 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Autoencoders for Interpretable Emotion Control in Text-to-Speech
May 31, 2026Integrating large language models (LLMs) into text-to-speech (TTS) systems has improved speech expressiveness, yet interpretable emotional control remains challenging. Existing approaches primarily rely on external conditioning or global activation steering, offering limited insight into the internal representations underlying emotional control. In this work, we analyze emotion-related variation in the semantic hidden states of LLM-based TTS models using sparse autoencoders (SAEs) to identify sparse latent features. Our analysis shows that emotional variation is distributed across multiple sparse latent features, while intervening on a small subset enables interpretable emotion control. Building on this observation, we introduce a feature-level intervention framework for bidirectional emotion induction and suppression without modifying backbone parameters. We further show that distinct latent features are associated with specific acoustic attributes (e.g., pitch), suggesting that emotional expression arises from coordinated latent contributions rather than a single global shift. Empirically, steering these sparse latent features achieves comparable or superior emotion induction and suppression performance relative to global steering and existing TTS baselines.
IMUVIE: Pickup Timeline Action Localization via Motion Movies
Nov 19, 2024



Falls among seniors due to difficulties with tasks such as picking up objects pose significant health and safety risks, impacting quality of life and independence. Reliable, accessible assessment tools are critical for early intervention but often require costly clinic-based equipment and trained personnel, limiting their use in daily life. Existing wearable-based pickup measurement solutions address some needs but face limitations in generalizability. We present IMUVIE, a wearable system that uses motion movies and a machine-learning model to automatically detect and measure pickup events, providing a practical solution for frequent monitoring. IMUVIE's design principles-data normalization, occlusion handling, and streamlined visuals-enhance model performance and are adaptable to tasks beyond pickup classification. In rigorous leave one subject out cross validation evaluations, IMUVIE achieves exceptional window level localization accuracy of 91-92% for pickup action classification on 256,291 motion movie frame candidates while maintaining an event level recall of 97% when evaluated on 129 pickup events. IMUVIE has strong generalization and performs well on unseen subjects. In an interview survey, IMUVIE demonstrated strong user interest and trust, with ease of use identified as the most critical factor for adoption. IMUVIE offers a practical, at-home solution for fall risk assessment, facilitating early detection of movement deterioration, and supporting safer, independent living for seniors.
GPT-based Textile Pilling Classification Using 3D Point Cloud Data
Aug 20, 2024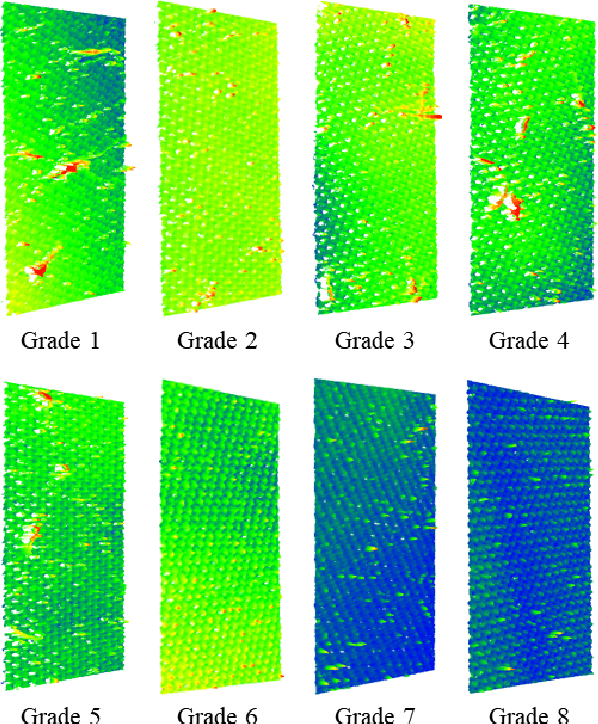



Textile pilling assessment is critical for textile quality control. We collect thousands of 3D point cloud images in the actual test environment of textiles and organize and label them as TextileNet8 dataset. To the best of our knowledge, it is the first publicly available eight-categories 3D point cloud dataset in the field of textile pilling assessment. Based on PointGPT, the GPT-like big model of point cloud analysis, we incorporate the global features of the input point cloud extracted from the non-parametric network into it, thus proposing the PointGPT+NN model. Using TextileNet8 as a benchmark, the experimental results show that the proposed PointGPT+NN model achieves an overall accuracy (OA) of 91.8% and a mean per-class accuracy (mAcc) of 92.2%. Test results on other publicly available datasets also validate the competitive performance of the proposed PointGPT+NN model. The proposed TextileNet8 dataset will be publicly available.
