 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeoMotionGPT: Geometry-Aligned Motion Understanding with Large Language Models
Jan 12, 2026Discrete motion tokenization has recently enabled Large Language Models (LLMs) to serve as versatile backbones for motion understanding and motion-language reasoning. However, existing pipelines typically decouple motion quantization from semantic embedding learning, linking them solely via token IDs. This approach fails to effectively align the intrinsic geometry of the motion space with the embedding space, thereby hindering the LLM's capacity for nuanced motion reasoning. We argue that alignment is most effective when both modalities share a unified geometric basis. Therefore, instead of forcing the LLM to reconstruct the complex geometry among motion tokens from scratch, we present a novel framework that explicitly enforces orthogonality on both the motion codebook and the LLM embedding space, ensuring that their relational structures naturally mirror each other. Specifically, we employ a decoder-only quantizer with Gumbel-Softmax for differentiable training and balanced codebook usage. To bridge the modalities, we use a sparse projection that maps motion codes into the LLM embedding space while preserving orthogonality. Finally, a two-stage orthonormal regularization schedule enforces soft constraints during tokenizer training and LLM fine-tuning to maintain geometric alignment without hindering semantic adaptation. Extensive experiments on HumanML3D demonstrate that our framework achieves a 20% performance improvement over current state-of-the-art methods, validating that a unified geometric basis effectively empowers the LLM for nuanced motion reasoning.
Integrating Neural Differential Forecasting with Safe Reinforcement Learning for Blood Glucose Regulation
Nov 16, 2025Automated insulin delivery for Type 1 Diabetes must balance glucose control and safety under uncertain meals and physiological variability. While reinforcement learning (RL) enables adaptive personalization, existing approaches struggle to simultaneously guarantee safety, leaving a gap in achieving both personalized and risk-aware glucose control, such as overdosing before meals or stacking corrections. To bridge this gap, we propose TSODE, a safety-aware controller that integrates Thompson Sampling RL with a Neural Ordinary Differential Equation (NeuralODE) forecaster to address this challenge. Specifically, the NeuralODE predicts short-term glucose trajectories conditioned on proposed insulin doses, while a conformal calibration layer quantifies predictive uncertainty to reject or scale risky actions. In the FDA-approved UVa/Padova simulator (adult cohort), TSODE achieved 87.9% time-in-range with less than 10% time below 70 mg/dL, outperforming relevant baselines. These results demonstrate that integrating adaptive RL with calibrated NeuralODE forecasting enables interpretable, safe, and robust glucose regulation.
HCNQA: Enhancing 3D VQA with Hierarchical Concentration Narrowing Supervision
Jul 02, 20253D Visual Question-Answering (3D VQA) is pivotal for models to perceive the physical world and perform spatial reasoning. Answer-centric supervision is a commonly used training method for 3D VQA models. Many models that utilize this strategy have achieved promising results in 3D VQA tasks. However, the answer-centric approach only supervises the final output of models and allows models to develop reasoning pathways freely. The absence of supervision on the reasoning pathway enables the potential for developing superficial shortcuts through common patterns in question-answer pairs. Moreover, although slow-thinking methods advance large language models, they suffer from underthinking. To address these issues, we propose \textbf{HCNQA}, a 3D VQA model leveraging a hierarchical concentration narrowing supervision method. By mimicking the human process of gradually focusing from a broad area to specific objects while searching for answers, our method guides the model to perform three phases of concentration narrowing through hierarchical supervision. By supervising key checkpoints on a general reasoning pathway, our method can ensure the development of a rational and effective reasoning pathway. Extensive experimental results demonstrate that our method can effectively ensure that the model develops a rational reasoning pathway and performs better. The code is available at https://github.com/JianuoZhu/HCNQA.
Safe Screening Rules for Group SLOPE
Jun 11, 2025Variable selection is a challenging problem in high-dimensional sparse learning, especially when group structures exist. Group SLOPE performs well for the adaptive selection of groups of predictors. However, the block non-separable group effects in Group SLOPE make existing methods either invalid or inefficient. Consequently, Group SLOPE tends to incur significant computational costs and memory usage in practical high-dimensional scenarios. To overcome this issue, we introduce a safe screening rule tailored for the Group SLOPE model, which efficiently identifies inactive groups with zero coefficients by addressing the block non-separable group effects. By excluding these inactive groups during training, we achieve considerable gains in computational efficiency and memory usage. Importantly, the proposed screening rule can be seamlessly integrated into existing solvers for both batch and stochastic algorithms. Theoretically, we establish that our screening rule can be safely employed with existing optimization algorithms, ensuring the same results as the original approaches. Experimental results confirm that our method effectively detects inactive feature groups and significantly boosts computational efficiency without compromising accuracy.
