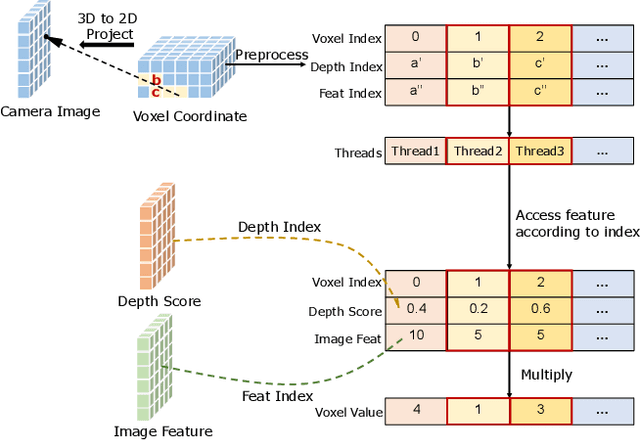
Road Surface Reconstruction (RSR) is crucial for autonomous driving, enabling the understanding of road surface conditions. Recently, RSR from the Bird's Eye View (BEV) has gained attention for its potential to enhance performance. However, existing methods for transforming perspective views to BEV face challenges such as information loss and representation sparsity. Moreover, stereo matching in BEV is limited by the need to balance accuracy with inference speed. To address these challenges, we propose two efficient and accurate BEV-based RSR models: FastRSR-mono and FastRSR-stereo. Specifically, we first introduce Depth-Aware Projection (DAP), an efficient view transformation strategy designed to mitigate information loss and sparsity by querying depth and image features to aggregate BEV data within specific road surface regions using a pre-computed look-up table. To optimize accuracy and speed in stereo matching, we design the Spatial Attention Enhancement (SAE) and Confidence Attention Generation (CAG) modules. SAE adaptively highlights important regions, while CAG focuses on high-confidence predictions and filters out irrelevant information. FastRSR achieves state-of-the-art performance, exceeding monocular competitors by over 6.0% in elevation absolute error and providing at least a 3.0x speedup by stereo methods on the RSRD dataset. The source code will be released.
MSC-Bench: Benchmarking and Analyzing Multi-Sensor Corruption for Driving Perception
Jan 02, 2025



Multi-sensor fusion models play a crucial role in autonomous driving perception, particularly in tasks like 3D object detection and HD map construction. These models provide essential and comprehensive static environmental information for autonomous driving systems. While camera-LiDAR fusion methods have shown promising results by integrating data from both modalities, they often depend on complete sensor inputs. This reliance can lead to low robustness and potential failures when sensors are corrupted or missing, raising significant safety concerns. To tackle this challenge, we introduce the Multi-Sensor Corruption Benchmark (MSC-Bench), the first comprehensive benchmark aimed at evaluating the robustness of multi-sensor autonomous driving perception models against various sensor corruptions. Our benchmark includes 16 combinations of corruption types that disrupt both camera and LiDAR inputs, either individually or concurrently. Extensive evaluations of six 3D object detection models and four HD map construction models reveal substantial performance degradation under adverse weather conditions and sensor failures, underscoring critical safety issues. The benchmark toolkit and affiliated code and model checkpoints have been made publicly accessible.
AdvLoRA: Adversarial Low-Rank Adaptation of Vision-Language Models
Apr 20, 2024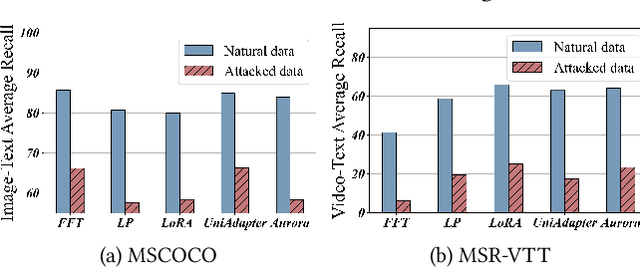



Vision-Language Models (VLMs) are a significant technique for Artificial General Intelligence (AGI). With the fast growth of AGI, the security problem become one of the most important challenges for VLMs. In this paper, through extensive experiments, we demonstrate the vulnerability of the conventional adaptation methods for VLMs, which may bring significant security risks. In addition, as the size of the VLMs increases, performing conventional adversarial adaptation techniques on VLMs results in high computational costs. To solve these problems, we propose a parameter-efficient \underline{Adv}ersarial adaptation method named \underline{AdvLoRA} by \underline{Lo}w-\underline{R}ank \underline{A}daptation. At first, we investigate and reveal the intrinsic low-rank property during the adversarial adaptation for VLMs. Different from LoRA, we improve the efficiency and robustness of adversarial adaptation by designing a novel reparameterizing method based on parameter clustering and parameter alignment. In addition, an adaptive parameter update strategy is proposed to further improve the robustness. By these settings, our proposed AdvLoRA alleviates the model security and high resource waste problems. Extensive experiments demonstrate the effectiveness and efficiency of the AdvLoRA.