AdvLoRA: Adversarial Low-Rank Adaptation of Vision-Language Models
Apr 20, 2024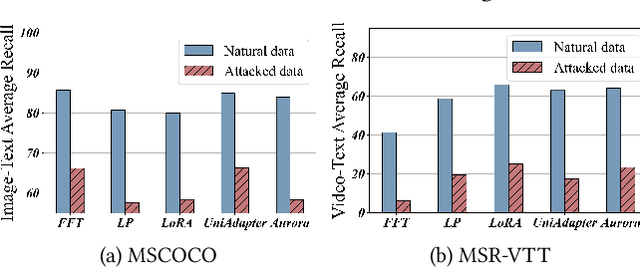



Vision-Language Models (VLMs) are a significant technique for Artificial General Intelligence (AGI). With the fast growth of AGI, the security problem become one of the most important challenges for VLMs. In this paper, through extensive experiments, we demonstrate the vulnerability of the conventional adaptation methods for VLMs, which may bring significant security risks. In addition, as the size of the VLMs increases, performing conventional adversarial adaptation techniques on VLMs results in high computational costs. To solve these problems, we propose a parameter-efficient \underline{Adv}ersarial adaptation method named \underline{AdvLoRA} by \underline{Lo}w-\underline{R}ank \underline{A}daptation. At first, we investigate and reveal the intrinsic low-rank property during the adversarial adaptation for VLMs. Different from LoRA, we improve the efficiency and robustness of adversarial adaptation by designing a novel reparameterizing method based on parameter clustering and parameter alignment. In addition, an adaptive parameter update strategy is proposed to further improve the robustness. By these settings, our proposed AdvLoRA alleviates the model security and high resource waste problems. Extensive experiments demonstrate the effectiveness and efficiency of the AdvLoRA.
SANDFORMER: CNN and Transformer under Gated Fusion for Sand Dust Image Restoration
Mar 08, 2023Although Convolutional Neural Networks (CNN) have made good progress in image restoration, the intrinsic equivalence and locality of convolutions still constrain further improvements in image quality. Recent vision transformer and self-attention have achieved promising results on various computer vision tasks. However, directly utilizing Transformer for image restoration is a challenging task. In this paper, we introduce an effective hybrid architecture for sand image restoration tasks, which leverages local features from CNN and long-range dependencies captured by transformer to improve the results further. We propose an efficient hybrid structure for