HiSin: Efficient High-Resolution Sinogram Inpainting via Resolution-Guided Progressive Inference
Jun 10, 2025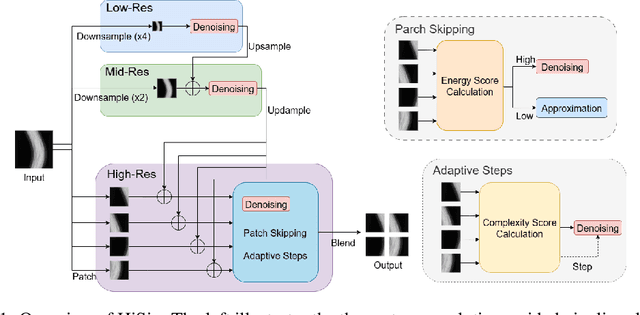
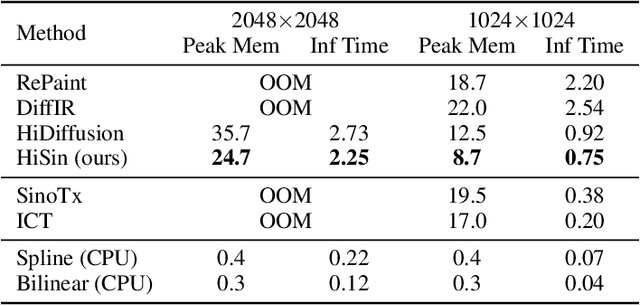
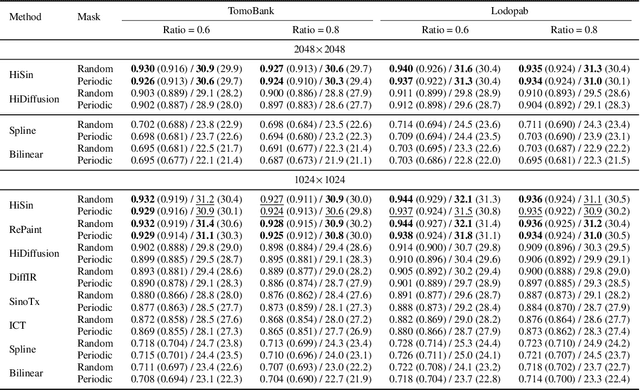
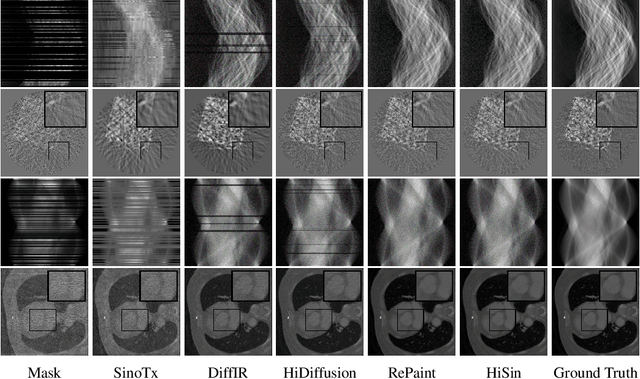
High-resolution sinogram inpainting is essential for computed tomography reconstruction, as missing high-frequency projections can lead to visible artifacts and diagnostic errors. Diffusion models are well-suited for this task due to their robustness and detail-preserving capabilities, but their application to high-resolution inputs is limited by excessive memory and computational demands. To address this limitation, we propose HiSin, a novel diffusion based framework for efficient sinogram inpainting via resolution-guided progressive inference. It progressively extracts global structure at low resolution and defers high-resolution inference to small patches, enabling memory-efficient inpainting. It further incorporates frequency-aware patch skipping and structure-adaptive step allocation to reduce redundant computation. Experimental results show that HiSin reduces peak memory usage by up to 31.25% and inference time by up to 18.15%, and maintains inpainting accuracy across datasets, resolutions, and mask conditions.
Explore the vulnerability of black-box models via diffusion models
Jun 09, 2025



Recent advancements in diffusion models have enabled high-fidelity and photorealistic image generation across diverse applications. However, these models also present security and privacy risks, including copyright violations, sensitive information leakage, and the creation of harmful or offensive content that could be exploited maliciously. In this study, we uncover a novel security threat where an attacker leverages diffusion model APIs to generate synthetic images, which are then used to train a high-performing substitute model. This enables the attacker to execute model extraction and transfer-based adversarial attacks on black-box classification models with minimal queries, without needing access to the original training data. The generated images are sufficiently high-resolution and diverse to train a substitute model whose outputs closely match those of the target model. Across the seven benchmarks, including CIFAR and ImageNet subsets, our method shows an average improvement of 27.37% over state-of-the-art methods while using just 0.01 times of the query budget, achieving a 98.68% success rate in adversarial attacks on the target model.
Safe Screening Rules for Group OWL Models
Apr 08, 2025Group Ordered Weighted $L_{1}$-Norm (Group OWL) regularized models have emerged as a useful procedure for high-dimensional sparse multi-task learning with correlated features. Proximal gradient methods are used as standard approaches to solving Group OWL models. However, Group OWL models usually suffer huge computational costs and memory usage when the feature size is large in the high-dimensional scenario. To address this challenge, in this paper, we are the first to propose the safe screening rule for Group OWL models by effectively tackling the structured non-separable penalty, which can quickly identify the inactive features that have zero coefficients across all the tasks. Thus, by removing the inactive features during the training process, we may achieve substantial computational gain and memory savings. More importantly, the proposed screening rule can be directly integrated with the existing solvers both in the batch and stochastic settings. Theoretically, we prove our screening rule is safe and also can be safely applied to the existing iterative optimization algorithms. Our experimental results demonstrate that our screening rule can effectively identify the inactive features and leads to a significant computational speedup without any loss of accuracy.
RoboReflect: Robotic Reflective Reasoning for Grasping Ambiguous-Condition Objects
Jan 16, 2025



As robotic technology rapidly develops, robots are being employed in an increasing number of fields. However, due to the complexity of deployment environments or the prevalence of ambiguous-condition objects, the practical application of robotics still faces many challenges, leading to frequent errors. Traditional methods and some LLM-based approaches, although improved, still require substantial human intervention and struggle with autonomous error correction in complex scenarios.In this work, we propose RoboReflect, a novel framework leveraging large vision-language models (LVLMs) to enable self-reflection and autonomous error correction in robotic grasping tasks. RoboReflect allows robots to automatically adjust their strategies based on unsuccessful attempts until successful execution is achieved.The corrected strategies are saved in a memory for future task reference.We evaluate RoboReflect through extensive testing on eight common objects prone to ambiguous conditions of three categories.Our results demonstrate that RoboReflect not only outperforms existing grasp pose estimation methods like AnyGrasp and high-level action planning techniques using GPT-4V but also significantly enhances the robot's ability to adapt and correct errors independently. These findings underscore the critical importance of autonomous selfreflection in robotic systems while effectively addressing the challenges posed by ambiguous environments.
A Self-guided Multimodal Approach to Enhancing Graph Representation Learning for Alzheimer's Diseases
Dec 09, 2024



Graph neural networks (GNNs) are powerful machine learning models designed to handle irregularly structured data. However, their generic design often proves inadequate for analyzing brain connectomes in Alzheimer's Disease (AD), highlighting the need to incorporate domain knowledge for optimal performance. Infusing AD-related knowledge into GNNs is a complicated task. Existing methods typically rely on collaboration between computer scientists and domain experts, which can be both time-intensive and resource-demanding. To address these limitations, this paper presents a novel self-guided, knowledge-infused multimodal GNN that autonomously incorporates domain knowledge into the model development process. Our approach conceptualizes domain knowledge as natural language and introduces a specialized multimodal GNN capable of leveraging this uncurated knowledge to guide the learning process of the GNN, such that it can improve the model performance and strengthen the interpretability of the predictions. To evaluate our framework, we curated a comprehensive dataset of recent peer-reviewed papers on AD and integrated it with multiple real-world AD datasets. Experimental results demonstrate the ability of our method to extract relevant domain knowledge, provide graph-based explanations for AD diagnosis, and improve the overall performance of the GNN. This approach provides a more scalable and efficient alternative to inject domain knowledge for AD compared with the manual design from the domain expert, advancing both prediction accuracy and interpretability in AD diagnosis.
IMUVIE: Pickup Timeline Action Localization via Motion Movies
Nov 19, 2024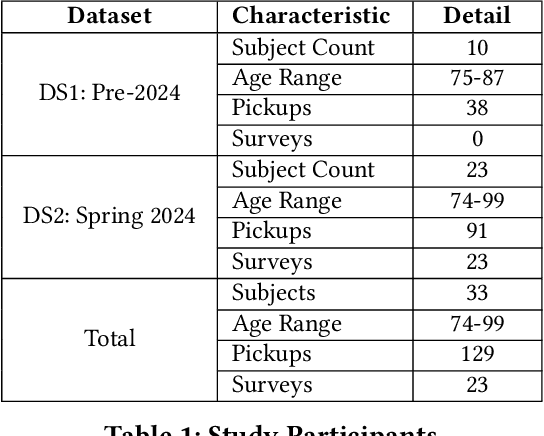



Falls among seniors due to difficulties with tasks such as picking up objects pose significant health and safety risks, impacting quality of life and independence. Reliable, accessible assessment tools are critical for early intervention but often require costly clinic-based equipment and trained personnel, limiting their use in daily life. Existing wearable-based pickup measurement solutions address some needs but face limitations in generalizability. We present IMUVIE, a wearable system that uses motion movies and a machine-learning model to automatically detect and measure pickup events, providing a practical solution for frequent monitoring. IMUVIE's design principles-data normalization, occlusion handling, and streamlined visuals-enhance model performance and are adaptable to tasks beyond pickup classification. In rigorous leave one subject out cross validation evaluations, IMUVIE achieves exceptional window level localization accuracy of 91-92% for pickup action classification on 256,291 motion movie frame candidates while maintaining an event level recall of 97% when evaluated on 129 pickup events. IMUVIE has strong generalization and performs well on unseen subjects. In an interview survey, IMUVIE demonstrated strong user interest and trust, with ease of use identified as the most critical factor for adoption. IMUVIE offers a practical, at-home solution for fall risk assessment, facilitating early detection of movement deterioration, and supporting safer, independent living for seniors.