sand dust image restoration to solve the feature inconsistency issue between Transformer and CNN. The framework complements each representation by modulating features from the CNN-based and Transformer-based branches rather than simply adding or concatenating features. Experiments demonstrate that SandFormer achieves significant performance improvements in synthetic and real dust scenes compared to previous sand image restoration methods.
GRIM: A General, Real-Time Deep Learning Inference Framework for Mobile Devices based on Fine-Grained Structured Weight Sparsity
Aug 25, 2021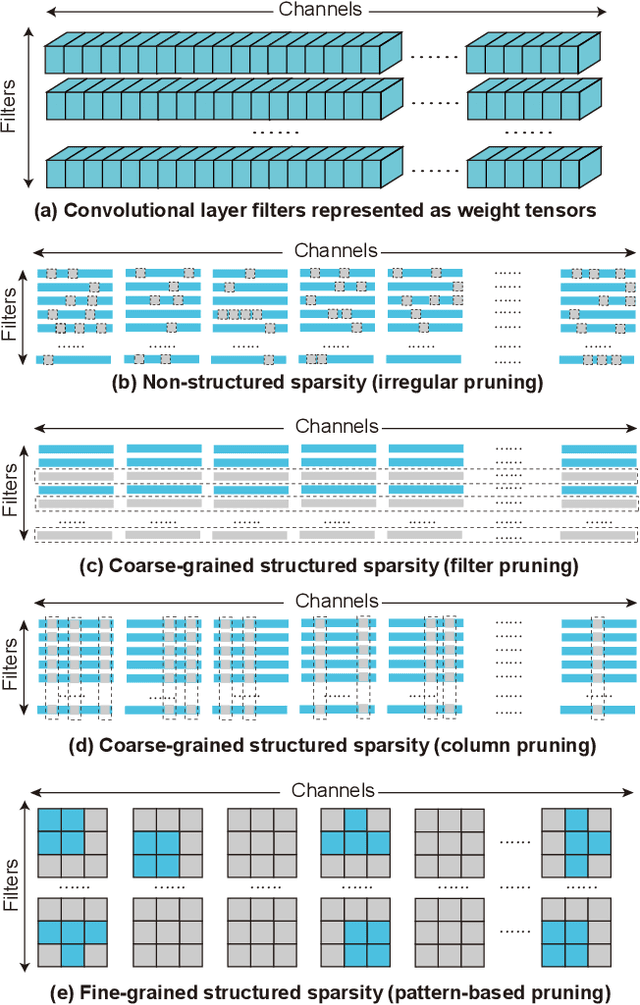
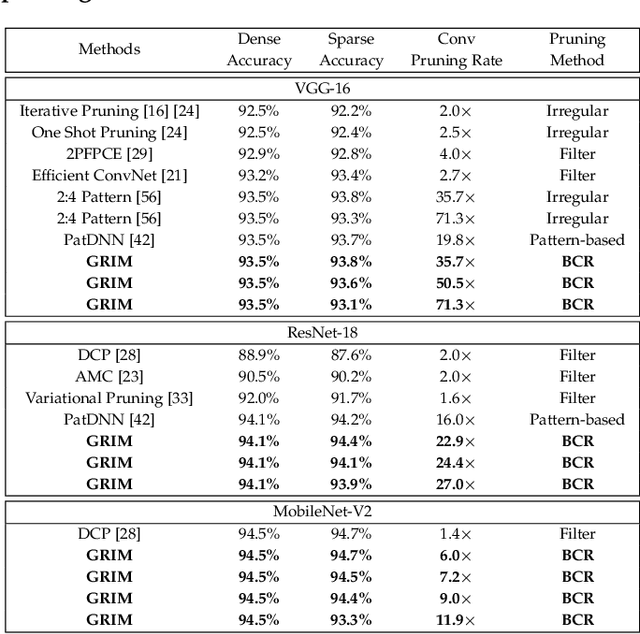
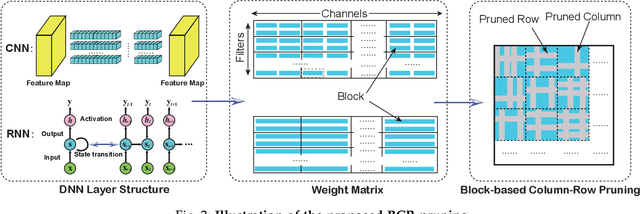
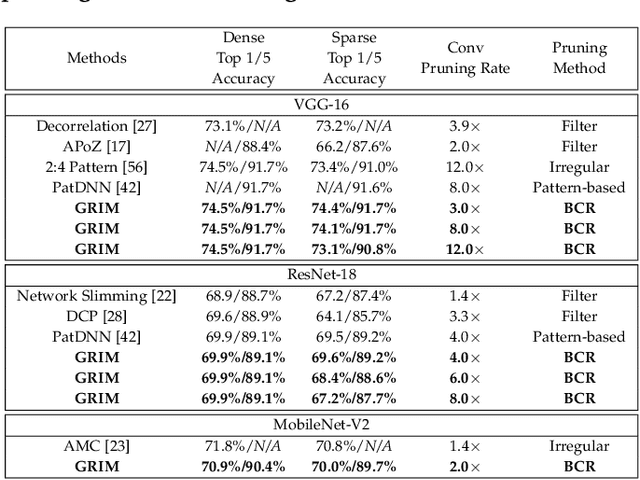
It is appealing but challenging to achieve real-time deep neural network (DNN) inference on mobile devices because even the powerful modern mobile devices are considered as ``resource-constrained'' when executing large-scale DNNs. It necessitates the sparse model inference via weight pruning, i.e., DNN weight sparsity, and it is desirable to design a new DNN weight sparsity scheme that can facilitate real-time inference on mobile devices while preserving a high sparse model accuracy. This paper designs a novel mobile inference acceleration framework GRIM that is General to both convolutional neural networks (CNNs) and recurrent neural networks (RNNs) and that achieves Real-time execution and high accuracy, leveraging fine-grained structured sparse model Inference and compiler optimizations for Mobiles. We start by proposing a new fine-grained structured sparsity scheme through the Block-based Column-Row (BCR) pruning. Based on this new fine-grained structured sparsity, our GRIM framework consists of two parts: (a) the compiler optimization and code generation for real-time mobile inference; and (b) the BCR pruning optimizations for determining pruning hyperparameters and performing weight pruning. We compare GRIM with Alibaba MNN, TVM, TensorFlow-Lite, a sparse implementation based on CSR, PatDNN, and ESE (a representative FPGA inference acceleration framework for RNNs), and achieve up to 14.08x speedup.
DeepAuditor: Distributed Online Intrusion Detection System for IoT devices via Power Side-channel Auditing
Jun 24, 2021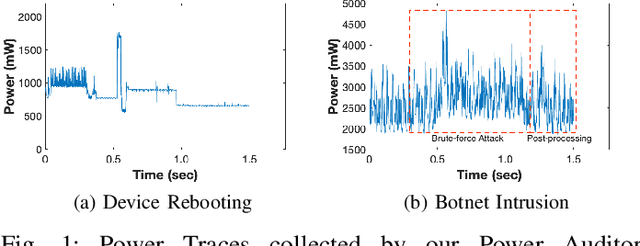
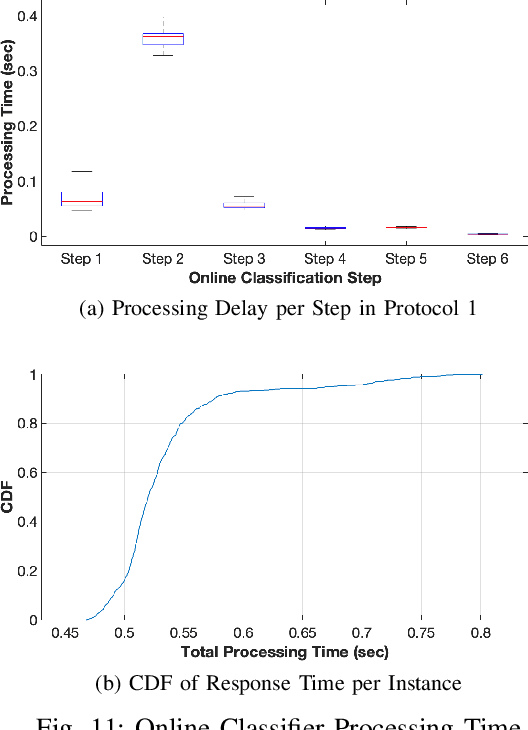
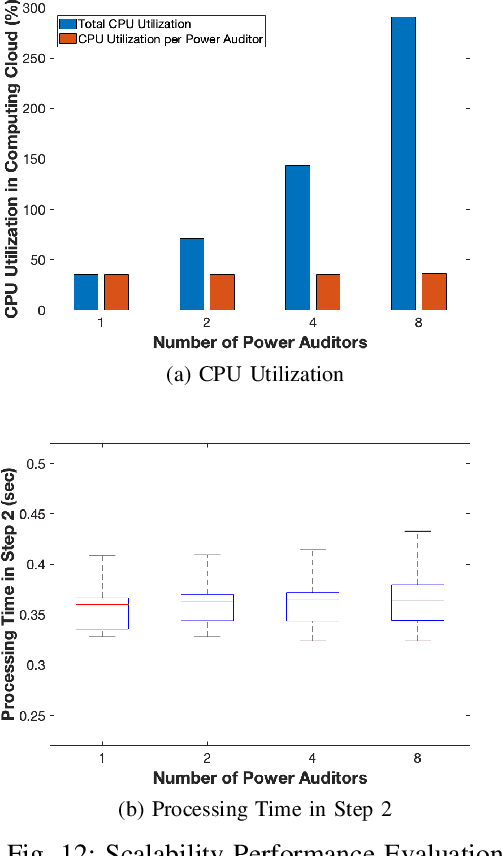
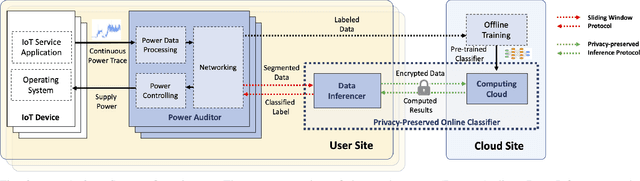
As the number of IoT devices has increased rapidly, IoT botnets have exploited the vulnerabilities of IoT devices. However, it is still challenging to detect the initial intrusion on IoT devices prior to massive attacks. Recent studies have utilized power side-channel information to characterize this intrusion behavior on IoT devices but still lack real-time detection approaches. This study aimed to design an online intrusion detection system called DeepAuditor for IoT devices via power auditing. To realize the real-time system, we first proposed a lightweight power auditing device called Power Auditor. With the Power Auditor, we developed a Distributed CNN classifier for online inference in our laboratory setting. In order to protect data leakage and reduce networking redundancy, we also proposed a privacy-preserved inference protocol via Packed Homomorphic Encryption and a sliding window protocol in our system. The classification accuracy and processing time were measured in our laboratory settings. We also demonstrated that the distributed CNN design is secure against any distributed components. Overall, the measurements were shown to the feasibility of our real-time distributed system for intrusion detection on IoT devices.